
筑波大学オープンコースウェア(OCW)の機械学習の"note"をとった - 重回帰 (1)

用語メモ
Bag of Words
文章中に含まれる単語で one-hot-vector(1-of-k表現) のベクトルを作り特徴量とする方法。
頻度は考えずに単語が出現したかどうかを特徴量とする。
例えば12,000語含む辞書が存在し、その辞書内の単語の出現有無で文章を one-hot-vector にするならば、どんな文章も12,000次元の特徴量に変換できる。
Stop word
日本語で「の」とか「は」とか(多くの場合は助詞)はどんな文章にも現れるため特徴量としては使えない言葉。
多くの場合文章の特徴量抽出において除外される。
TF-IDF
Bag-of-words ではベクトルの要素が”0″, “1”(有無)の値しか取らないが、TF-IDF では出現頻度や特徴的な言葉の出現有無を数値として特徴量に反映される。
TF(term freq.) と IDF(inv. oc. feq.) という値をそれぞれ計算して掛け合わせた値が TF-IDF となるのだが、計算式はググれば出来てくるので割愛。
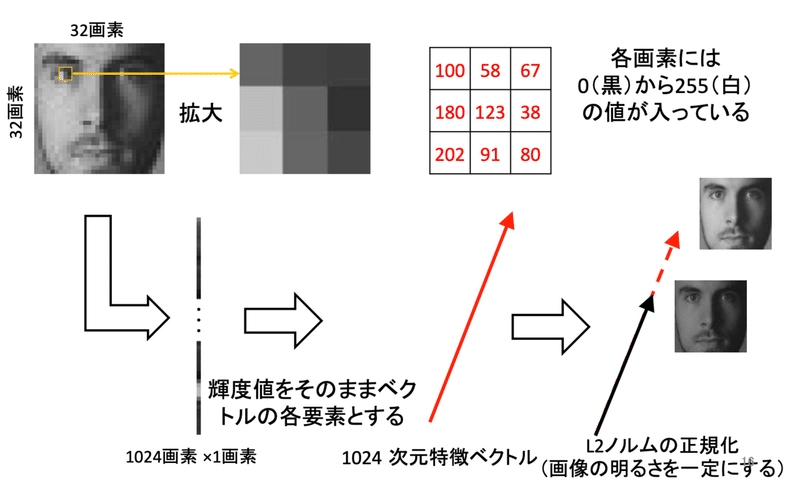
輝度値特徴
アピアランスベース画像認識と呼ばれる。顔認識などで使われる特徴量。写っているものをそのまま(画像の見え方をそのまま)用いる方法≒補正が必要ない。
例えば顔認識では認証されようとして写るので、顔が遠くに写ったり斜めを向いていたりというのを考慮する必要はない。
ただし照度などの条件に左右されない様な特徴量の作り方をする。
具体的な特徴量としては画像の輝度値(0~255)を用いる。
ただし、明るかったり暗かったりで輝度値は変わるので、輝度値にベクトルの長さが一定になる様な正規化をする。(方向だけが問題となる様にする。)
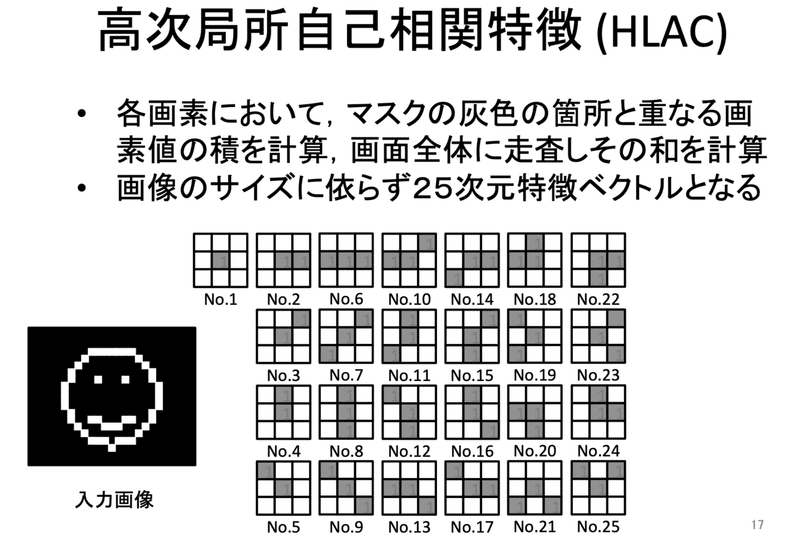
高次局所自己相関特徴(HLAC)
角度や位置などによって認識精度が左右されたくないような特徴量とする。
詳しくは第4回の授業参照。
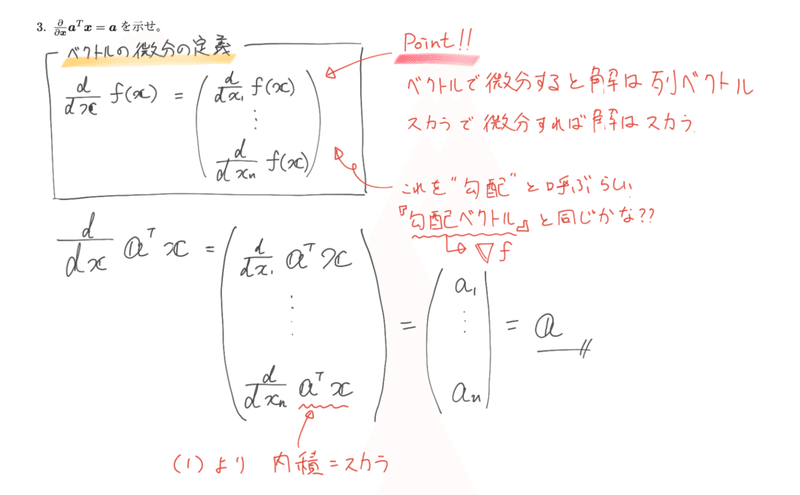
引用(講義ポイント)メモ
最急降下法で最適解を求める確実な方法はない。
なので何回もやる。最急降下法の初期値はランダムに決定するため、何回もやることで最適値に近い座標に初期値が設定されれば最適解が求まる。
ただし、何回やればよいという確実な回数はないため、あくまでも「何回かされば最適解が求まるだろう」という可能性の話。
実際にはこんな単純な話ではなく問題に対してある程度仮定をおかないと最適解に近づくことは出来ず、結論的には多項式時間で最適解を求めることは現実的には不可能。

覚えるべきは転置ベクトルと列ベクトルの積は内積。機械学習で使う内積表現(スカラ)に慣れる。

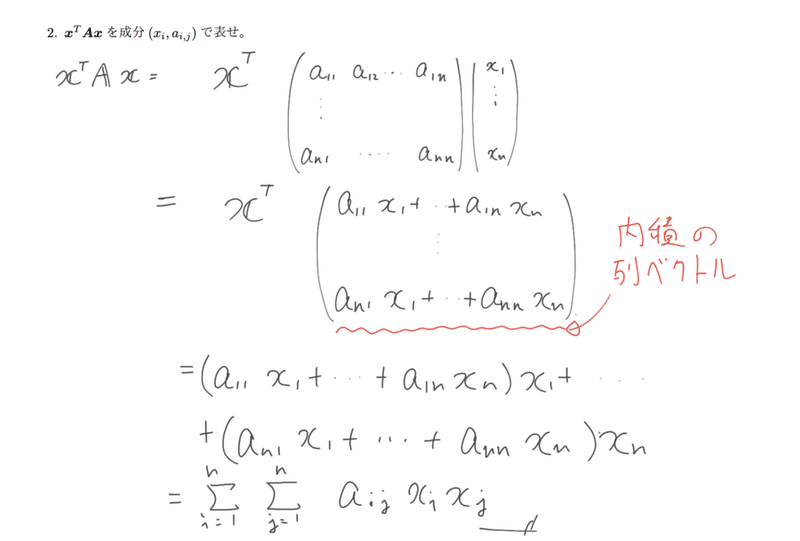
ベクトルの微分定義を覚える。

データの前処理
・欠損値への対応 ··· 欠損値を含むサンプルを除去する。平均値・中央値で補完する など
・外れ値への対応 ··· 極端な外れのデータは除外する(測定ミスの可能性)
・スケーリング(標準化) ··· 各特徴が平均が0,標準偏差1になるようにする。(最大値が1、最小値が0になるようにするといった方法もあり) => なぜか? => ある特徴量は 0~100 の値をとり、別の特徴量は 0~1 の値を取る。それぞれの特徴量の重み𝑤はどちらも0.3だった。モデルに対する影響はどちらの特徴も一緒か?答えはNo(𝑥の定義域が違うので)。スケーリングとは(𝑥、すなわち各特徴量の定義域を(平均0, 標準偏差1にすることで)揃えて等価に評価できるようにする処理。
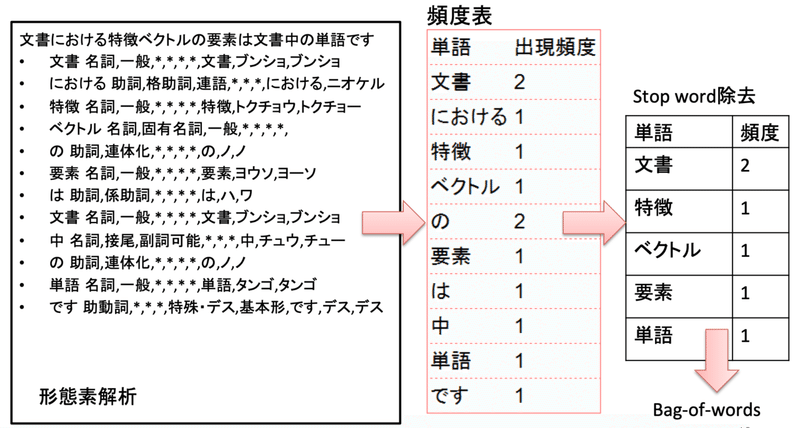
日本語の文章の特徴量化は英語ほど単純ではない。
単語間の区切りが明確でないので形態素解析をして単語にわけ、そこから Stop word除去を行い、それを Bag-of-words でベクトル化するなど。
画像の特徴ベクトル化。
必要な情報を残し不要な情報を削除する。
・顔認識 ··· 輝度値特徴
有効:顔の見え方そのもの
不要:画像の明るさ(≒証明の影響)
・物体認識 ··· 高次局所自己相関特徴
有効:見え方、色、形状、個数
不要:物体の位置(左上に物体があろうが中央にあろうが認識して欲しい)
この記事が気に入ったらサポートをしてみませんか?