
今更聞けないLLM解説まとめ④事前学習のスケール

どうも、それなニキです。
今回も引き続き取り組んでいきましょう。
1.LLMのスケールについて
今回はLLMのスケール(大規模化)について扱います。
第三回を見ていただいた方には、LLMの性能(Lossの小ささ)はAttention機構やFeed Forward内のパラメータによって決まってくる、ということはご理解いただけると思います。
そこから、たくさん学習すればパラメータがより最適化されて、性能が向上するだろうなぁ、という想像はできるでしょう。
では、実際のところより具体的にはどのような挙動を示すのか、という部分が今回の主題です。
これが分かると、なぜ今LLM開発において海外勢、特にOpenAI(Microsoft出資)やGoogleが圧倒的なアドバンテージを持っているかが分かります。
現実は非情也…
Ⅰスケール則
このスケール(大規模化)については既に大量の実験が行われており、大まかに以下の3つの指標の増大に対してLossが減少することが見出されています。
計算資源(C)
データセットサイズ(D)
パラメータ数(N)

(この指標、実は第一回でも紹介しています)
このうち、DとNについては「ま、そりゃそうか」程度に思ってもらえば良いですが、問題はCのグラフです。
何か上から降ってきているようなグラフになっているのが分かります。
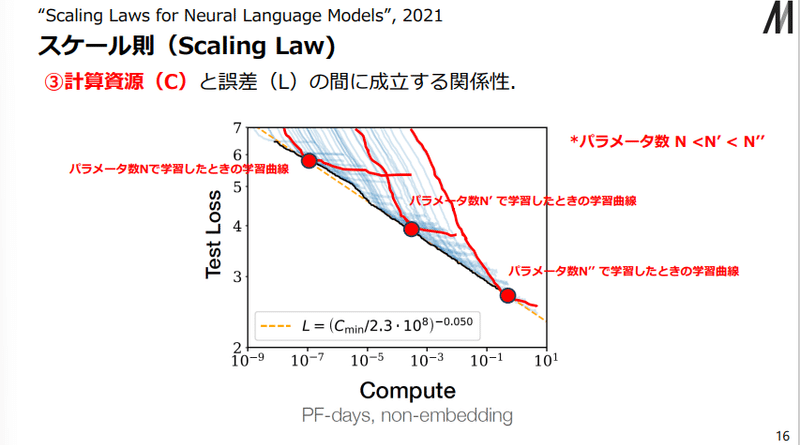
このグラフは、横軸が計算資源、すなわち「どれくらいサーバーを使ったか」という量になっていて、青い線一本一本は「あるパラメータ数のモデルを事前学習させた時の学習曲線」となります。
一本一本に注目してみると、橙色の点線のあたりでポキッと折れている、すなわちそれ以降はあまり性能が向上していないことが分かります。
このグラフの使い方ですが、例えばあなたが新しいLLMを開発しようと思い、0.002PF-daysの計算資源をGoogle Cloudで買ったとしましょう。
その場合、最も性能が高いLLMを開発するには、計算資源のスケール則の表を見て、0.002PF-daysの部分に線を引くと

0.002PF-daysで最も性能がいいLLMはパラメータ数がN'であることが分かります。
松尾研の資料の言葉を直接借りるなら、
つまり, この直線は「任意の計算資源量が与えられた時に, その計算資源内で最良のパフォーマンスを発揮するパラメータサイズのモデルで到達可能なLoss値(最適点)の集合」を意味する.
ということです。
経験則ではありますが、方程式化も一応されていて、
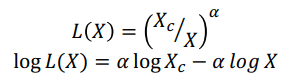

となります。
よく見るとグラフは全て片対数になっていて、Lossは既に対数の指標なので、実質的に両対数グラフとなり、この式が成立していることが確認できます。
Ⅱ More is Different
実はLLMをスケールした際の効用はこれだけではありません。
タスクにはよりますが、ある特定のモデルサイズ(ここでは計算資源C)から突然性能が上がることが報告されています。
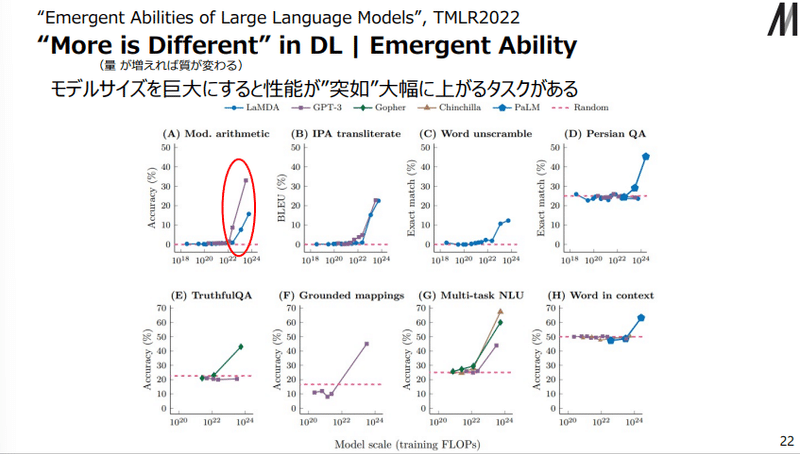
グラフを見てもらうと一目瞭然だと思います。
(これらは縦軸が正答率になっているため片対数グラフであり、本当に突然能力が上がっているのかについては松尾研の資料でも批判がありました。)
加えて、検証データの正解率が突然高まる現象も報告されています(Grokking)。
Ⅲスケール則の範囲と効用
ここまでLLMのスケール則について見てきましたが、実は他の機械学習を利用するドメイン(domain,領域)でもこのスケール則が成立することが判明しています。
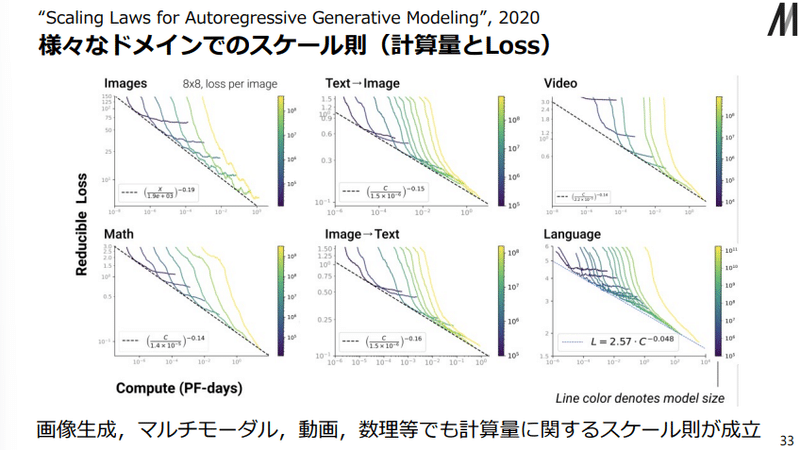
このスケール則の活用方法はいくつかあります。
複数のモデル構造(Transformerを使うのか、他の構造を作るのか、層数はどうするのか)について、しっかりと比較できる
性能が依存している指標が判明しているので、それぞれについて変化させて比較すればよい
計算量に制約を受ける現実のLLM開発において、適切なパラメータ選択ができ、投資リスクが軽減される
さっき見た通り
2.スケールの課題と解決策
さて、スケールすることが良いことだというのは十分伝わったかと思いますが、それだけなら無尽蔵にスケールしていけば完璧で究極のAIを作ることができるはずです。

…まあ、そんなはずもなく、スケールを行っていく上では様々な問題にぶち当たります。
N(パラメータ数),C(計算資源)
モデルサイズの増加につれてコストが増大
具体的には系列長(Attention機構のQueryベクトル、Keyベクトルの長さ?)の2乗の計算量、およびそれを扱えるメモリ(RAM)が必要!!
D(データセット)
データはそもそも量が足りない
データが増えるスピードに対して、必要となるデータの量の増大速度が速すぎて、2024年(今年!?)頃にはデータが枯渇すると予測されている
…というのは確か英語の話で、日本語はデータ総量も圧倒的に小さいのでもっとヤバい
これらの問題に対して、様々な解決策が研究されてきているので、まとめていきます。
Ⅰ N(パラメータ数)関係の問題解決
まずはパラメータ数についてです。
パラメータ数増大の問題は計算コストの増大であるため、以下のような解決の方向性が模索されています。
Self-Attentionそのものの計算/メモリ効率の改善
計算コストを肥大化させずにモデルのパラメータを増やす方法の模索
そもそもSelf-Attentionに依存しない学習法を探す
1番は、Attention機構で行われるすべてのトークン間の計算の一部を端折る「Sparse Attention」として、「Sparse Transformer」と「Big Bird」が開発されています。
他にも、Attention機構における行列計算に近似を導入して効率化する「Perfomer」や、行列計算と無関係な部分に注目してメモリアクセスを改善した「FlashAttention」などがあります。
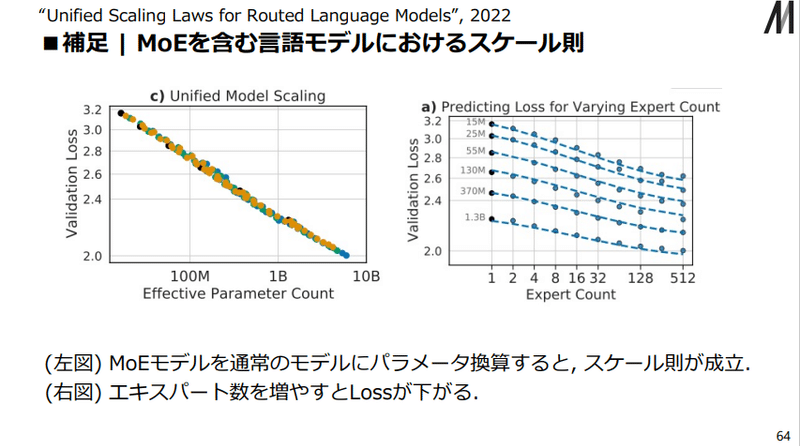
2番は、複数個のエキスパート(ニューラルネット)を用意して、入力値に応じて一部のエキスパートにだけ値を渡すことで、学習時のパラメータ使用を抑えて計算量を低下させる混合エキスパート(MoE)というシステムが開発されています。
実はGPT-4はこれを用いていると噂されているそうです(GPT-4は本体が非公開なので真相は不明)。
無論、そのためには、大量のエキスパートによるネットワークに加え、それを制御するゲーティングネットワークが必要になり、構造がさらに複雑化するのは言うまでもありません()
詳しくは説明しませんが、スケール則なども問題なく成立しており、かなり見込みのある方法ではあります。

3番は…まあ要するにSelf-Attention以外の構造が色々提案されているわけです。
羅列だけしておくと、過去の時間ステップすべてにわたる加重平均で計算を完結させる「AFT(Attention Free Transfomer)」、RNNとTransfomerの利点を組み合わせる「RWKV」、まったく別の方法論でTransfomerを超えるスケーリング効果を叩き出した「RetNet」、状態空間モデルというアーキテクチャを利用した「S4」などがあります。
…あるんですけど、全部解説してると第三回レベルの投稿をもう4回しないといけないので、紹介に留めておきます。すみません…
これらのアーキテクチャがTransfomerにとって代わるかですが、すべて1B~10Bのオーダーでしか検証されたことがなく、未知数としか言えません。
Ⅱ C(計算量)関係の問題解決
さて、続いては計算量です。
計算量の問題解決の方向性は以下の通りです。
訓練において複数のGPUを効率的に利用する
モデルの軽量化を行う
1番は、基本的に「並列化」によって実現されます。
モデル全体をそれぞれのGPUに複製して計算させる「データ並列」と、モデルそのものを分割(パイプライン並列)したり、Attention機構などで使う巨大な行列を分割(テンソル並列)して複数のGPUに分担させる「モデル並列」があります。
また、データ並列型でありながら、学習パラメータを重複の無いように各GPUに分け、必要な時にGPU同士で通信して必要パラメータを一時的に収集するという「ZeRO」が開発されており、ZeROとパイプライン並列、テンソル並列を組み合わせた「3D Parallelism」が現状最も理想的なフレームワークになっています。
2番は、基本的に「量子化」によって実現されます。
これはStable Diffusionでもよく出てくる用語なのでお馴染みの方もいると思います。
量子化とは、パラメータの数値のデータタイプを浮動小数点(Float型)から整数(Int型)に変換して演算処理を行うことで必要メモリ量を削減する方法です。めっちゃ直接的やな()
もちろん、適当にやってしまうと容易に性能低下を引き起こすので、注意が必要です。
性能劣化をほとんど引き起こさない量子化として「LLM.int8()」が資料では紹介されていますが、これはパラメータの大部分を8bitで表し、外れ値だけを16bitで表す方法です。
Ⅲ D(データセット)関係の問題解決
最後はデータセットです。
ここは先ほどの2つとは毛色が違い、LLM外部の問題になってきます。
というか、データサイエンス領域の話になります。
そのため、解決の方向性は以下のようになります。
さらに大きいデータセットを探索・整備する
少量の高品質なデータセット用意
1番は、データの前処理段階を工夫することでWEB上のデータをより広く収集できるようにして、データベースの規模を拡張することが主要な命題になっています。
具体的には、
URL filtering
Text extraction
Language identification
Repetition removal
Document-wise filtering
Line-wise corrections
Fuzzy deduplication
Exact deduplication
の8工程でデータを絞り込みます。
この一連のパイプラインでCommonCrawl(一般ウェブサイトのテキストデータ)のうち約90%が取り除かれるようです。
めっちゃ減るやん()
また、最適計算配分によってN(パラメータ数)とD(データセット)を決めることも性能向上につながることがあり、実例として「Chinchilla」というLLMが挙げられます。
2番は、「データ刈り込み」によって達成されます。
これは、データセットにおいて、学習にとって重要でないサンプルを取り除くことです。
何だか1番の前処理に似ていますが、こちらは最低限フィルターを突破してきたデータに対して、さらにその内容から選別を行うというものです。
なんとこのデータ刈り込み、スケール則を打ち破って、より効率的な学習が可能であることが確認されています。
ただ、その分データが小さくなってスケールそのものが小さくなりますから、トレードオフがないわけではありません。
松尾研の資料ではLLMではなく画像処理についての研究が紹介されていますが、画像処理においては、学習データが少ない場合は分類難易度の低いサンプルを多く残し、学習データが多い場合は分類難易度の高いサンプルを多く残すことで性能の最大化を図るようです。
また、LLMにおいてもD4と呼ばれる刈り込み手法で学習を高速化して精度を向上させることができた事例があるようです。
まとめ
今回は文章があんまりよく纏まりませんでした…再走案件かもしれません
松尾研資料のまとめページを一応貼っておきます。

余談
記事を書き上げる合間に、気分転換がてら遊戯王をするときに使うプレイマットをフリマで探しています。
プレイマット業界はStable Diffusion登場によって非常に大きな影響を受けている業界で、プレイマットに描く絵を素人がほぼノーコストで量産できるようになったために、オークションやフリマに格安品が溢れています。
モチーフとなるキャラクター自体には今のところ著作権による保護がされていないので法的に問題ではない(公式絵などを流用したりするとアウト)んでしょうけど、多少抵抗はあります。
とはいえ、クーポンなどを駆使すれば30×60mmの新品ラバーマットが500~1000円で手に入るのは、数年前には考えられなかった現象だと思います。
キャラクターなどのバリエーションも非常に豊富で、イラストそのもののクオリティもかなり向上してきています。
実は前に一度、デスクマット用に1つ買ってみたことがありますが、普通に問題なく今でも使えています。
個人的に割とおすすめ。
できればnoteに投稿できるような絵柄のヤツを買おうとは思いますが、何も追加情報がなければお察し下さい。
この記事が気に入ったらサポートをしてみませんか?