
これからの「総合職」「文系」に求められるデータ活用力

本投稿では、データ分析のプロジェクト経験を踏まえ、データの重要度が増していく中で、今後の事業マネージャー(日本での総合職)に求められる役割・能力を考えます。
(目次)
0. はじめに
1. Uberにみるデータ活用のインパクト
2. 事業マネージャーに求められる役割
3. 何を学ぶべきか
0. はじめに
ビッグデータ・AIのバズワードとしての知名度は高い一方、あまり理解せずに言葉を連呼している人や、自身の業界との繋がりが見えず、敷居が高そうなので手をつけていない人はまだ多いのではないかと感じます。
先日も、大手コンサルティング会社の方が、官公庁におけるデータ分析人材の育成方法に関してヒアリングに来られました。
データ活用が企業の競争力に影響を及ぼす領域は着実に広がってきており、データサイエンティストの需要は急増する一方で、データ活用はデータサイエンティストだけに任せていればいいものではありません。
1. Uberに見るデータ活用のインパクト
スマホやセンサーなどの電子・通信機器の普及で、ここ数年で色々な産業の業界構造が大きく変化しました。
個人的に如実に感じるのが、自動車業界の変化です。自動運転・コネクティッドカー・EV化による部品の減少など話題に事欠きませんが、イメージしやすい変化として「所有からサービスへ」の変化があります。
1つは、レンタカーをより安く・柔軟にしたカーシェアの拡大。もう1つは、Taxiをより便利にしたUber / Lyftなどの配車サービスの拡大。
後者については、NYではGett / Viaといった相乗りサービスも含めると数多くのサービスが存在し、学生でも多くが頻繁に利用しています。業界の王者、Uber / Lyftも相乗り機能の改善に注力しており、自動運転の実用化と相まって、今後更に便利になると考えられます。
そして、今後、配車サービスが拡大すると、車はより嗜好品からコモデティに近づき(Taxiに乗る人は車のデザイン・車種をそれほど気にしない)、買う人の数が激減することはメーカー側の交渉力を大きく下げることになるでしょう(Taxi会社は1車種に絞ってまとめて買うため交渉力が強い)。
さて、そのUber / Lyftですが、彼らは徹底的にデータを活用しています。
下記リンクのように、Taxiのような基本価格の設定はありながらも、場所と需要に応じて追加料金を課すことで、ユーザーの許容する金額(Willingness to pay)の上限までチャージすることを狙っています。
一方、ユーザーは下画面のように他社価格との比較や相乗り(POOL)との比較が容易にできてしまう上に、ドライバー達は他配車サービスとも契約しており必要十分な報酬を渡す必要があるため、利益最大化のためには、それらの売上・コスト・確率分布を考慮して計算する必要があります。
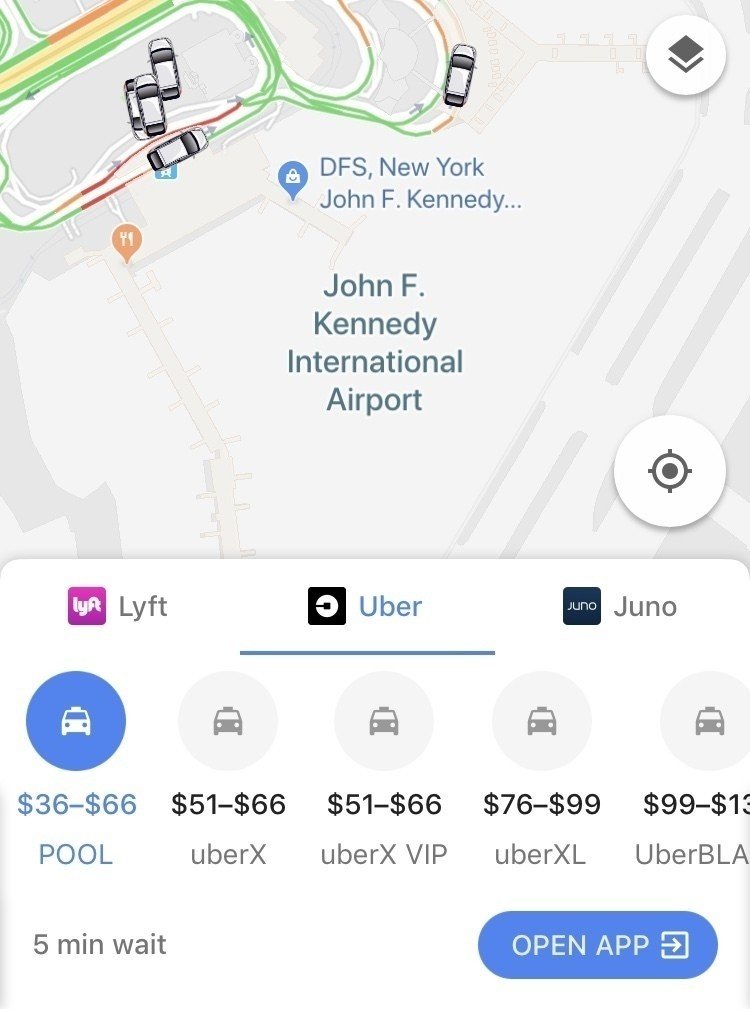
その他、配車の最適化、相乗り時の到着時間予測の精緻化、自動運転と人力運転の車両数の最適化など、データ活用の余地は様々に想像できます。
2. 事業マネージャーに求められる役割
このようにデータ活用がプラスαから競争に必須のものへと変化し、データサイエンティストが増える中で、事業マネージャーに求められる役割は、「課題の定義」と「データを踏まえた意思決定への意識」だと思います。
A. 課題の定義
少し古いですが、データ分析について話すときによく参照される事例の1つとしてNetflix Prizeがあります。これは06-09年に行われたコンペティションで、Netflixは自社データを公開の上、各ユーザが映画に付ける評価を事前に予測するアルゴリズムを募集し、100万ドルの賞金をかけました。
近年では、Kaggleというプラットフォームが有名で、数多くの企業から多額の報酬とともにデータセット・課題があげられており、データサイエンティストの卵からプロまでが切磋琢磨しています。
一方、データサイエンティストにこういった依頼をするにも「解くべき課題が何か」というのは、ビジネスの現状を深く理解した人間が明確に定義する必要があります。例えば「利益の上げ方を知りたい」では明らかに曖昧ですし、「売上の上げ方を知りたい」「コストの削り方を知りたい」でも曖昧なのは見ての通りです。
対競合でみても、外から見て明らかなサービスの高度化は話題に上がりやすく、真似や発想の起点にしやすいですが(Amazon Goなど)、データ分析の取り組みは効果は高いものの外部から見えないため、より自社の事業構造・ミッションに合わせて解くべき課題を設定する能力が問われると思います。
B. データを踏まえた意思決定への意識
仕事でデータ・サイエンティストと接した際に、「これ、分析したら何か出ますよ」と言われるものの、明らかに何も示唆が出そうにない、という経験が何度かありました。当時の私のデータ分析に関する知識不足の可能性も大いにありますが、米国でデータサイエンティストの友人達と話した結果、根本にある意識の違いが見えてきました。
データサイエンティストの「何か出る」というのは「統計的に有意な示唆が何か出る」だが、ビジネスに必要なのは「アクション・意思決定につながるデータが何か出る」ことだ、という違いです。
この「意思決定の意識」を理解していないと、「とりあえず発注して分析してもらい、なんとなく何か分かったが、何して良いかわからない」という悲惨な事態になります。
例えば、細かい話ですが、Machine Learningのなかに、K-means clusteringという対象者のグルーピングをする手法があります。これを使うと、「お店での過去の購入履歴を元に、類似の性質を持つグループに分ける」ことなどが可能です。
ここで、いくつのグループに分けるべきか?ということが問題になります。データサイエンティストはSilhouettingという手法を用いて「数学的に良い」グループ数を算出することが可能ですが、これは別に「販促上の打ち手を分けるのに最適な」グループ数というわけではないので、それは事業に詳しい人間が考える必要があります。
もちろん、優秀なエンジニアがUXやビジネスを理解するのと同様に、優秀なデータサイエンティストはこういったことを理解していますが、コストや効率を考えると、依頼する側も共通認識を持っている必要があります。
3. 何を学ぶべきか
上記の通り、最も重要なことは「課題の設定」や「意思決定の意識」などですが、お勉強という観点では、データサイエンティストと会話をする上で、大まかな手法とその意味が分かっている必要はあるかと思います。
以下の表はKDnuggestというサイトでの「よく使う手法」の調査結果ですが、これを見てイメージが湧くかは、1つの指標になると思います。

きちんと各手法の基本を理解したいという方には、コーネルテックでMBA生向けにデータ分析を教える授業での教科書にもなっているData Smartという本を勧めます。
この本は「エクセルの関数でデータ分析の各手法を再現しつつ学ぶ」というコンセプトで書かれており、文系にも非常にわかりやすく(私はド文系です)、英語も平易で読みやすいです。
第1章は戦略コンサルや投資銀行の現場でのモデリングにもよく使われるエクセル関数の説明となっており、第2章以降でそれを実際に使用していくため、エクセルでの分析スキル自体の習得にも役立ちます。
各手法の意味や処理の仕方も細かく書かれており、データ分析を学ぶ第一歩として最適かと思います。
この記事が気に入ったらサポートをしてみませんか?