【R】YouTube「にじさんじ」ライブ配信アーカイブのチャットデータを可視化してみる

前回の続き。
配信全体でのチャットのコメントの傾向を見てみる
取得したチャットのコメントをワードクラウドで可視化してみる。
まず、下準備としてチャットのコメントをファイルに保存する。
video_id <- res_live$items$id$videoId[1]
write_lines(chat_df$comment, sprintf("%s.txt", video_id))次に、{RMeCab}パッケージのRMeCabFreqを使って、形態素解析を行い、名詞と形容詞を抽出する。何回か実行してみて、品詞や単語など、いくつかフィルタリングを追加している。
library(RMeCab)
generateWcDf <- function(f, ignore_term=c("草","ー")){
df <- RMeCabFreq(f) %>%
filter(Info1 %in% c("名詞","形容詞") & ! Info2 %in%c("サ変接続", "接尾", "非自立", "代名詞", "数") ) %>%
filter(!grepl("^[a-zA-Z]+$", Term)) %>%
filter(!Term %in% ignore_term) %>%
arrange(desc(Freq))
df
}
chat_wc_df <- generateWcDf(sprintf("%s.txt", video_id)){wordcloud2}パッケージを使ってワードクラウドを作成する。
library(wordcloud2)chat_wc_df %>%
select(Term, Freq) %>%
wordcloud2()
全体的には、「剣持」や「かわいい」が多く出現している。
うまい、すごい、いい、などあるので、好意的なコメントが多いようだ。
チャットのコメント数の時系列推移を見てみる
取得したデータでは、動画開始からの経過時間がミリ秒単位で入っているので、これを分単位に変換してコメント数を集計。実数を使っても良いが、ここでは、最大数を用いて指数化した。
chat_minutes <- chat_df %>%
mutate(
offset_time_min = floor(as.integer(offset_time_msec) / 60000)
) %>%
group_by(offset_time_min) %>%
summarise(
n = n()
) %>%
mutate(
y = n / max(n)
)ggplot2を使って可視化。
ggplot(chat_minutes, aes(x = offset_time_min, y = y)) +
geom_line() +
theme_bw()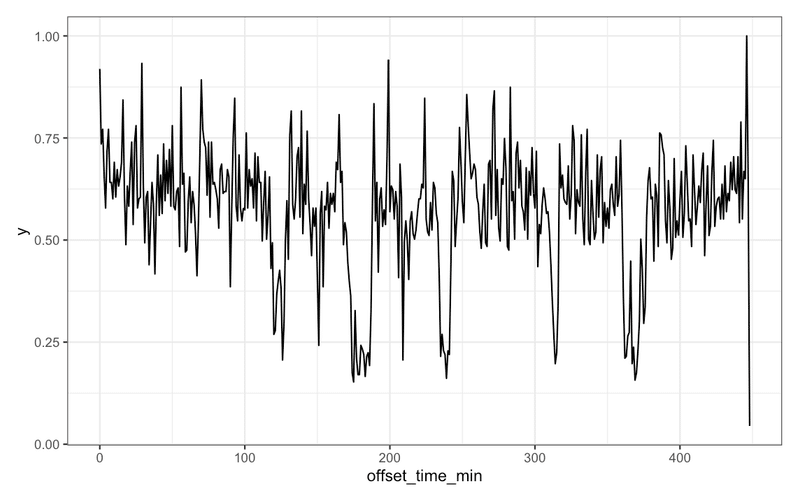
終了前が一番コメント数が多いようだが、これは挨拶がほとんどだと思われる。
また、200分近辺が次に多いので、中盤で盛り上がった事が分かる。
チャットが盛り上がっている箇所のワードクラウドを作成してみる
チャットのコメント数が順に並べ替えて、上位3つをワードクラウドで傾向を見てみる。
まずは、並べ替え。
chat_minutes_ordered <- chat_minutes %>%
arrange(desc(y)) %>%
select(offset_time_min, y)
chat_minutes_ordered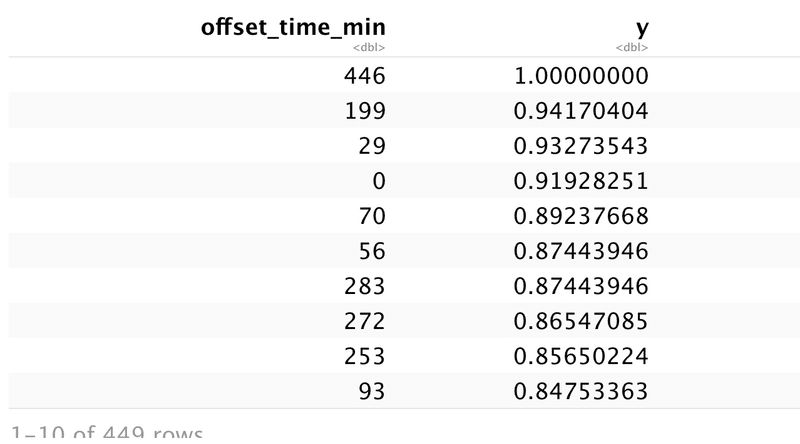
次に、上位3つのコメントをファイルに保存。
target_min <- chat_minutes_ordered$offset_time_min[1:3]
chat_df_top3 <- chat_df %>%
mutate(
offset_time_min = floor(as.integer(offset_time_msec) / 60000)
) %>%
filter(offset_time_min %in% target_min)
for(m in target_min){
chat_df_top3 %>%
filter(offset_time_min == m) %>%
pull(comment) %>%
write_lines(sprintf("%s_%d.txt", video_id, m))
}1つ目のワードクラウド。
generateWcDf(sprintf("%s_%d.txt", video_id, target_min[1])) %>%
select(Term, Freq) %>%
wordcloud2()
「お疲れ」のような挨拶が多いと想像していたが、次回予告に対してのコメントの「楽しみ」が一番多い。また「楽しい」という感想や、「長時間」「疲れ」などのような今回の配信に対しての挨拶のコメントが見れられる。
ちなみに、動画の任意のタイミングへのURLは、以下のように作成出来る。
target_sec <- target_min * 60
sprintf("https://www.youtube.com/watch?v=%s&t=%ss", video_id, target_sec[1])上記で作成したURLは、こちら。
2つ目のワードクラウド。コードは割愛。

「かわいい」が圧倒的に多い。次点で「クレア」が多いので、クレアさんに関して「かわいい」というコメントが多かったと思われる。
URLはこちら。
3つ目のワードクラウド。

「巴」「リゼ」という単語が多く出現している。まわりにあるワードを見ていくと、「うまい」、「つよい」、「安定感」、「すごい」などの単語が見られるので、巴さんやリゼさんのプレイについて盛り上がっている状況だと思われる。
おわりに
今回は、「にじさんじ」ライブ配信アーカイブのチャットデータを可視化してみた。
ワードクラウドを見ると分かるが、まだまだ名寄せ等やるべき事はたくさんあるが、ある程度傾向は見えたのではないかと思う。
この記事が気に入ったらサポートをしてみませんか?