
LoRAを作りたかった

LoRA学習したいけどちょうどいい記事が見つからなかった。
パラメータ設定にどういう意味があるか、とか。
step数はいくつが良いんでしょうか、よく分かりませんでしたね とか。
そういうのは求めてない。
「この手順通りに作ればとりあえずLoRAができる」という記事が欲しかったんだ。
1. 目的
LoRAを作る目的は「画風」「キャラ」「特殊シチュエーション」の再現が目的だと思う。どの目的でも以下の手順で作れる。はずだ
2. パラメータのこと
オプティマイザが最も重要である。これが最も結果に影響を与える。はずだ
LoRAは設定できることが多すぎる。初心者である我としては設定項目をできるだけ少なくして、どの設定がクリティカルに効いているのかを体感で掴みたい。
オプティマイザは「学習率を設定しなくてよくなる」=設定項目を減らせる、という非常にありがたい効能を持っている。この効果は私のメンタルに素早く効く。
すなわち、自動型オプティマイザを使っておけばよいのだ。
画風LoRAなら AdaFator
キャラLoRAなら DAdaptAdanIP
とりあえずこれを使っておけば問題ないと思う。
AdaFactorは画風を覚えやすく、DAdaptAdanIPはキャラを覚えやすい。気がする
Step数は 2000-3000 で良い。
画風は2000, キャラは3000で覚えられる。
epoch数を20にして、5epochごとに保存する設定としておく。
すなわちこうだ。
num_epochs=20
save_every_n_epochs=5
network_dim=16
network_alpha=1
scheduler="cosine_with_restarts"
scheduler_option=1
opti_type="DAdaptAdanIP"
opti_args= --text_encoder_lr=0.5 --unet_lr=1.03. 教師画像のこと
教師画像が最も重要である。
間違えた。オプティマイザの次に重要である。
教師画像Aとして、公式などのキャラ・服装の特徴を掴んでいる素材を集める。
9枚で良い。
設定次第だと思うが、枚数を増やしても質が良くなるように思えない。
4. LoRAを作る
細かい手順は省略。作れたという前提で話を進める。
冒頭の説明はどうなったって? 知らんな。
4.1 XYZprot
仮LoRAができたら Script = X/Y/Zprot を使って epoch数(step数) を確認する。
Scriptの場所はみんな知ってるよね。txt2imgタブの最下部にある。
使い方は非常に簡単。
まずプロンプト欄に epoch 5 のLoRAを指定する。
そしてXYZprotのスクリプト欄に
置換元プロンプト, 置換後プロンプト1, 置換後プロンプト2, …
を記入する。

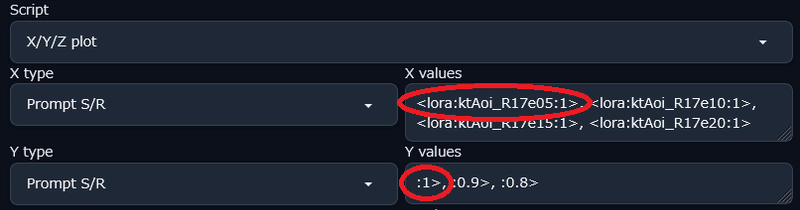
末尾にコンマを付けると無駄な画像を作ってしまうので要注意(2敗)
結果はこんな感じになる。

だいたいの傾向として、10 epoch (1000step以上) でキャラの特徴を掴んでいる。
20 epoch - 強度1.0 が最も再現性が高いのだが、教師画像の画風に影響されていそうだ。
このままでも使えそうな気はする。
しかし、再現度と画風のトレードオフの適正値を探りたい。そこで、LoRAを適用するUNetの階層を選別する。使うのは LoRA Block Weight だ。
直観的な生き方をしている私には手に負えない代物である。
しかし葵ちゃんのためにはやるしかない。
4.2 LoRA Block Weight
LoRA Block Weight は txt2imgタブの下の方に追加される。
使い方は非常に難しい。
いや難しくは無いのだが、反直観的である。覚えるしかない。

忘れた。忘れていても使うことはできる
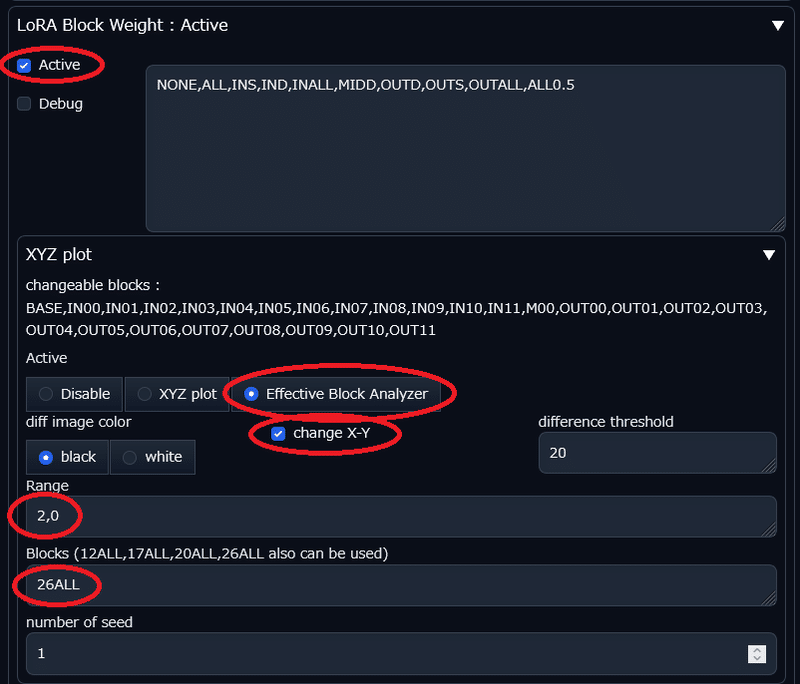
なお、Lycorisの場合は 26ALL だが、LoRAの場合は 17ALLまでしか設定できない
重要なのはRange設定だ。
上記の画像だと、UNet全階層のベース強度を0としている。そして、BASE, IN01, IN02 …と順番に、1つの階層だけ強度2 にして、26種類のイラストを作る。ということになる。つまり、最低限この階層は強度設定しないとLoRAが機能しないよ、という階層を見つけることができる。
(どこかの記事でお勧めされていた設定だ)
そして、上記と合わせてもう1つ、Range = 0,1 の比較画像も作っておくと良い。
こちらはこの階層を強度0にしても結果に影響ないよ、という階層を見つけることができる。


服装に影響が出ているのは IN04, IN05, M00, OUT03, OUT04 のようだ。
そして IN01, 02, 07, 08, 11, OUT02, 05, 06, 08, 11 も怪しい。
それ以外の階層は服装再現には効果がなく、画風に悪影響を与えている可能性が高いので強度0にしていい。
感覚的にはこんな感じだ。
BASE :LoRAの強度
IN00-06 :消しても影響は少ない
IN07, 08 :構図や背景等。ここを削ると白背景から解放される
IN09-11 :消しても影響は少ない
M00 :構図に大きく影響する。ここを消すとポーズに自由度が出る
OUT00-02 :ディテールに影響がある。消すと靴の色が変わったりする
OUT03-05 :キャラクターの造形。キャラLoRAで最も重要な階層
OUT06,07 :塗り。ここを消すと元絵の画風から離れる。0.5 が無難か
OUT08-11 :画風や塗りに影響する。ここを消すとモデル本来の画風に近づく
じゃあ、ここでエクセルを開こう。
Office365が大嫌いな儂のような人間は LibreOffice を起動するかもしれない。
で、こんな感じに打ち込んでいって、すべての数字をコンマ区切りの文字列にまとめたものをプロンプト欄に入れる。


Effective Block Analyzer を Disable にするんだ。
Effective Block Analyzer を Disable にするんだ。
Effective Block Analyzer を Disable にするんだ。
じゃあイラスト作成しよう。

服装の再現度は良い感じ。構図の偏りが気になる。背景もだ。過学習なんだろう。
Text encorder 強度を下げるか、BASE 強度を下げるか、あるいは怪しい階層を1つずつ強度0にしていって影響を確認するしかない。地道な作業である。
それにしても1枚目はなかなか良い出来じゃないか。
さて、LoRA Block Weight の設定が決まったらLoRA本体に焼き付けて固定したい。
いつもいつも lbw=1,0,0,1,0,1, … なんて書くのは鬱陶しいからだ。
使うのは SuperMergerである。
4.3 SuperMerger
SuperMerger は新たなタブが追加される。
いつも思うんだけど、各拡張機能はどこに追加されるのか明記しておいてほしい。タブが増えるのか、あるいはtxt2img の中に追加されるのか。
使い方を説明している人も、追加場所までは説明してないことが多い。
話が脱線した。
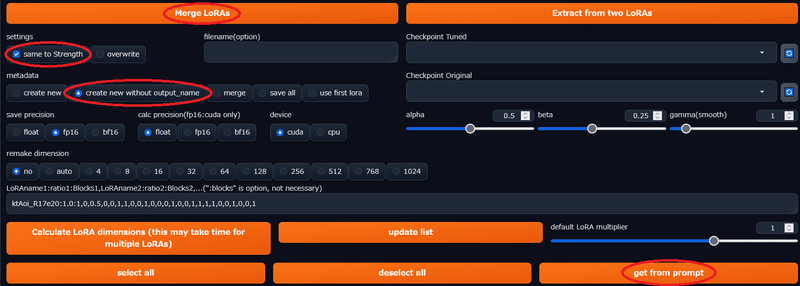
SuperMergerタブの中にさらにタブがある。使うのはLoRAタブだ。
get from prompt ⇒ create new without output_name ⇒ same to strength ⇒ merge LoRAs を押すとLoRAフォルダに新規保存される。
ちなみにSuperMergerしたものを使って同じSeedで作ってみると、マージ前と同じイラストにはならなかったりする。微妙に変わる。なんでかは知らない。
ほぼ同じだから良いでしょう。
5. 教師画像のこと
4.3で良い結果が得られたなら終わりだけど、そうでないこともある。
「解像度が低い」「画風・画角・ポーズが偏る」という問題が典型だと思う。これらは教師画像Bを追加して再学習すれば良くなる可能性がある。
(良くならないこともある という点に注意が必要である)
教師画像Bもそれほど多くは必要ない。教師画像Aと合わせて15枚あれば良いと思う。
せっかく作るなら偏りを無くすためにバリエーションを増やしておくといい。
この dynamic prompt が役に立つかもしれない。
{black | dark-brown | light-brown | blonde | silver | red | pink | green | purple | blue | light-blue} hair,
{happy | slight smile | (embarrased:0.8) | expressionless | (anguish:0.8) | closed eyes | :D | (tears:0.8)},
{standing | sitting | lying | leaning forward | crossed legs | ojou-sama pose | on back | on side | standing on one leg},
{from front | from above | from below | from side | profile},
{full body | cowboy shot | upper body | portrait},
{arms behind back | arms at side | arms behind head | hands up | own hands together | hands between legs | outstretched arms}
6. 全然うまくいかない
ここまで説明しておいてなんだが、納得いくような出来になることはほぼない。
何かが足りないのだ。
どこかで妥協することを考えた方が良い。
というか、現状でも改善できそうな課題はいろいろある。
「学習素材の解像度が低い」
「学習素材の画風・画角・ポーズに偏りがある」
「学習に使うモデルによって結果が違う」
「スケジューラとオプティマイザと学習率の設定を変える」
こんなの1つずつ試すなんて気が遠くなる。
学習1回で2時間ぐらい待たないといけないんだ。夏になったら熱でぐったりしてしまう。次の冬まで待てというのか。
ボヤキで終わってしまっては残念すぎるので、ここに2つの思い付きを残しておく。
7. 思い付き just idea
7.1 マイナス適用したらどうなの
キャラ再現がイマイチなのは学習が足りないからだ。しかし服装の再現性を求めて学習stepを増やしたら過学習になる。
過学習の何が問題なのかと言ったら、画風・構図が固定化されてしまってモデル本来の味が死んでしまうことである。
じゃあそこだけ消せばいいじゃんという話なのだが、どうもLoRA学習は画風を覚えやすく、キャラを覚えにくいように感じている。構図は分からん。
とにかく。
失敗作の仮LoRAで、教師画像Cを作って、それを使って学習させたダメLoRAを作り、これをマイナス適用したらどうだ? 画風だけ消えてくれるんじゃね? という思い付きである。
実際にやってみた。

こいつの出力結果を教師画像にして学習してみる
ダメ教師画像Cから出来上がった失敗作LoRAをマイナス適用する。
するとこうなった。

ところでこれってEasyNegativeと何が違うのかね

効いてはいるけど服装が崩れるな
いかがでしたか?
よく分かりませんでしたね。
7.2 LoRA適用を途中で止めてみる
プロンプト技術の一つとして、途中のstepまでプロンプトを生かしておいて後半では無効化する、という表記がある。
[from::when]
from 部分にプロンプト、when 部分に適用を止めるstep数を入れるらしい。
トータル20stepにして、中間の10stepで適用を止めてよう。
実際にやってみた。

平行視を使ってじーっと見てみると、髪のリボンがわずかに短くなっていると分かる。
「同じじゃないですか!」と言われたら「そうとも言える」と答えるしかない。
いかがでしたか?
よく分かりませんでしたね。
8. 締め
葵ちゃんLoRAの出来はもうひとつ物足りないところではあるが、すでに20通りほど設定を変えてみて、その度にUNetの階層調整を行っている。割と力尽きてしまった。
SD1.5の性能に限界を感じている。
NAIちゃんv3を試した方が良いんだろう。しかし、そちらに手を出してしまうと沼になりそうだ。イラスト作成以外のことに時間を使えなくなってしまう。
それよりはSD3.0で再現性が改善されることを期待して、公開されるまでLoRA作成の知見を持っておくに留めた方が良いのだろう。
そういうことにする。
Animagazine? なんですかそれは。
長々読んできた方には申し訳ないです。
本記事はLoRA作成に失敗した話です。
それでも誰かの役に立つことがあるかもしれません。
この記事が気に入ったらサポートをしてみませんか?