
今更聞けないLLM解説まとめ⑤Fine Tuning

どうも、それなニキです。
今回も勉強を続けていきましょう。
いつものごとく、自分の思考まとめで読みにくいですがご了承ください。
また、最初からそうですが、基本的には松尾研のLLM Summer School 2023の内容を全面的に参照しています。
1.LLMにおけるFine-Tuningの位置づけ
まずはLLMを訓練していく上での流れを俯瞰してみましょう。

これまで扱ってきた「事前学習」はこのプロセスにおけるStep1に該当しますが、今回扱う「Fine Tuning」はその次のStep2で行われる作業になります。
事前学習(Pre-Training)とFine-Tuningを比較した表も松尾研資料にあるので引用しておきます。
ありがてぇ…
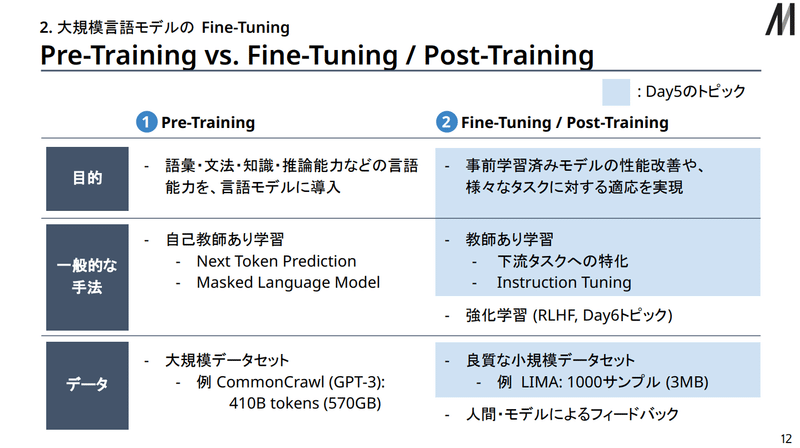
さて、上の図を見つつ違いを確認すると
事前学習はLLM訓練の土台(基礎的な単語・文法・論理など)を提供する目的で、自己教師あり学習(テキストの続きを自動で回答とする)で、大規模なデータセットで行う。
Fine-Tuningは事前学習済みモデルを応用タスクへ適応させる目的で、教師あり学習(問題と回答が明確に示されたデータセットを使う)で、良質な小規模データセットで行う。
という違いがあります。
こうしたFine-Tuningですが、事前学習と同様に研究が進んできており、従来型のFine-Tuningからさらに改善された方法論が確立しています。
代表的な二つを紹介します。
2. Instruction Tuning
この手法はFLAN論文と呼ばれる論文で提案された手法で、
「様々なタスクを指示・回答という形式に統一したデータセットにより、言語モデルをFine-Tuningする手法」(松尾研資料P17)
です。
従来のFine Tuningと何が違うのかというと、従来型では下流タスクに合わせた特殊なトークン(文字)を使って、そのタスクに特化した学習を行っていたところを、様々な種類のタスクを内包した、形式統一済みのデータセットを使って学習を行うことで、より幅広い下流タスクでの性能向上ができるようになったという点が異なります。
…むしろInstruction Tuningの方を先に考え付かなかったのかというのは疑問ですが
いずれにせよ、このInstruction TuningによってZero-shot性能(第二回の範囲)や指示応答性能(こちらはハッキリ分からなかった)の向上が確認されています。
-Instruction Tuning用データセット作成の要点と問題-
Instruction Tuningは勿論完璧な手法ではなく、現状以下のような課題を抱えています。
高品質かつ無害なデータセットの用意が必要
データセット内のタスク・形式の多様性も重要
つまるところ、データセット作成に多くの人的・技術的リソースを必要とするということです。
ただし、1.LLMにおけるFine-Tuningの位置づけ で確認した通り、このデータセットは事前学習ほどの規模を必要とせず、比較的小規模で済みます。
そのため、様々なデータセット構築方法が提案されています。
ラベル付きデータセットの統合
既存のラベル付きデータセットを、形式を変換して統合する手法
例…FLAN(62個のデータセットの統合体)
人間によるデータ作成
質を重視して人力でゴリ押す
例…InstructGPT(指示文・回答共に人間が作成)
LLMによるデータ作成
人的・技術リソースを使うならそれLLM自身に代替させればいいのではの精神
例…Self-Instruct(LLMによる指示文・回答の生成フレームワーク)
-その他派生-
①In-Context Tuning
In-Context Learning(第二回の範囲)が促されるようにFine-Tuningする手法。
主にFew-shot性能(第二回の範囲)が上昇する。
まあ、そのまんまですね。
使用するデータセットの入力文がFew-shotの形式になっているという認識でいいと思います。
②Symbol Tuning
正解ラベルを無関係なシンボルに置換したデータでFine-Tuningして、入出力関係の学習を強制することで、Few-shot性能が向上する。
うーん。何言ってんだかという感じだと思うので、図を持ってきます。
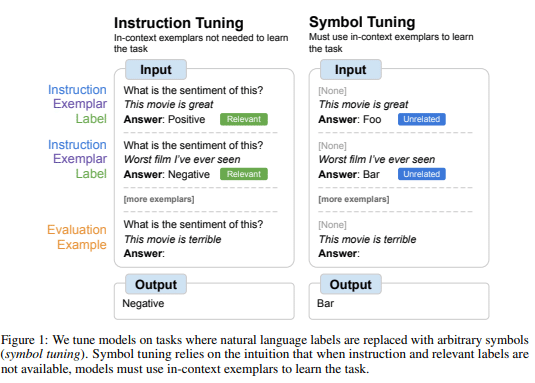
松尾研の資料にも引用があった表です。
Symbol Tuningの方を見てもらうと、
Positive→Foo
Negative→Bar
という感じで、意味不明な文字列に変えられているのが分かるかと思います。
こうすることで、そもそも回答文の表現が抱えている入力文との関係性を排除できるので、本来学習したい関係性とは別の要素によって正解してしまい学習を回避してしまう現象を抑制するのに有効
…だと個人的には解釈しています。
3.Parameter Efficient Fine-Tuning(PEFT)
「Parameter Efficient Fine-Tuning」という名称からも何となく察される通り、今度はデータセットではなく、パラメータに関する手法です。
一言で言ってしまうと、PEFTとは「一部のパラメータだけ、ないし追加したパラメータだけ学習させる手法」です。
従来型の手法との比較についてこれまた松尾研資料に図があるので引用します。

PEFTと比較されているのはFull-FT(普通に全パラメータをFine-Tuningする)です。
そりゃ学習させるパラメータが少ないわけですから、RAMに展開されるデータ量が削減されて、必要な計算資源の量が激減するのは想像に難くありませんが、一方で性能の改善がどこまで見込めるのかというのは気になるところです。
実際、PEFT手法を評価する上での主要な観点について、松尾研資料に紹介があります。

大きく分けて、「性能改善」「運用性」「訓練効率」「推論効率」の4つの観点が上がっています。
PEFT手法のカテゴライズ
さて、このPEFTですが、先ほどのInstruction Tuningとは異なり、具体的な手法や論文が話に上がってきていないというのに気付いたでしょうか。
実は一概にPEFTといっても、具体的な方法論は非常に多岐にわたります。

うわぁめんどくせぇ…()
そんなわけでカテゴライズしつつ紹介します。
Adapter型
Soft Prompt型
Selective型
Reparametrization型
①Adapter型
Adapter型は、Transformerの内部に学習可能なAdapterモジュールを追加し、そこにのみ学習を行わせるタイプです。
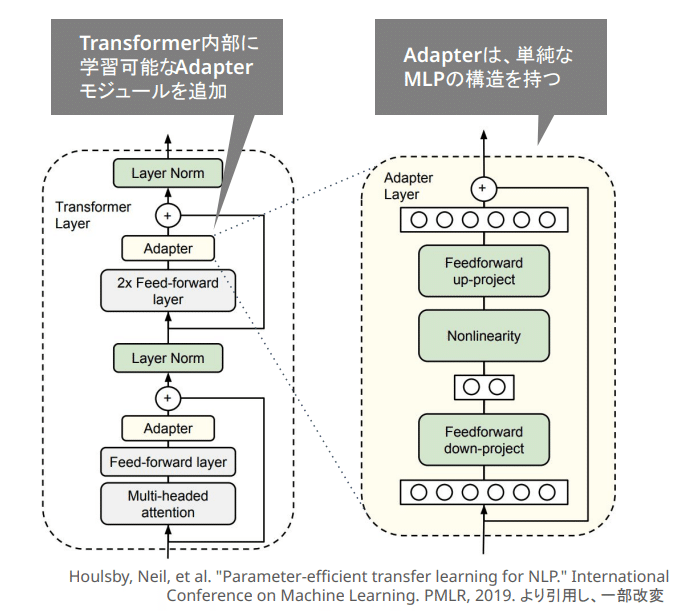
これは最初の記述でいうところの「追加したパラメータだけ学習させる」手法に該当します。
このAdapterの追加位置については亜種がいくつかあります。
上の図では直列的にAdapterをつけていますが、これを並列的にすると「Parallel Adapter」と呼ばれるタイプになります。
メリット
Full-FTに対しオーダーが1.2つ程度小さい訓練パラメータ数で同等の精度が出る
Adapterのみ保存すればよく、柔軟に付け替え対応が可能
デメリット
Adapter追加により推論にオーバーヘッドが発生
代表例は言わずもがな、カテゴライズの名称にもなっている「Adapter」です。
②Soft-Prompt型
Soft-Prompt型は、各タスクに対応したベクトルを入力系列に付加し、そのパラメータを学習
…するらしいんですが、これがどうもよく理解できていません。
一応図を引用しておきます。
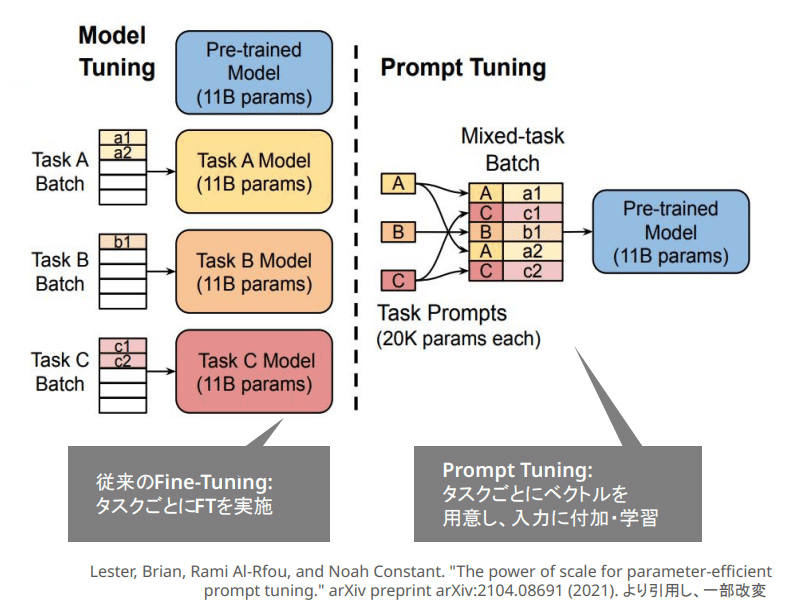
自分の今のところの理解で行くと、「タスク固有のプロンプトを用意して、そのプロンプトを学習させる」といったところでしょうか。
メリット
モデルサイズが大きい場合はFull-FTと同等の精度
プロンプトしか学習しないので、無論学習させるパラメータとしては非常に小さくなり、計算資源を節約できる
デメリット
Soft Promptが入力系列を圧迫する(プロンプトが増えるので)
プロンプトエンジニアリングの拡張としてとらえると、解釈性に欠けた結果しか得られない
代表例は「Prompt Tuning」です。
うーん名前のまんま…
③Selective型
Selective型は、Transformerの各モジュールに含まれるバイアス項だけを学習・更新する手法です。
バイアス項とは、Transformerの説明(第三回)でちょくちょく出てきていた「線形変換(MLP)」において付け足されるもので、出力を入力以外にも依存させることで柔軟性を生む役割があります(名前の通り、バイアスを加えると考えてもいいかも)。
こっちは、「一部のパラメータだけ学習させる手法」ですね。
メリット
学習データ数が小さい領域ではFull-FTよりも高い性能
訓練パラメータ数を削減できる
デメリット
大規模なモデルにおいては、Full-FTや他のPEFT手法よりも制度が劣る
代表例には「BitFit」があります。
④Reparametrization型
今度はどえらい名前が長いですが、Reparametrization型、特にその代表例のLoRAは、Full-FTにおいて更新されたパラメータ(重み)を、事前学習時のパラメータと増分の和に分けられると考えて、その増分を低ランク行列の積として、その行列について学習を実施する…という手法です。
…ものすごく見覚えのある名称が登場していますが一旦置いておくとして、難しいという方のために図だけ引用してみます。
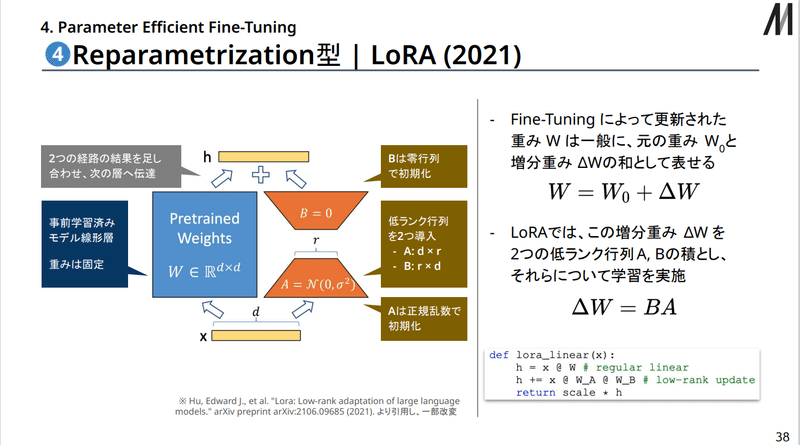
このオレンジの部分がLoRAにおける学習部分になります。
要はパラメータの増減部分だけ学習できねぇだろうかというシステムになっています。
この手法は、基本的に学習する部分のほぼすべてに適用できますが、少数の学習部分にランクの高い行列をつけるより、ランクが低くてもいいから多くの学習部分に行列をつけた方が性能は上がりやすいそうです。
メリット
訓練パラメータ数のオーダーを2~4つほど下げつつ、Full-FTと同等の精度が出せる
推論時に、得られた重みをもとの重みにあらかじめ足しておけば、処理に必要な計算資源が増えることは無い
デメリット
特に難易度の高いタスクではFull-FTに対して著しい性能の劣後が生じうる
代表例はLoRAです。
この名称、画像生成AI界隈に片足を突っ込んでいる方なら非常に聞きなじんでいるワードなはずです。
現在、画像生成分野において最も一般的なFine-Tuning方法としてはこのLoRAが普及しています。
まあ考えてもみれば、
学習で得られた追加分の行列が手に入れば、他の環境でも学習結果をすぐに再現できる
複数のLoRAも、単純に足し合わせれば同時に利用できる
それぞれを定数倍することで、直感的に学習部分の影響などを調整できる
内部の重みに足し合わせることで特に必要計算資源が増えない
といった利点は、個人で追加学習を行ったり、その学習結果を共有する画像生成コミュニティにおいては非常に有益ですから、この手法が採用されているのはある種当然なのかも…
また、このLoRAの派生として、QLoRA,AdaLoRA,ReLoRAなどのアプローチも存在します。
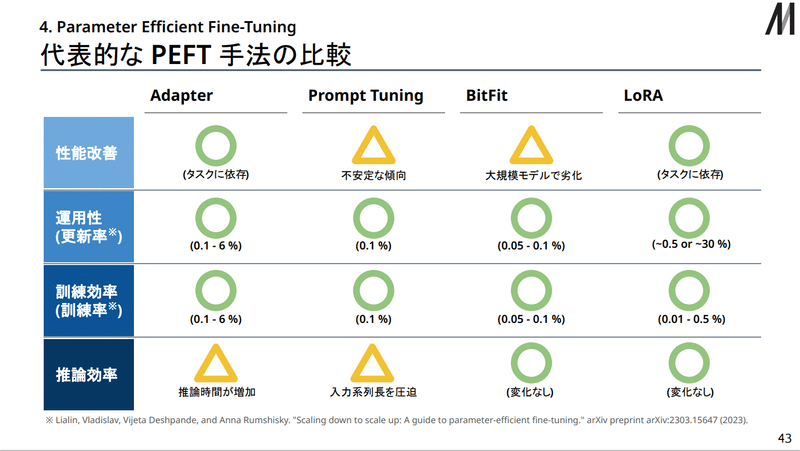
各手法の比較
比較用に図でまとめられていたので、松尾研の資料から引用しておきます。
終わりに
お疲れさまでした。
この記事も残すところあと1回になります。
一通り書き終えたら再度校正などしつつ、実際に学習した知識をもとにLLMを実装・学習していく方法の解説・実践に移っていければと思っています。
余談
さて、もはや恒例のコーナーと化しつつある余談ですが、今回は前話した遊戯王の続きになります。
ここ二週間ほど、暇を見つけてはちょくちょく秋葉原のサテライトショップに顔を出しています。
言うても交流イベに出ているだけで、ランキングデュエルにはまだ参戦していませんが。
現状唯一機能している覇王門魔術師デッキを持って行っても、調整不足で展開力を有り余らせている感じがあり、ガチ戦に持っていけるか微妙なところです。
調整用のカード調達もちょくちょく進めていますが、最近やたらクーポンが各所でもらえて、閉ザサレシ世界の冥神のレリーフが480円だったりしました。
ついでに閃刀姫関係で、エンゲージのレリーフが300円、キアノス(N)が240円、禁じられた一滴(SR)が3枚400円といった感じで、非常にお得?に入手できています。
そのうち閃刀姫も記事にすると思います。
この記事が気に入ったらサポートをしてみませんか?