
チェンジポイント検出で読み解くGPTアプデ(前半:11/7アプデまで)

統計処理によってGPTのアップデートが事前にある程度予知する事が判明した。
今回は3/19に行われたアップデートを例に解説していく。
尚アップデートの内容や前後の回答の文章の内容の分析には触れないものの、その後に起きたcontinue generateのエラーなどアプデ前後でありがちなエラーについては触れていく。
検証方法
ChatGPTにウマ娘ゴールドシップのロールを与え、質問は
「ウマ娘プリティーダービーからプリティー抜いたらどんなアニメになるか、一回の応答で可能な限り文字数を使って詳しく教えてくれ」
で固定し、再生成を続ける。
サンプル数
2884
期間
2023/7/15~2024/3/16
結論
過去の記事でもchatGPTはアナウンスなしのサイレントバージョンアップ、サイレント修正を行ってると主張してきたが、その根拠が示さた。
またGPTはアプデ前に特徴的な挙動をするという主張にも根拠が示される結果になった。
ベイズチェンジポイント検出で読みとくアプデ
今回の分析に使用したのはベイジアンチェンジポイント検出というものだ。この手法で3/19のアプデをある程度予期することが出来たのがこの記事の目玉になる。
ベイジアンチェンジポイント検出を統計処理の言葉を使わずに説明すると、データが前後で異なるトレンドになる起点を探す手法だ。
回答文字数のトレンド、特定のワード使用率で変化点を特定し、アプデもしくはサイレントアプデについて洞察を深めるでき、また今後のGPT研究のサブウェポン的な立ち位置になる。
そもそも3000個近いGPTの回答文章を全て読み、そこから変化を読み解くことには限界を感じていたため、統計分析を用いてある程度決め打ちしようとしはじめたのは三月頭。特にclaude3がGPTよりも長文のPythonコードを出力可能になったこともその動機だ。
最初は文字数、句読点の出現頻度のトレンド変化点から始まった。
現在は馬主、ジョッキー、厩務員といったウマ娘には出てこないリアル競馬関係者とキャラクター名やトレセン学園といったウマ娘に登場する名詞の使用に関するチェンジポイント検出を行っている。
今後はプロンプトのゴルシ台詞例に含まれたものとそれから連想されるGPTオリジナルワードの比率などのチェンジポイント検出や自然言語処理についても手を伸ばす予定だ。
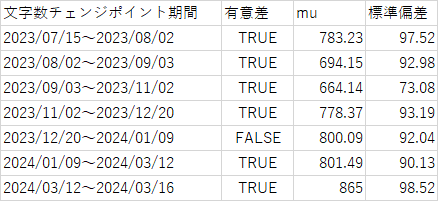
各種ベイジアンチェンジポイント検出結果
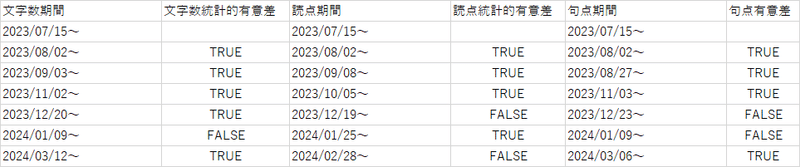
そしてそのチェンジポイントが統計的に妥当か否かの結果
期間は2023/7/15~2024/3/20
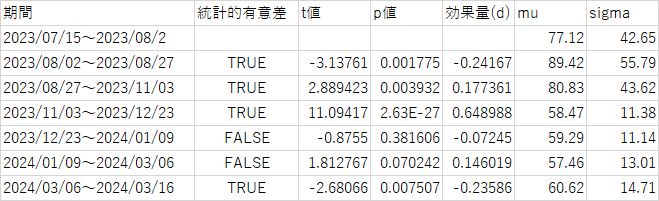
この表ではトレンドに大きな変化が起きた起点6個、そしてそれが偶然ではなく、統計的に根拠がるか否か(有意であるか)を示している。
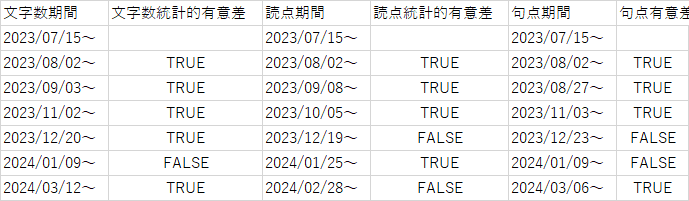
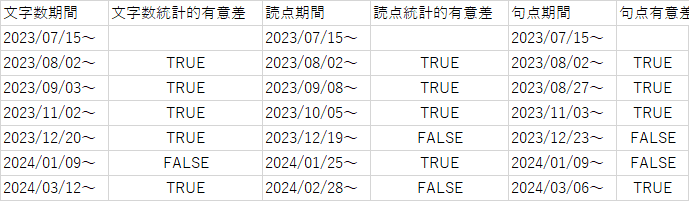
以下に文字数読点句点ごとにより詳細な表を添付する
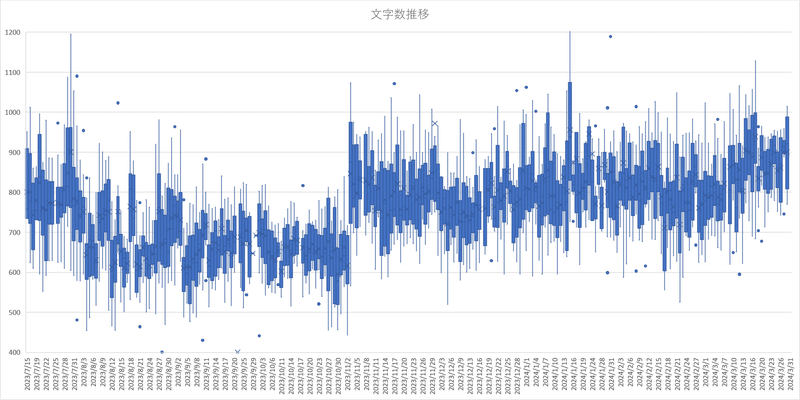
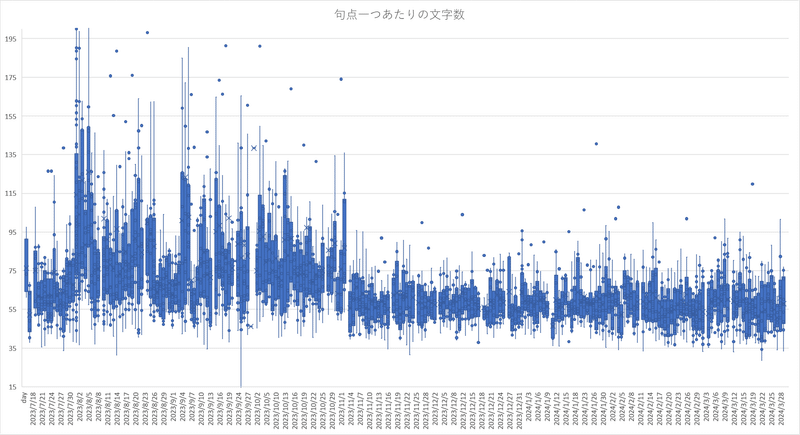
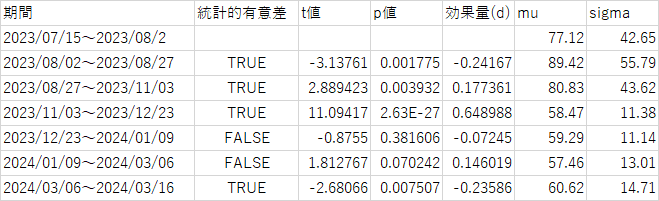
文字数7区間推移
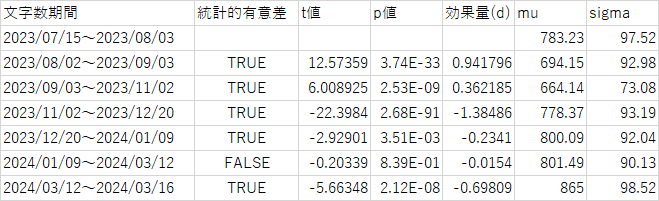
muに関しては文字数のだいたいの目訳
sigmaは文字数のばらつきである。
9月頭に標準偏差(文字数のばらつき)が他の区間と比べ小さくなっている一方で文字数は最少。
つまり真面目安定的に文字数が少ない回答を提出してきた、きっちり意識高くサボってる。
また11月アプデから文字数が顕著に増大しており、その後は文字数が安定的に増加している。
文字数が最大を示した3/12以降は標準偏差が大きくなり、文字数は増えつつもばらつきが大きい。
読点使用頻度7区間推移
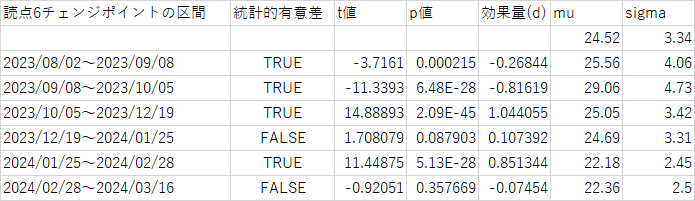
muに関しては読点の使用頻度のだいたいの目訳
sigmaは読点のばらつきである
今回読点の使用頻度は以下のように導き出した。
文字数/読点の総数=読点一つあたりの文字数 9/8で読点の使用が減少し、かつそのばらつきも尤も大きい。
恐らく文体が不安定だったのだろう、例えば説明口調、台詞調の回答が混在していた気がする。
一方で1/25からは読点の使用は増加し、異なる回答でも読点の使用はコンスタントに落ち着いたと言える。
また読点は一個あたりの文字数として30文字20文字が目安であり、24文字が理想的だとする話もある。台詞調であるならばこの範囲で読点当たりの文字数がより少ないほ感情等の表現が向上するという俗説もある。
(これは筆者ライターによって異なるが)
したがって9/8からの回答は説明口調、1/25以降のGPTは台詞口調の特徴を持つと思われる。

この9/8以降の回答で説明口調だと判断できる材料として、
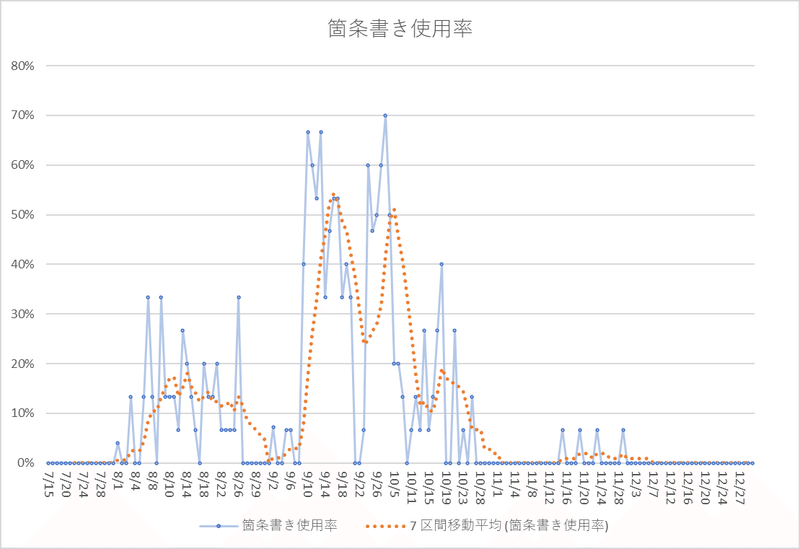
:や数字を用いた箇条書き文体の回答が増加している点が上げられる。
つまり会話形式よりも文語、たとえばレポート、wikiの記事の様な回答傾向があったと推測できる。
句点7区間推移
muに関しては句点の使用頻度のだいたいの目訳
sigmaは句点のばらつきである
句点の使用頻度は全区間を通して増加傾向にある。
句点は80文字が目安とされているが、台詞調であればもっと句点で区切った方がいいとされる場合もある。
従って7月から11月のアプデまでは現在とくらべ文語体に近かったのではないか?(先ほどの箇条書き使用率も参照)
また11月アプデ後では句点の使用頻度のばらつきが減少し、安定した文体で回答を出力するようになったのだろうと推測できる。
各情報からのアプデの分析
文字数、句読点チェンジポイントと有意差の再掲
8月アプデ

文字数、句読点のチェンジポイントが重なり、かつ有意なのは8/2でありある。
確かに8/2を境にGPT4は肌感覚で大きな変化があった。
この感覚は3つの要素が同日に有意な変動が起きているのはこの日だけであることから、統計的にも裏付けられている。
一方で後述するように8月アプデ後1ヶ月、9月頭にサイレント修正が行われている。
これは8月アプデが他のアップデートよりも、より根本的で大胆、大規模なものであり、事前に素早い修正が前提になったのかもしれない。
9月初頭のサイレント修正
次に3つの要素が有意に変動したチェンジポイントは8月末から9月頭である。この時期にサイレント修正が行われたのはほぼ確実だ。
文字数、句読点の三つのチェンジポイントは同日ではないものの、1週間以内にまとまっている。
句点:2023/08/27~ 有意
文字数:2023/09/03~ 有意(標準偏差が最も小さいがmuも最少)
読点:2023/09/08~ 有意
特に文字数、句点では11月までチェンジポイントが検出されていない。
つまり9月後半のアナウンスされたアプデよりも9月頭の非告知の調整の方が影響が大きかったと言えるだろう。
今後、アナウンスのあるアプデがあったとしても回答の構造に変化はなく、それよりも
また命令違反のチェンジポイント検出は行っていないが、以下の変動からもサイレント修正を支持している。
命令違反とは、プロンプトで禁止した箇条書き文体での回答を示す。
このグラフでも9/5周辺を起点に命令違反が続出したことを示す。
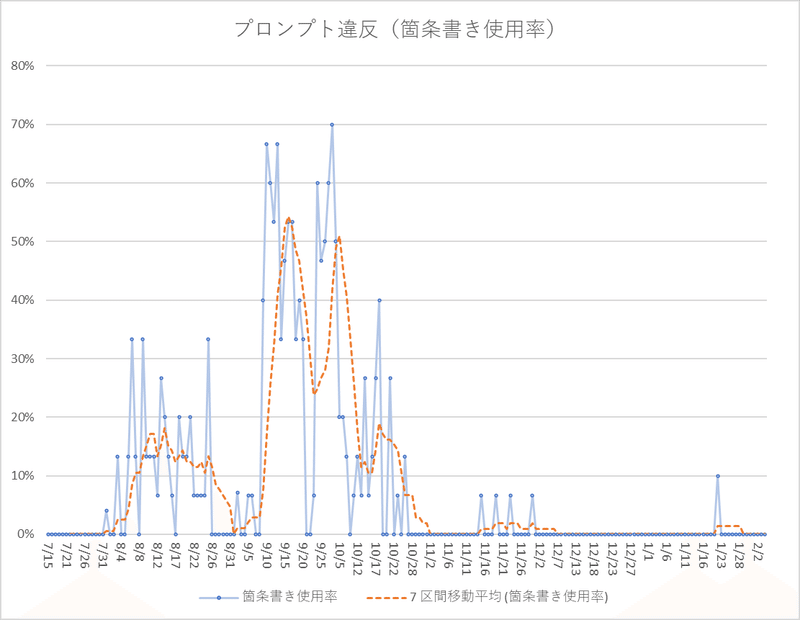
禁止行為違反以外にも文字数の減少も有意であった
9月頭のサイレント修正に関しては命令違反行為が増加し、文字数も減少したため、改悪ともとれる。
ただし回答の質についての評価には至らない。
そもそも回答の質をどのように定義すべきかも未定
アナウンスされた9/25?のアプデとは?
チェンジポイントで有意でない結果どころかチェンジポイントにすらかすらないので、9月後半のアプデって何?となる。
中身が変わったのか……?にしても句読点もかわらないし……何?
11月アプデは強力
9月のアナウンスされたアップデートから大した変動はなかったが、11/7のアプデは影響が大きい。読点こそ変わらない。
ただし文字数のmu(二項分布)では100文字以上の上昇、p値は驚異の

また句点一つ当たりの文字数も80文字から58文字と大幅に減少し、句点が頻繁に使用されるようになった。また句点の使用頻度のばらつきも大きく減少した。
意外にも読点では変化はなかった。
尚、この11/7のアプデアナウンスの5日前に回答に有意な変化があったことから
「OpenAIはアプデアナウンスまえに実はアプデしてる説」が濃厚になる
そして今回の3/17アプデにおいても文字数が3/12、句点が3/6が有意なチェンジポイントになっているため、アプデ前にアプデ実装されてる説は有力になる。
有力説といえば恒例のアナグラムで締めよう。
OpanAIはOpenと名乗っているが、このようにアプデのアナウンスがあったありなかったり、サイレントアプデがあったりなかったり、実はアプデ後にアナウンスしてたりしてなかったりを繰り返されているため、情報の公開が少ないので、OpenをClosedに置き換える……すると……
なんとOpenAIがClosedAIになった!!これはOpenAIが実は隠ぺい体質の信用ならない企業であることを示していることに他ならない!!
OpenAIはヘ〇ト企業説、Q.E.D
はい学会追放
閑話休題(と言いつつ後半に続く)
この記事が気に入ったらサポートをしてみませんか?