
機械学習を解釈する#02 PD

前回(1年以上前…)は機械学習を解釈する手法の1つであるParmutation Feature Importance(PFI)について説明しました。
今回は、特徴量と予測値の関係を知る手法であるPartial Dependence(PD)について紹介します!
Permutation Feature Importance(PFI)の限界
Permutation Feature Importance(以下、PFI)は、任意の学習済みモデルに対して、ある特徴量の値をシャッフルした場合に精度がどれくらい落ちるのかを見ることで、その特徴量の重要度を知るという手法でした。
この手法は、モデルの振る舞いの概観をつかむ用途としては適していますが、一方で各特徴量とモデルの予測値の関係を知ることはできません。具体的には、ある特徴量の値が大きくなるとモデルの予測値は大きくなるのかまたは小さくなるのかであったり、ある特徴量と予測値の関係は線形なのか非線形なのかなどです。
Partial Dependence(PD)とは
PFIの限界として【特徴量と予測値の関係を知ることができない】とありましたが、これを解決してくれるのがPartial Dependence(以下、PD)です。
PDを簡単に説明すると、興味のある特徴量の値を取り得る範囲の値に置き換えながら予測をしていき、その平均値を計算する手法です。文章で説明してもよくわからないのでイメージを記載します。

イメージを見ていただくと何となく理解できるかと思います。先ほどの説明をイメージ図に合わせて言うと、興味のある特徴量(X_0)の値を取り得る範囲(1~3)の値に置き換え(全部1の時、全部2の時、全部3の時)ながら予測をしていき、その平均値(3行の予測値の平均値)を計算する手法です。
PDもPFI同様予測した結果にしか興味がないので、どんな機械学習モデルにも適用できます。
具体例として、アイスの売上を予測するモデルを考えてみましょう。
3つの特徴量(気温、湿度、昨日の売上)から今日の売上を予測するとします。この時、気温と売上の関係を知りたい場合以下の手順で計算します。
①:3つの特徴量を用いてモデルを学習させておく。
②:テストデータを準備し、気温の取り得る値(例えば0~35)を全テストデータに順番に置き換えていき予測の平均を出す
③各気温に対する予測の平均値(ここでは0~35の36パターン)をプロットし、関係性について可視化する(下図が可視化のイメージ)
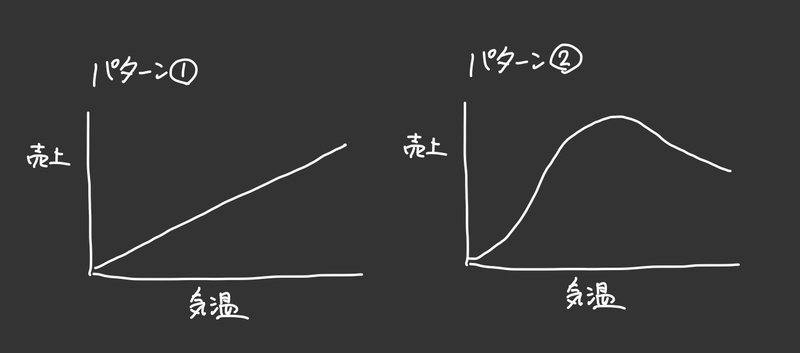
これはあくまでイメージですが、具体例で考えたとき上記のようなアウトプットが期待できます。パターン①のように気温が上がれば売上も常に上がっていくかもしれませんし、パターン②のように気温がある値を超えると売上が下がっていくかもしれません。
このように、気温が変化すると売上がどう変化するかの関係を可視化できるというのはモデルを解釈する上で嬉しい点です。
PDの実装
では、実際にPDを実装してみましょう。前回同様、scikit-learnに用意されてあるボストン市の住宅価格データセットを使用します。データセットの詳細についてはscikit-learnに付属しているデータセットを参照してください。モデルはランダムフォレストを使います。
# ライブラリのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.inspection import partial_dependence
import warnings
warnings.filterwarnings('ignore')boston = load_boston()
df = pd.concat([pd.DataFrame(data=boston.data, columns=boston.feature_names), pd.Series(data=boston.target, name='y')], axis=1)
# 学習用データとテスト用データを作成
X = df[df.columns[df.columns != 'y']]
y = df['y']
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# ベースラインモデルの作成
rf = RandomForestRegressor(random_state=0).fit(X_train, y_train)
from sklearn.metrics import r2_score # 今回も決定係数を計算しています(特に意味はない)
r2_score(y_test, rf.predict(X_test)) # 0.7952684623500126モデルの学習が終わったので、PDを計算します
今回は特徴量の内【RM(平均的な部屋の数)】とy(住宅価格)の関係について調べます。
# PDを計算
pdp = partial_dependence(
estimator=rf, # 学習済みのモデル
X=X_test, # PDを計算するデータ
features=['RM'], # PDを計算したい特徴量
kind='average' # PDの場合は'average'を指定
)
pdp
PDを計算すると、averageとvaluesがキーの辞書が出力されます。
・average:予測値の平均
・values:特徴量の値
この辞書のaverageとvaluesをプロットすれば、関係性が可視化できそうです。
plt.figure(figsize=(10, 4))
# pdpの辞書の値はリストの中にarrayが入っているのでpdp['key'][0]のように要素にアクセスする必要がある
plt.plot(pdp['values'][0], pdp['average'][0])
plt.title('平均的な部屋の数(RM)のPartial Dependence Plot')
plt.xlabel('RM')
plt.ylabel('Partial Dependence')
plt.grid(alpha=.3)
plt.show()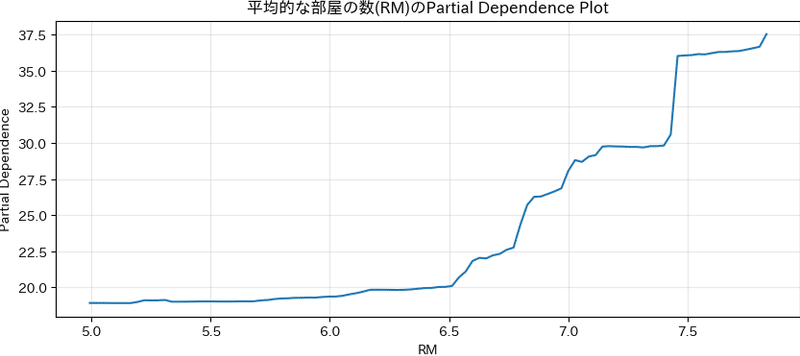
結果を見てみると平均的な部屋数RMが増加すると予測値の平均が大きくなることがわかります。特に6部屋以上になったあたりから予測値の増加に影響するという非線形な関係が見て取れます。部屋の数が増えれば住宅価格が高いというのは直感的にも合っています。
念のため他の特徴量(NOx)についても見てみます。
# PDを計算
pdp = partial_dependence(
estimator=rf, # 学習済みのモデル
X=X_test, # PDを計算するデータ
features=['NOX'], # PDを計算したい特徴量
kind='average' # PDの場合は'average'を指定
)
plt.figure(figsize=(10, 4))
plt.plot(pdp['values'][0], pdp['average'][0])
plt.title('NOxの濃度(NOX)のPartial Dependence Plot')
plt.xlabel('NOX')
plt.ylabel('Partial Dependence')
plt.grid(alpha=.3)
plt.show()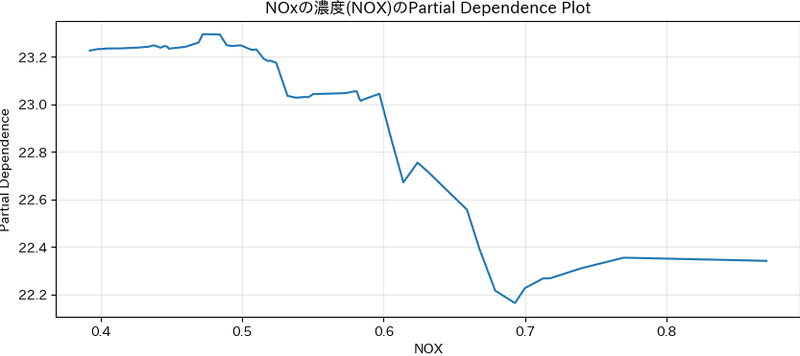
こちらの結果では、NOx(窒素酸化物)が増えると予測値の平均は下がる傾向にあります。特にNOxが0.7を超えると予測値の値が横ばいになるような関係であることも分かります。確かに、NOxの濃度が高い地域は住宅価格が低いだろうし、NOxの濃度が高すぎるからといって住宅価格が下がり続ける訳でもないというのもうなづけます。
まとめ
PDを用いることで、任意のブラックボックスモデルに対して特徴量と予測値の平均的な関係を把握することができました。具体的には、特徴量の値が大きくなったときにモデルの予測値は大きくなるのか、その関係は非線形なのかといったことが把握可能です。
一方でPDはあくまで平均的な関係に注目しているため、一つ一つのデータに対して特徴量と予測値の関係が異なっていてもそれを考慮できません。今回のデータセットでいうと、部屋の数が増えたからといって常に住宅価格が増えるわけではないということです(部屋が多くても、NOxの濃度が高ければ住宅価格は下がるかも知れません。)。このように、データごとに異なる特徴や交互作用などまでは表現できないことには注意しましょう。
最後に、PDの利点と注意点を記載して終わりにしたいと思います。
利点
・任意のブラックボックスモデルに対して、適用可能
・PDを確認することで、各特徴量がモデルの予測値にどのような影響を与えているのか確認できる
・任意の特徴量からモデルを作成しているため、特徴量と目的変数の一対一の関係ではなく他の特徴量の影響を考慮することができる(ただし、交互作用までは考慮できない)
注意点
・あくまで特徴量とモデルの予測値の関係を表しているに過ぎないので、特徴量と目的変数の関係を正しく表現できているとは限らない
・特徴量と予測値の平均的な関係を表現しているに過ぎないので、データごとに異なる特徴があったとしてもその影響は無視している
この記事が気に入ったらサポートをしてみませんか?