
赤ちゃんは統計学を使って言語を学ぶ

赤ちゃんはどのように言語を学ぶのでしょうか。家庭内で2つの言葉が飛び交うバイリンガル環境のこどもはどのように言語を区別しているのでしょうか。
実は赤ちゃんは頭の中で統計的な処理を行い、確率的にその言語らしい響きの単語とそうでない単語を区別できることを示した実験をご紹介します。
【結論】
生後8ヶ月の赤ちゃんは、隣接する音声間の統計的関係のみに基づいて、単語を識別することができた。
【実験デザイン】
対象:アメリカの英語環境で育つ8ヶ月の赤ちゃん24人
赤ちゃんに2分間、人工的に作り出した(実際には存在しない)4つの単語を聞かせる
例: TOKIBU GIKOBA GOPILA TIPOLU
音声は機械読み上げで、抑揚や単語間の息継ぎはなし。順番はランダム
例: TOKIBUGIKOBAGOPILATIPOLUTOKIBUGOPILA…
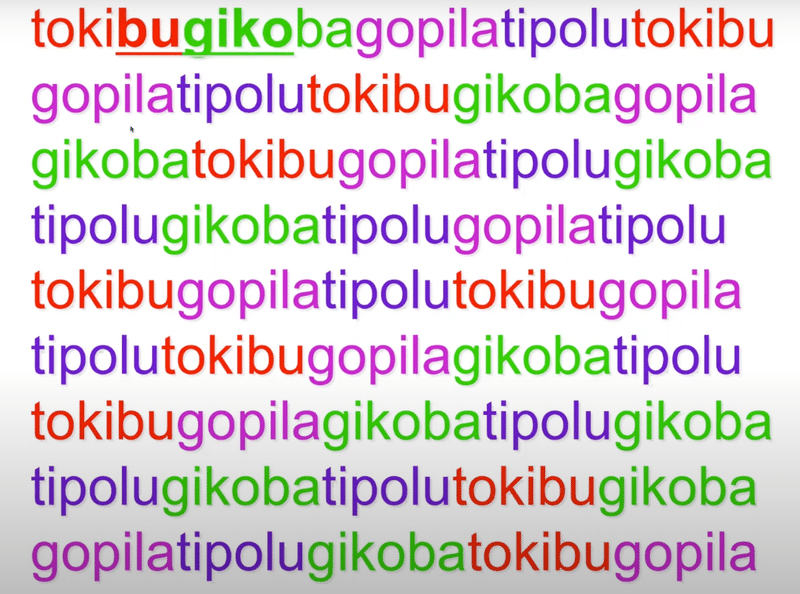
抑揚や単語間の息継ぎがないため、どこが単語の切れ目なのかのヒントは確率のみ
例: TOKIの後には100%の確率でBUが続く(「TOKIBU」という一つの単語のため)が、KIBUの後にはGIかGOかTIのどれかが33%の確率で続く(「TOKIBU」の後には「GIKOBA」「GOPILA」「TIPOLU」が続くため)
お経のような単語の繰り返しを2分間聞いた後に、赤ちゃんがwordとpart-wardのどちらの音声をより長く聞くのか測定した。
(右側と左側それぞれにランプのついたスピーカーがあり、赤ちゃんが視線を向けている間スピーカーから単語が流れ続ける)
Word : 最初の2分間で学習した4つの単語
TOKIBU GIKOBA GOPILA TIPOLU
Part-Word : 4つの単語がランダムに繰り返されるため、4つのWordのどれかの後半の音節と前半の音節がつながった単語
下記の写真の例だと、冒頭のTOKIBUはWord、下線の引かれたBUGIKOはPart -Word(TOKIBUのBUとGIKOBAのGIKOが偶然連続しただけ)です。
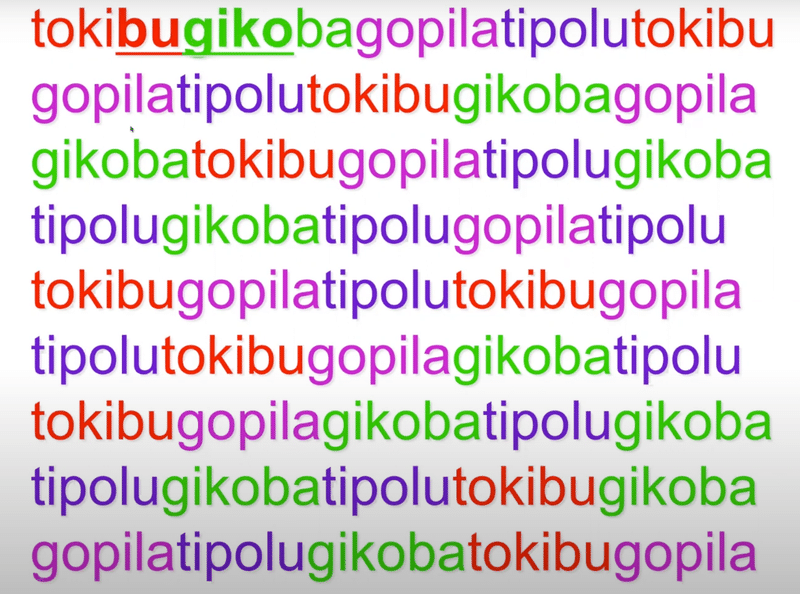
結果、Wordよりも、Part-Wordの音声を聞く時間が統計的に優位に長かった。単語やスピーカーの位置を変えても結果は同じだった。

つまり、赤ちゃんは、たった2分のリスニングでも、音の並びの確率を頭の中で計算して、より聞き覚えのある単語とそうでない単語を区別することができた。
エビデンスレベル:観察実験
文章で実験デザインがわかりづらい場合は是非動画をご覧ください。
実験の様子はこの動画の33分10秒からです。
【編集後記】
私たちは、初めて聞く日本語の単語が「しょ」で始まった場合、次に来るのは「う」あたりかなと経験則から予測することができます。(少なくとも「を」や「ぷ」が続く確率は低そうですよね)生後8ヶ月の赤ちゃんの時からそのような能力があるというのは驚きです。
赤ちゃんを始め人間がどのように物事を学習するかを参考にしているのが、昨今進化の目覚ましいAI(人工知能)です。例えば村上春樹風小説を作る文章生成系AIは、単純化すると、村上春樹氏の文章を大量に学習し、○○という単語(もしくは前後の文章)の後には、△△という単語や文が来る確率が高いと予測の元にそれらしい文章を生成しています。これはこの実験で赤ちゃんが行っていることと全く同じ原理です。人間の脳みそはすごいですね。
文責:識名 由佳
参考文献
Saffran, J. R., Aslin, R. N., & work(s):, E. L. N. R. (1996). Statistical Learning by 8-Month-Old Infants. Science, New Series, 274(5294), 1926–1928.
http://pzacad.pitzer.edu/~dmoore/1996_Saffran,%20Aslin,%20Newport_Stat'l%20Learning%20at%208%20mos_Science.pdf
この記事が気に入ったらサポートをしてみませんか?