画像と音声からリップシンクを生成するAIツール「DreamTalk」で遊んでみる👄

AliBabaが公開している画像を音声に合わせて喋らせるAIツール(トーキングヘッド生成フレームワーク)「DreamTalk」。
AIサービスではHeyGenやDIDなどもありますが、オープンソースで試すことができる状態でしたので試してみました!
Githubのページはこちら。
デモはHugging Faceから!
早速アクセスしてみます。
アバター画像、音声ファイル、感情を選んで押すだけで良いUI ということで大変わかりやすいですね!

それじゃ早速いじって行きますか!
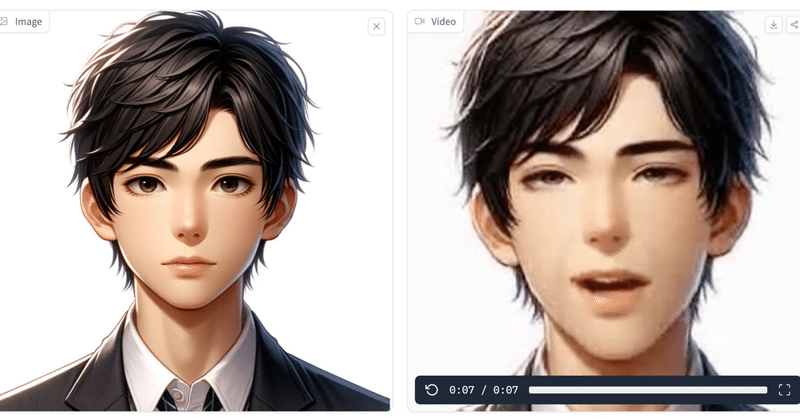
まずはリップシンクしたいアバターを用意したいと思います。

そして画像をセット。

その後は音声を自分で入れるか用意されている中から選び、同時に感情もセレクトします。


早速スタート!

…
ちょっと待つとすぐできました。

たしかにしっかり話しています!
が、自然とまでは言いづらく、ちょっと歪なところもあるかな?
ぜひ動画で確認してみてください!
dreamtalkを試してみた。https://t.co/YUJbUk12rH pic.twitter.com/vhN8d8dNZW
— SUTO💡 (@st_e_ai) March 21, 2024
使い道はありそうでなさそうなリップシンクですが、今後もっと精度が上がってくると自分で喋るときとかに面倒だったらリップシンクさせるとかそういうことができたりするのかな?基本はこれもディープフェイクですね。
今日はここまで〜(勉強になった)
この記事が気に入ったらサポートをしてみませんか?