
教師あり機械学習を使ってBTC価格を予想してみる④

こんにちはalumiです。もう第4回です。前回はこちら。
前回のあらすじ
20本後の価格の上下を予測するように変更したら、1分足を使ったときの認識率が大きく上がった!
ちゃぶ台返し回
今回はまず、第3回目までの大きな勘違いの修正から始めていきます。前回もスケーリングについての勘違いがあり、「またか」と思われるかもしれません。私自身最初に言った通り試行錯誤しながら進めている実験noteですのでこれからもこういうことが多々あるかもしれませんが見守っていてくれるとありがたいです。最終的に必要な流れだけを簡潔にまとめたnoteを改めて書こうと思っています。
今回大きく変える部分は「学習データとテストデータの選び方」です。順を追って説明します。
時系列データであることの考察
実用化を意識したときにBTC価格が時系列データであることの意味をふと考えてみました。下の二つを考えます。
①データ同士の影響が一方向的であること
ある2つのデータa,bを取り出したとして、時系列的にbはaより後のデータだったとします。このとき、aがbに影響を与えている可能性はありますがbがaに影響を与えている可能性はありません。未来によって過去は変わらないからです。
②データの関連度に差があるのでは?という仮説
つまり、「1年前の値動きと今の値動きの関連度」と「1日前の値動きと今の値動きの関連度」は、後者の方が高いのではないかという意味です。市場の変化が根拠です。もしこの仮説が正しいとすれば期間を長くして学習に使うデータを多くすればするほどノイズも多く紛れ込んで認識率は下がる可能性があります。一方データを少なくしすぎても十分な学習は行えないでしょう。どこかで極大となるはずです。
①について考えると学習データとテストデータの選び方を見直す必要が見えてきます。
今までは過去6000件のデータを対して正解ラベル比率を保ちつつランダムに分けてきましたが、時系列的に新しいデータをテストに選び、過去のデータから未来データを予測するという形に近づける方が実応用につながるはずです(というか、今までの分け方は正直実用的な価値は0に等しいレベルでした)。また、半分ずつに分ける必要はなく、ある程度の数が担保されていればテストデータは少なくていいと思います。実際にbotの戦略に応用する際は最新1件が予測できれば良いわけですから。
下に簡単にまとめました。

しかしこれだけではまだ不十分でした。実際にbotで使う際はテスト用データの正解ラベルはわかっていません。つまり下のような状況が正しいわけです。
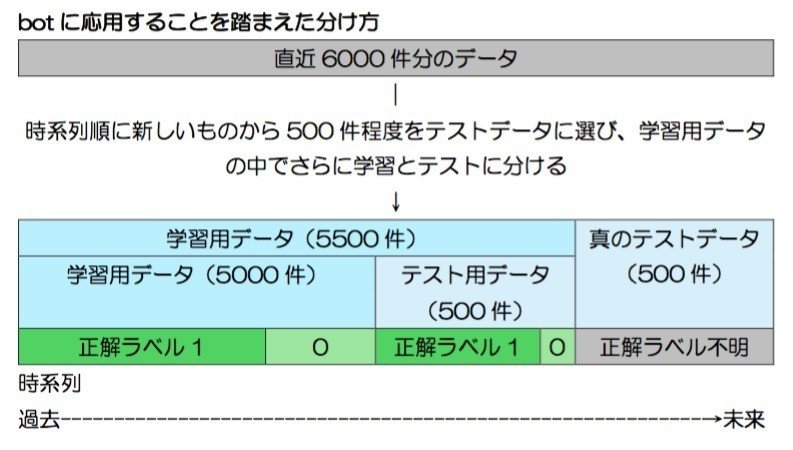
真のテストデータはパラメータ調整には全く関与させてはいけません。つまり、「過去5000件のデータで学習、次の500件でテスト」のサイクルを繰り返し、最も成績が良かったパラメータを用いて真のテストデータ500件に挑むのです。
どうしても時間的ギャップが生まれるので認識率は悪くなることが予想されます。しかし第3回までのやり方ではいつまでたってもbotには応用できないと気付いたのでこのタイミングで上の図のような分け方を採用して、成績をテストしていくように変えます。
ここで第3回の最後のテストを新しい分け方を使って再実施してみます。分け方が一意なので標準偏差はありません。結果は以下。

あれれ、成績上がりましたね。思いの外直近の6000件にはぴったりはまった分け方だったようです。
しかし、本当に大事なのは安定性です。過去の別の期間を選んで繰り返し同じテストを行うと成績は5割を切ることも多くあり、それを20回ほど繰り返した平均は結局51%程度でした。やはりコイントス状態を抜け出せていません。これを高められるよう努力していきます。
次に②を考えていきます。過去6000件という数値はそもそも多すぎる(あるいは少なすぎる)可能性があります。そこで学習データの中のテスト用データ、真のテストデータは500件で一定にし、学習データの中の学習用データ(上の図では5000件)の値を変えていきます。
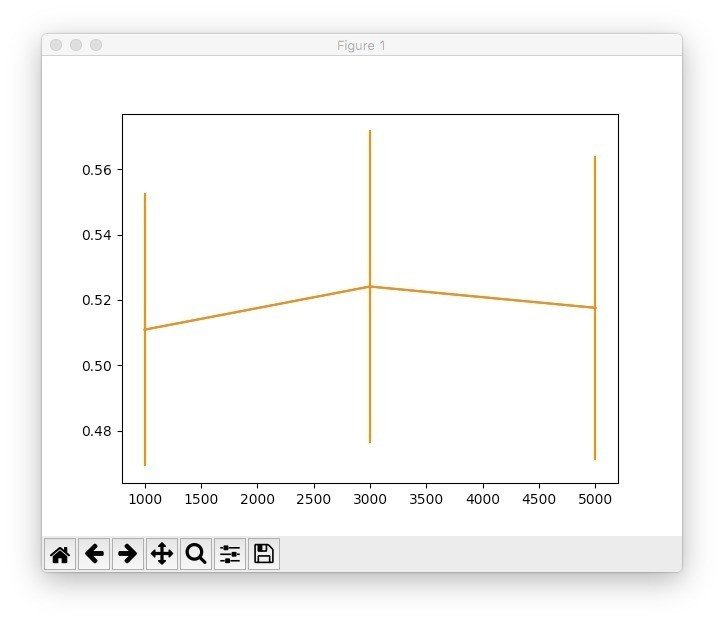
予想とは違ってあまり変わらないです。5000件のときはさっき言った通り平均51%程度ですが、値を変えても変わりませんでした。そもそも51%という数値自体が相当悪い成績なためどんぐりの背比べということでしょう。
その後の試行錯誤の結果
その後試行錯誤を繰り返したので概要だけ説明します。(けっこういろいろ頑張ったんですが、複雑なのでnoteに詳しく書くのは省略します)
①学習データを使ってk,lを[5,10,20,30]の中で毎回調整しつつ、グリッドサーチでロジスティック回帰のパラメータCの調整も行い、真のテストを行うアルゴリズムにする
②偶然見つけたパラメータ「学習データ2100件(そのうち学習用2000件、テスト用100件)、真のテストデータ1000件」で過去の別の期間を選んで繰り返しテストを行うと、良い時で57.2+/-8.6%という結果が得られた。
標準偏差は相変わらずかなり大きいですが、平均51%から考えればかなりの進歩だと思います。(データを恣意的に選んでしまったので参考結果です、次回もっとちゃんとやります)
なぜ分け方を変えるとこんなに認識率が変わるかというと、おそらくランダムに分けていた時は連続した2つのデータが学習とテストに一つずつ回されることがあったからだと思います。連続したデータは当然特徴量がとても似ているため、学習してテストに正解を出すことが容易になります。時系列データは連続したデータをできるだけ学習とテストに分けないことが大事です。初心者ゆえの遠回りでした。反省。
テクニカル指標を特徴量に加える
遠回りをしてしまいましたが、本筋に戻ってテクニカル指標を特徴量に加えて精度を高めていきましょう。ここからは一つ上でたどり着いたコードを中心に分析していきます。前回は指標を加えられるだけ加えていきましたが、今回は指標の期間パラメータも含め慎重にテストしていきます。
・・・・・・・・・とここまで書いていざテストしようとするも、異常に計算量が増え時間がかかり過ぎてしまったので一旦保留にします。途中からパソコンが熱くなって4GBメモリ虐待につながってしまうので。
現状のまとめ
というわけでいったん今回のまとめです。
読んでいくださっているみなさんにとっては二転も三転もするまとまりのない内容になってしまっていることを申し訳なく思います。
ひとまず現状をおさらいすると、図のようになっています。

真のテストデータは未来の価格を意味します。つまりこれに対する認識率を上げることが最大の目的となりますが、現状不安定な結果となっています。せめて50%が1σ区間外に出るように改善していきたいところです。
テクニカルの計算が非常に時間がかかり困難そうなのでしばらくは別のアプローチをかけていきます。次回はまず識別器にロジスティック回帰以外を用いてみたいと思います。また時系列データ分析に有効な「差分を取る」という手法も試してみます。
同時進行でディープラーニングのライブラリも勉強しているのでいずれは多層パーセプトロンなども応用できたらと思っています。
一気に方針転換回となりごちゃごちゃしてしまったのにもかかわらず最後まで読んでくださった方、ありがとうございます!また次回お会いしましょう。
記録用コード
import requests
import numpy as np
import pandas as pd
import json
period = 60 # 時間足(秒単位)
k_range = [10,20] # kの値の候補
l_range = [10,20] # lの値の候補
m_range = np.random.randint(30000,40000,50) # 何本分過去に遡ってテストするか
n_range = [2000] # 学習データの中の学習データの数
mean = []
std = []
for n in n_range:
best_score = []
cnt = 0
for m in m_range:
# 蓄積データの読み込み
a = open('data.json',"r")
response = json.load(a)
a.close()
response['result'][str(period)] = response['result'][str(period)][-m:-m+6000]
train_test_score = 0
best = 0
for k in k_range:
for l in l_range:
x_data = []
y_data = []
# データダウンロード
for i in range(len(response['result'][str(period)])-k-l):
# xの要素
arr = np.array(response['result'][str(period)][i:i+k])
arr = arr[:,1:5].ravel()
arr = (arr - arr.min())/(arr.max()-arr.min())-0.5
x_data.append(arr)
# yの要素
if response['result'][str(period)][i+k+l][4] - response['result'][str(period)][i+k+1][1] > 0:
target = 1
else:
target = 0
y_data.append(target)
# 学習データと真のテストデータに分ける
tr = n
ts = 100
x = np.array(x_data)
x_train = x[-tr-ts:-ts-l]
x_test = x[-ts:]
y = np.array(y_data)
y_train = y[-tr-ts:-ts-l]
y_test = y[-ts:]
# 識別器の選択
from sklearn import linear_model
clf = linear_model.LogisticRegression()
tt = 1000
x_train,x_train_test = x_train[:-tt],x_train[-tt:]
y_train,y_train_test = y_train[:-tt],y_train[-tt:]
# スケーリング
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc.fit(x_train)
x_train = sc.transform(x_train)
x_train_test = sc.transform(x_train_test)
x_test = sc.transform(x_test)
# グリッドサーチ_LR
from sklearn.model_selection import GridSearchCV
param = {'C':[1e-3,1e-2,1,1e2,1e3]}
gs = GridSearchCV(clf,param)
gs.fit(x_train,y_train)
clf = gs.best_estimator_
# 学習とテスト
train_test_score = clf.score(x_train_test,y_train_test)
test_score = clf.score(x_test,y_test)
if train_test_score > best:
best = train_test_score
best_test_score = test_score
best_l = l
best_k = k
best_score.append(best_test_score)
cnt += 1
print("{0:.1f}% done".format(cnt/len(m_range)*100))
print("best param:k={0},l={1}".format(best_k,best_l))
print("training:{0},test:{1},diff:{2:.1f}".format(best*100,best_test_score*100,(best_test_score-best)*100))
print(best_score)
mean.append(np.array(best_score).mean())
std.append(np.array(best_score).std())
print("{0:.2f}+/-{1:.2f}%".format(np.array(best_score).mean()*100,np.array(best_score).std()*100))
この記事が気に入ったらサポートをしてみませんか?