YouTube「にじさんじ」ライブ配信アーカイブのチャットをGoogle Cloud Text-to-Speechを使って読み上げてみる

前回は、RでYouTubeのライブ配信アーカイブのチャットのデータを抽出して可視化を行った。
今回は、チャットデータを、Google Cloud Text-to-Speechを使って読み上げてみる。
Google Cloud Text-to-Speechの設定に関しては、以下のサイトを参考に行った。
https://blog.apar.jp/web/9893/
上記を参考に設定を行い、以下のシェルスクリプトを作成しておく。
ここでは、exec_text_to_speech.sh とした。
#!/bin/bash
export GOOGLE_APPLICATION_CREDENTIALS=<キーファイルのパス>
curl -H "Authorization: Bearer "$(gcloud auth application-default print-access-token) \
-H "Content-Type: application/json; charset=utf-8" \
-d @$1 \
https://texttospeech.googleapis.com/v1beta1/text:synthesize1位のチャットデータの抽出
まず、前回作成したコードで「にじさんじ」で検索して視聴回数が一番多いライブ配信のチャットデータを抽出する。
library(tidyverse)
library(rvest)
source("../src/functions.R") #前回作成した関数をまとめたファイル
api_key <- "**************"keyword <- "にじさんじ"
res_live <- executeYdApi(
"search",
params = c(key=api_key,
part="snippet",
q=keyword,
type="video",
order="viewCount",
maxResults=10,
eventType="completed")
)# 1位の動画のページのURL
video_url <- sprintf("https://www.youtube.com/watch?v=%s", res_live$items$id$videoId[1])チャット情報を抽出。
chat_df <- generateChatDF(video_url)
chat_df %>%
select(offset_time_msec, comment) %>%
sample_n(10)
チャットが盛り上がっている箇所のコメントを抽出
「盛り上がっている=コメントが多くなる」と仮定して、経過時間(10秒)ごとのコメント数推移を可視化する。
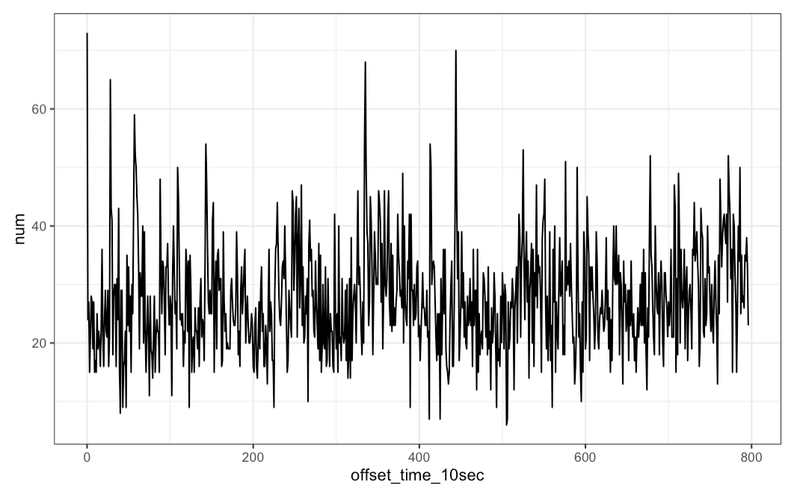
コメントが多いトップ3の箇所のコメントを抽出する。
top3_offset <- chat_10sec_df %>%
arrange(desc(num)) %>%
slice(1:3)chat_top3 <- chat_df %>%
mutate(
offset_time_10sec = floor(as.integer(offset_time_msec) / 10000)
) %>%
filter(offset_time_10sec %in% top3_offset$offset_time_10sec)データの確認
chat_top3 %>%
select(offset_time_10sec, comment) %>%
sample_n(10)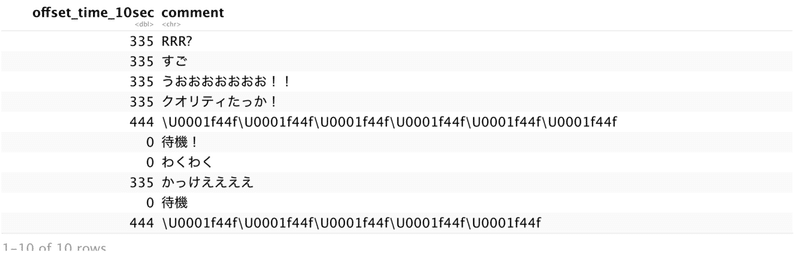
"\U0001f44f"は、調べたところ「拍手」の絵文字という事が分かった。読み上げで「拍手、拍手、拍手・・・」と連発されてもうるさいので後で削除する。
API用のJSONファイルの作成
Google Cloud Text-to-Speech のAPI用のJSONファイルを作成する。
まずは、リスト形式でテンプレートを作成。
input_template <- list(
audioConfig = list(
audioEncoding = "MP3",
pitch = "0.00",
speakingRate = "1.00"
),
input = list(
text = ""
),
voice = list(
languageCode = "ja-JP",
name = "ja-JP-Standard-A"
)
)テンプレートを使って、トップ3のAPI用JSONファイルを作成。
for(sec in top3_offset$offset_time_10sec){
d <- chat_top3 %>%
filter(offset_time_10sec == sec) %>%
filter(grepl('[^\U0001f44f]', comment)) #拍手の絵文字の削除
input_list <- input_template
input_list[[2]]$text <- paste(d$comment, collapse = "\n")
input_json <- jsonlite::toJSON(input_list, auto_unbox=T)
write_lines(input_json, sprintf("%03d.json", sec))
}音声ファイルの作成
Google Cloud Text-to-Speechを利用して音声ファイルを作成する。
事前に用意しておいたシェルスクリプトをRから呼び出して結果を取得する。
「audioContent」フィールドの値が base64 でエンコードされた音声データになっているので、デコードしてMP3ファイルとして出力する。
for(sec in top3_offset$offset_time_10sec){
res <- system(sprintf("../bin/exec_text_to_speech.sh %03d.json", sec), intern=T)
res_json <- jsonlite::fromJSON(res)
write_lines(res_json$audioContent, "tmp-base64.txt")
base64enc::base64decode(file = "tmp-base64.txt", output = sprintf("%03d.mp3", sec))
}この記事が気に入ったらサポートをしてみませんか?