TOEICの音声をWhisperで認識して編集してみる

以下のつづき
TOEIC Programの公式サイトにある参考問題のNo. 7を利用して試している
TOIECのPart 2の音声をWhisperで音声認識して編集できないか試行錯誤している
Word単位の時間が得られると、音声編集するときに便利だと思い試してみた
以下のように、--word_timestampsを指定すると、ワード毎の時間が取得できる
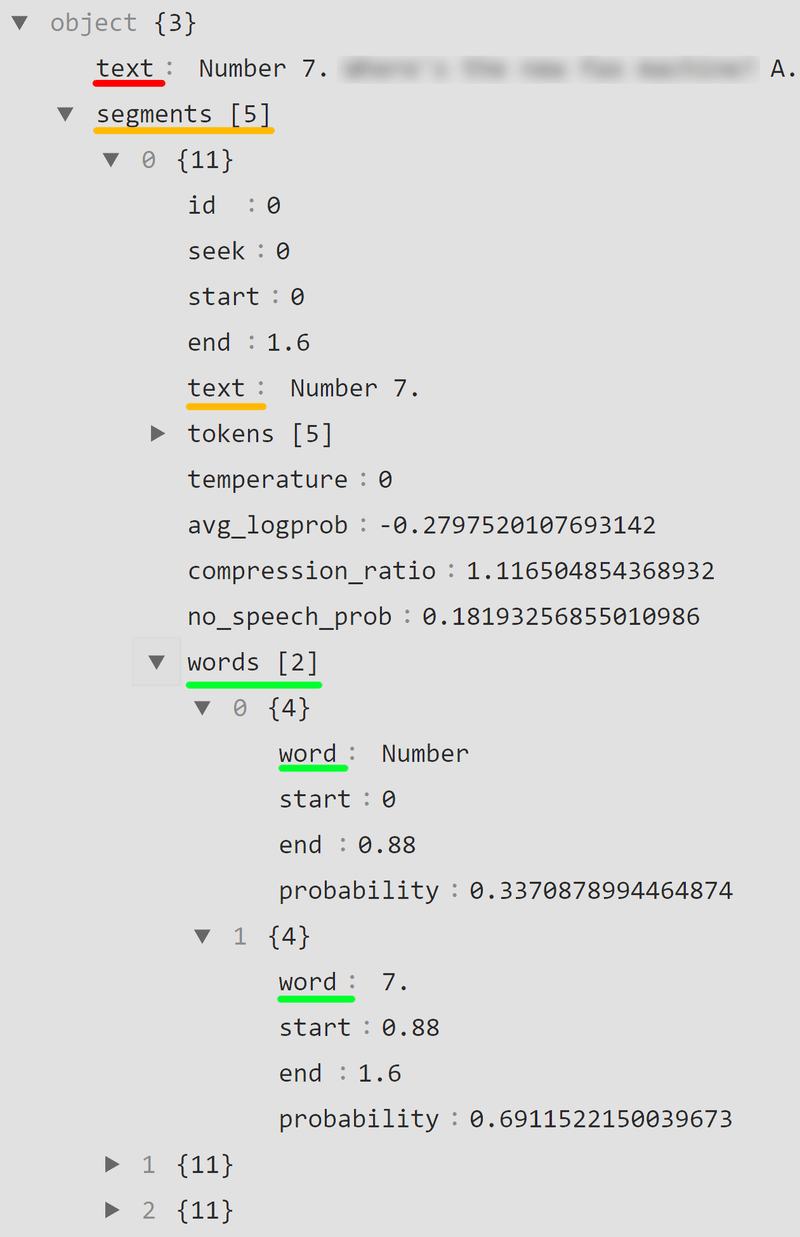
whisper --model base --language en --word_timestamps True Part2No7.mp3以下のような階層化されたデータが得られる(JSON形式)
5つのセグメントがあり
1つ目のセグメントは「Number 7.」という設問番号の音声
1つ目のセグメントに含まれるワードは「Number」と「7.」
期待するデータが得られた
word_timestampsをOnにすると処理時間が長くなるようだ
適当なプログラミング言語で音声編集すればよさそう
WhisperはPythonからでも実行できるので
Pythonを使うのがよさそう
音声の編集はpydubが便利そうだ
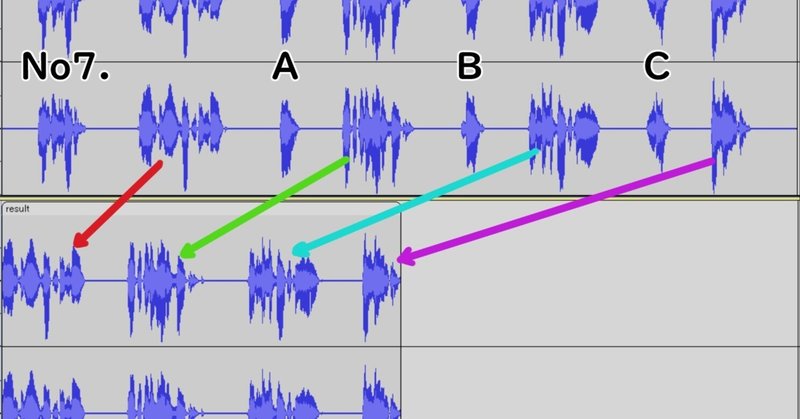
Pythonのpydubを使って音声を編集してファイルに書き出してみた結果、設問番号とA、B、Cを削除することに成功した

今回の例では、pydubの無音検知機能を使って音声処理した方が高速で正確、実装も簡単そうだ(結構、時間を費やしたので悔しすぎる結果だ)
認識した結果を利用して、正解を推測しようと思ったら、AIが必要になるだろう
TOEICの癖のある返答に、一般的な会話のAIが対応できるか興味がある
人間の自分は、TOEICのPart 2の奇抜な応答に?が出ることがある
TOEICワールド向けのAIを作るのもおもしろそうだ
今回の実験で得られたWhisperの知見は、また別の形で活用できたらと思う
この記事が気に入ったらサポートをしてみませんか?