
PythonとMeCabでTabjoのnoteを形態素解析してみよう
noteをお読みいただきありがとうございます!Tabjo Webコンテンツ担当のkanaです。絶賛開催中の「Tableau Tips*アドベントカレンダー」に参加しています!最近、社内でワードクラウドの表現をよく見かけます。私もトライしてみたいと思い、TabjoのNote記事を対象にワードクラウドに挑戦してみました。今回はその過程を紹介します。
【参加者募集中】Tableau Tips*アドベントカレンダー|Tabjo Official|note
1.はじめに
noteの記事をそのままTableauに接続しても、ワードクラウド表現はできません。なぜかというと、ワードクラウド表現を行うためには、文章を単語に分割して、その出現回数をカウントする必要があるからです。文章を単語に分割することを「形態素解析」と呼びます。
この形態素解析を行うには、必要なソフトウェアがあります。まずは、それらのソフトウェアをインストールしましょう。
2.ソフトウェアインストール
必要なソフトウェアは3種類です。
Anaconda3(64bit)
MeCab 0.996(64bit)
mecab-python-windows
インストールの手順は、こちらのサイトを参考にしました。
3.読み込むテキストの準備
今回は、2022年の活動記録の記事を対象にしました。
【活動記録】第31回 Tabjo お役立ちTips100本ノック!?WorkOutWednesday mini
【お知らせ】TC22にTabjoが登場!!
【活動記録】第33回 初めの一歩を踏み出して見えた世界~キャリアを支えるユーザーコミュニティ~
【活動記録】第34回 オンラインで復活!人の心を動かすVizを作ろう~前編~
【活動記録】第35回 オンラインで復活!人の心を動かすVizを作ろう~後編~
対象の記事を開いてメモ帳にコピー&ペーストで準備しました。(noteの記事をテキストで出力する機能があればと思いましたが、そのような機能は見つからなかったため、今回は手動でがんばりました。)
4.PythonとMecabで形態素解析
プログラムは、こちらのサイトを参考にしました。
インストールしたAnacondaを起動して、Juputer Labを開きます。

# Mecabのインポート
import MeCab
import re
# ファイル読み込み
file = r'C:\読み込み対象のファイル保管先\ファイル名'
with open(file,encoding='utf-8') as f:
text = f.read()
# 空行の削除
text = re.sub('\n\n', '\n', text)
print(text)# Mecab で形態素解析
tagger = MeCab.Tagger("-Ochasen")
result = tagger.parse(text)
result_lines = result.split('\n')
result_words = []
words = []
for result_line in result_lines:
result_words.append(re.split('[\t,]', result_line))# csv形式で出力
import csv
csv_path = r"C:\出力先フォルダ\出力ファイル名"
with open(csv_path, 'w', newline='', encoding='UTF-8') as file:
writer = csv.writer(file)
writer.writerow(["分割タイプ1", "分割タイプ2", "分割タイプ3","品詞"])
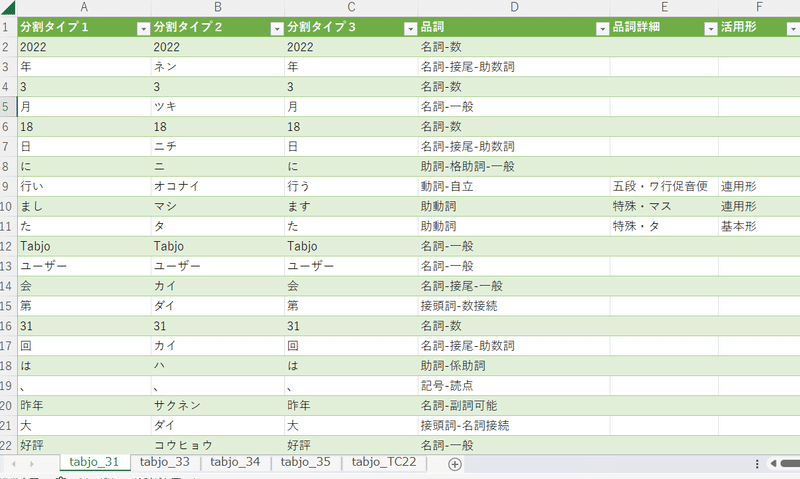
writer.writerows(result_words)出力ファイルはこちらです。

出力したファイルをExcelに読み込みます。
5.Tableauでワードクラウド
それでは、Tableauでワードクラウドを作成してみましょう。
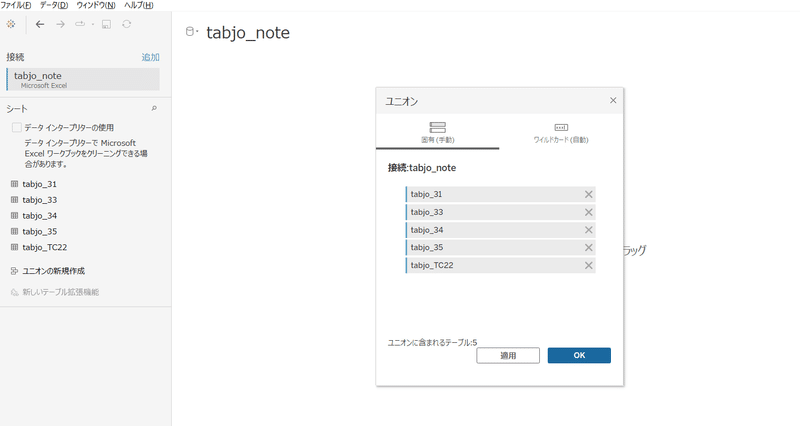
まずは、4で作成したExcelに接続します。ユニオンで縦に結合します。
今回は「名詞」に絞って、どのようなワードが頻出しているのかを分析したいと思います。「品詞」をフィルターにドラッグ&ドロップをして、「名詞-一般」にチェックを入れます。
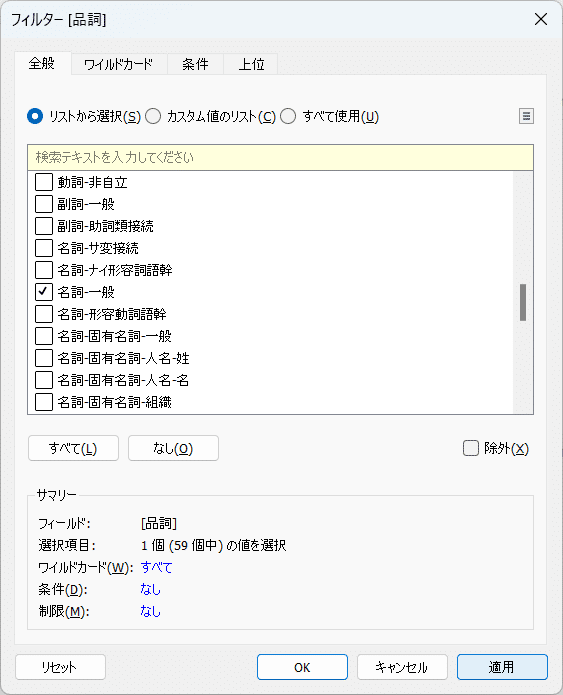
分割した単語をマークの「テキスト」にドラッグ&ドロップで配置します。
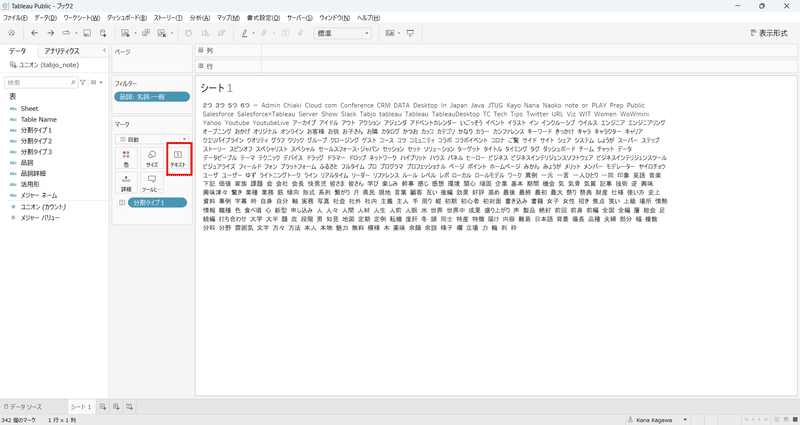
次に、同じディメンションを「サイズ」にドラッグ&ドロップします。
そして、「メジャー」→「カウント」で単語の出現回数をカウントします。
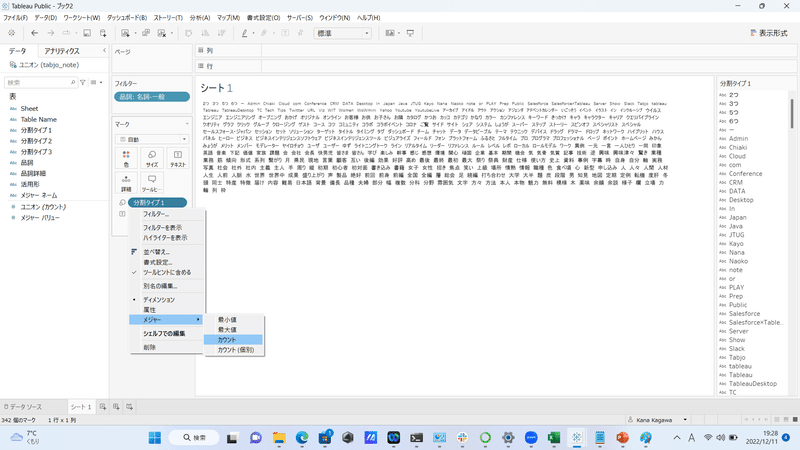
すると、グラフがツリーマップになるので、マークタイプを変更します。

マークタイプを「自動」から「テキスト」に変更します。

これでワードクラウド表現の完成です。
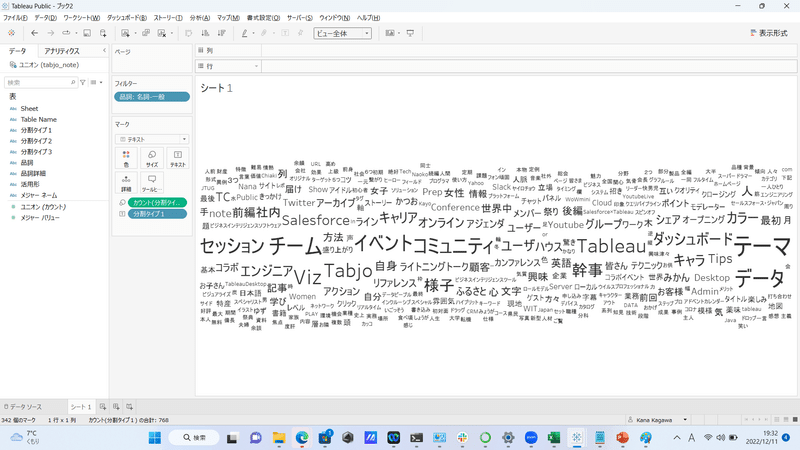
単語の数が多く、見づらさを感じますね・・。
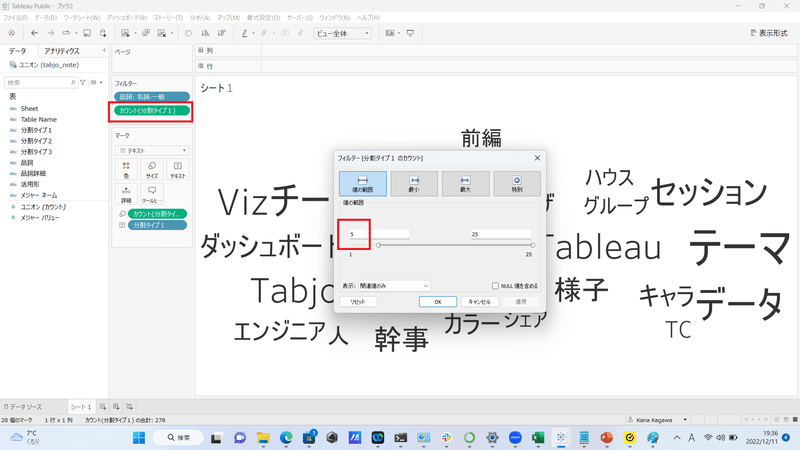
単語の出現回数をカウントしたものをフィルターにドラッグ&ドロップして、Viz上に表示させる単語を絞り込みます。ここでは最小の出現回数を5回に設定しました。
少し見やすくなりましたね!
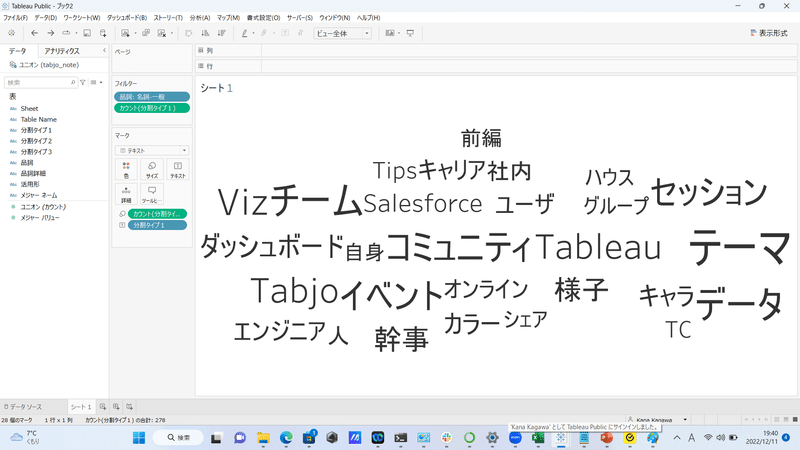
まだ、出現回数の多さが分かりづらいので、単語の出現回数をカウントしたものを色にドラッグ&ドロップしてみましょう。
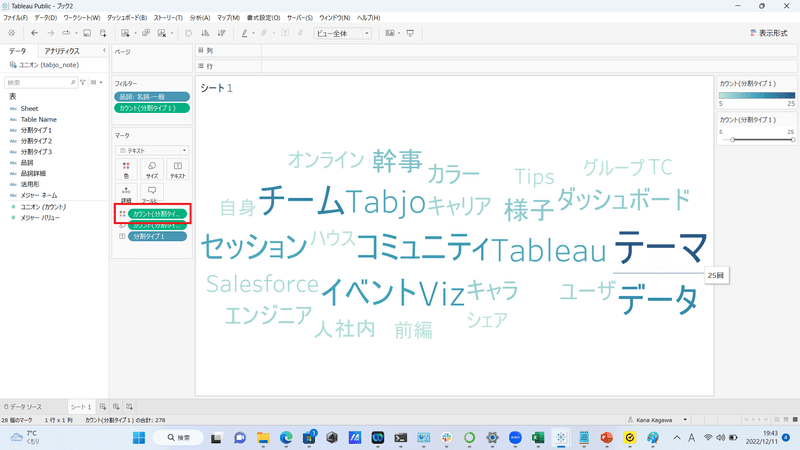
「テーマ」という単語が25回で最も数多くnoteの記事に出てきていることがわかります。
「Tableau」や「ダッシュボード」という単語が1位、2位を争うのかな、という予想でしたが、「テーマ」が1位に輝くという予想外の結果でした!!
出現回数の多さを比較するなら、棒グラフがVisual Best Practiceでは?!という議論は置いておいて、今回は、ワードクラウド表現を文章を単語に分割するところから実践してみました!
参考資料
Windows10環境のPython3でMeCabを使えるようにするまで – IT Learning (obenkyolab.com)
[解決!Python]エンコーディングを指定して、シフトJISなどのファイルを読み書きするには:解決!Python - @IT (itmedia.co.jp)
この記事が気に入ったらサポートをしてみませんか?