マッチングサイトpython集計分析その2~ラブルームのチャット内容をWEBスクレイピングで自動取得する~

前回の記事はこちら
ラブルームのチャット内容を分析するにあたって、Pythonでラブルームのチャットルームにアクセスし、チャット内容を自動でCSVに落としてくるスクリプト作成とAWSでの環境構築を行った。
とは言っても、ネットで見つけた偉大な先人たちが公開しているスクリプトをコピペして若干のチューニングを加えて作った程度のものなので、無駄な処理もだいぶ入っている気がする。
特にPythonを勉強する方は本文中に記載した先人たちの記事を参考リンクから見ていただく方が良いかと思う。
あと、逆にPythonに全く興味がない方はその4以降くらいから読むのが良いかもしれない。
1.ラブルームのソースコードから会話内容を取得するPythonのスクリプトを作成する。
スクリプトはGoogle ColaboratoryにSeleniumとChromeDriverをインストールした上で、以下のようなスクリプトを作成し、動かした。
参考リンク:【Python】WebスクレイピングでYahoo!ニュースのコメントを取得する
#Seleniumのインストール
!apt-get update
!apt install chromium-chromedriver
!cp /usr/lib/chromium-browser/chromedriver /usr/bin
!pip install selenium
#ChromeDriverのインストール
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
driver = webdriver.Chrome('chromedriver',options=options)
##ここからラブルームに特化した記載内容。
#name属性を基にvalue属性を取得
def valuefromname(element,name):
result = ""
elem = element.find_element_by_name(name)
result = elem.get_attribute("value")
return result;
#対象要素のvalue属性値取得
def print_roominfo(no):
room_rows = driver.find_elements_by_css_selector("tr.roomcol")
for room_row in room_rows:
#guid取得
guid = valuefromname(room_row, "guid")
#room_id取得
room_id = valuefromname(room_row, "room_id")
#genre_key取得
genre_key = valuefromname(room_row, "genre_key")
#性別取得
room_elements = room_row.find_elements_by_tag_name("td")
sex = room_elements[3].text
#紹介文取得
introduction = room_elements[5].find_elements_by_tag_name("span")[-1].get_attribute("textContent") #display:noneの要素も含める場合は"textContent"
no += 1
room_url = 'http://chat.shalove.net/PublicRoom?guid={}&room_id={}&genre_key={}'.format(guid, room_id,genre_key)
print('{:0=3}\t{}\t{}\t{}'.format(no, room_url, sex, introduction))
nos.append('{:0=3}'.format(no))
guids.append(guid)
room_ids.append(room_id)
genre_keys.append(genre_key)
room_urls.append(room_url)
sexes.append(sex)
introductions.append(introduction)
return no
#driverを入れ直す
driver = webdriver.Chrome('chromedriver',options=options)
#空のリスト
nos = []
guids = []
room_ids = []
genre_keys = []
room_urls=[]
sexes=[]
introductions=[]
no = 0
#実行処理
url = "http://chat.shalove.net/g/kanto/vwait/2/pageID/1/"
driver.get(url)
no = print_roominfo(no)
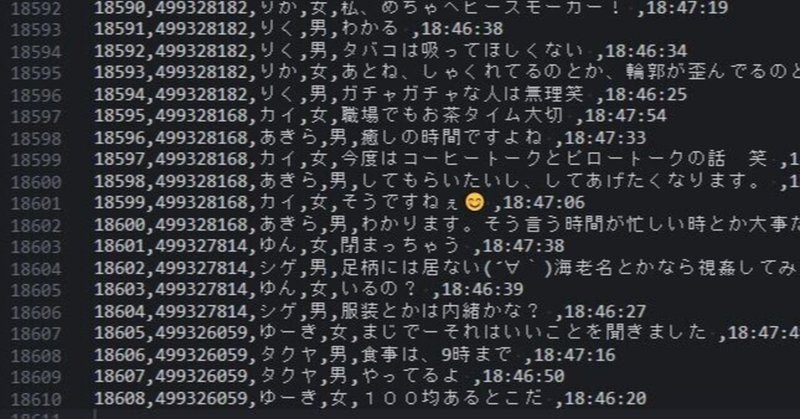
driver.quit()これを動かすと以下のようにチャットルームのURLと紹介文などを一覧で抽出することができる。

pandasでDataFrameにすると、、
import pandas as pd
room_df = pd.DataFrame({'no':nos,'room_url':room_urls,'sex':sexes,'introduction':introductions})
room_df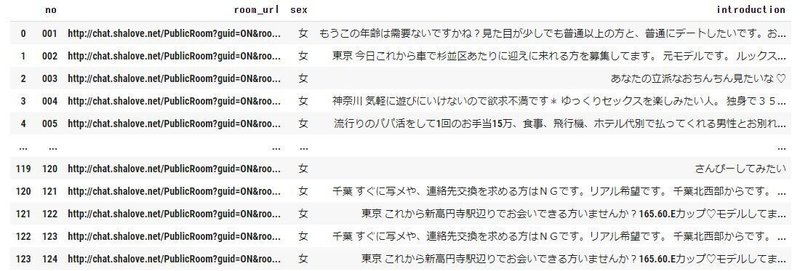
続いて、それぞれのチャットルームのURLの中にアクセスし、チャット内容を取ってくるスクリプトを作る。今回はprintでデータの取得状況は確認せず、とりあえずDataFrameまで成形する形にしている。
#各チャットルームから要素を抽出する処理を関数化。
def chatlog(room,chat_no):
room_idx= room.find("room_id=") # 半角空白文字のインデックスを検索
chat_room_id = room[room_idx+9:room_idx+17] # スライスで半角空白文字のインデックス+1以降を抽出
driver.get(room)
chat_rows = driver.find_elements_by_css_selector("div.hello")
for chat_row in chat_rows:
#name取得
chat_elements = chat_row.find_elements_by_tag_name("td")
chat_name = chat_elements[0].text
if chat_elements[0].find_elements_by_tag_name("b"):
if chat_elements[0].find_elements_by_tag_name("font"):
chat_sex = "female"
else:
chat_sex = "male"
else:
chat_sex = "none"
chat_sentence = chat_elements[2].text[:-12]
chat_time = chat_elements[2].text[-10:]
chat_no += 1
# print('{}\t{:0=3}\t{}\t{}\t{}\t{}'.format(chat_room_id, chat_no, chat_name, chat_sex, chat_sentence, chat_time))
chat_room_ids.append(chat_room_id)
chat_nos.append('{:0=3}'.format(chat_no))
chat_names.append(chat_name)
chat_sexes.append(chat_sex)
chat_sentences.append(chat_sentence)
chat_times.append(chat_time)
return chat_no
#driverを入れる
driver = webdriver.Chrome('chromedriver',options=options)
#空のリスト
chat_room_ids = []
chat_nos = []
chat_names = []
chat_sexes = []
chat_sentences = []
chat_times = []
chat_no = 0
#各ルームに対して同じ処理を行う
for room_url in room_urls:
chatlog(room_url, chat_no)
import pandas as pd
room_df = pd.DataFrame({'room_id':chat_room_ids, 'chat_no':chat_nos,'chat_name':chat_names, 'chat_sex':chat_sexes, 'chat_sentence':chat_sentences, 'chat_time':chat_times})
room_df
これでチャットルームの情報が一覧化されたDataFrameとチャットの会話内容が一覧化されたDataFrameの2種類を作る事ができた。
2.書いたスクリプトを一定時間ごとに動かすための環境をAWSに構築する。
チャットを追いかける以上「1」で作ったスクリプトが自動で起動するのがマストになってくるのだが、GoogleColaboratoryはランタイムが自動で切れるという壁に当たってしまった。このままだと単発でチャット内容は取得できても更新についていくことができない。
そこで以下のリンクを参考にAWS上にCloud9の環境を構築し、一定時間ごとにチャット内容を取得するようにスクリプトを動かすことにした。(ちなみにこれは無料利用枠の中に収まる範囲だった。Amazonってすごいなぁ。)
参考リンク:Python+AWS Cloud9で自動スクレイピング→LINEに更新通知でMENSAの入会テストに申し込んだ話
ただ、ここで「1」のスクリプトを作る時にインストールしたSeleniumとChromeDriverをAWS上で動かすことができずに死亡した。いや、方法はあるにはあるっぽいのだが、初心者には先人たちの言葉が全く理解できない。。
色々調べてみると、同じくスクレイピングによく使われるライブラリであるBeautifulSoupであればデフォルトで用意されているのでインストールは比較的簡単そう、ということが分かった。
参考リンク:Layerが用意されているライブラリ一覧
参考リンク:AWS Cloud9 を使用して、外部ライブラリとともに Lambda 関数をデプロイするにはどうすればよいですか?
という訳で一度書いたスクリプトをBeautifulSoup用に以下のように修正した。
ちなみに、ラブルーム側のサーバに負担をかけないようにループは最低90秒の間隔、チャットルームURLへのアクセスは最低1秒の間隔を設定した。
あとは、AWSを動かすときに変数宣言周りで色々とエラーが出たので「global」を入れるなどして無理やり動かした(未だによく分かっていない笑)。
##このスクリプトの実施前に参考リンクのやり方で「beautifulsoup4」「requests」「pandas」をデプロイした。
#ライブラリのインポート
import requests;
from bs4 import BeautifulSoup;
import line_notice as ln # linePUSH用モジュールをインポート。
#始めに空のDataFrameを作成。room用のdfとchat用のdfの2種を作成。
import pandas as pd
import time
import csv
room_df = pd.DataFrame(index=[], columns=['room_id','sex','age','introduction'])
chat_df = pd.DataFrame(index=[], columns=['room_id','chat_name','chat_sex','chat_sentence','chat_time'])
#空のリスト(room)
nos = []
guids = []
room_ids = []
genre_keys = []
room_urls=[]
sexes=[]
ages=[]
introductions=[]
no = 0
#空のリスト(chat)
chat_room_ids = []
chat_nos = []
chat_names = []
chat_sexes = []
chat_sentences = []
chat_times = []
chat_no = 0
#対象要素の属性値取得
def print_roominfo(no):
global soup
room_rows = soup.select("tr.roomcol")
for room_row in room_rows:
#guid取得
guid = room_row.find('input', {'name':"guid"})['value']
#room_id取得
room_id = room_row.find('input', {'name':"room_id"})['value']
#genre_key取得
genre_key = room_row.find('input', {'name':"genre_key"})['value']
#性別取得
room_elements = room_row.select("td")
sex = room_elements[3].text
#年齢取得
age = room_elements[4].text
#紹介文取得
introduction = room_elements[5].select("span")[-1].text
no += 1
room_url = 'http://chat.shalove.net/PublicRoom?guid={}&room_id={}&genre_key={}'.format(guid, room_id,genre_key)
# print('{:0=3}\t{}\t{}\t{}'.format(no, room_url, sex, introduction))
nos.append('{:0=3}'.format(no))
guids.append(guid)
room_ids.append(room_id)
genre_keys.append(genre_key)
room_urls.append(room_url)
sexes.append(sex)
ages.append(age)
introductions.append(introduction)
return no
def chatlog(chat_room_id,room,chat_no):
# レスポンス取得
res_chat = requests.get(room)
# BeautifulSoupで成形
soup = BeautifulSoup(res_chat.content, "html.parser")
chat_rows = soup.select("div.hello")
for chat_row in chat_rows:
#name取得
chat_elements = chat_row.select("td")
chat_name = chat_elements[0].text
if chat_elements[0].select("b"):
if chat_elements[0].select("font"):
chat_sex = "女"
else:
chat_sex = "男"
else:
chat_sex = "なし"
date_index = chat_elements[2].text.rfind("(")
chat_sentence = chat_elements[2].text[:date_index-1]
chat_time = chat_elements[2].text[date_index+1:-1]
chat_no += 1
# print('{}\t{:0=3}\t{}\t{}\t{}\t{}'.format(chat_room_id, chat_no, chat_name, chat_sex, chat_sentence, chat_time))
chat_room_ids.append(chat_room_id)
chat_nos.append('{:0=3}'.format(chat_no))
chat_names.append(chat_name)
chat_sexes.append(chat_sex)
chat_sentences.append(chat_sentence)
chat_times.append(chat_time)
time.sleep(1)
return chat_no
def main():
while True:
t1 = time.time()
url = "http://chat.shalove.net/g/kanto/vnonpub/2/vwait/2/pageID/1/"
# レスポンス取得
res_room = requests.get(url)
if res_room.status_code != 200:
ln.line_notify("エラー発生。")
break
else:
# BeautifulSoupで成形
global soup
soup = BeautifulSoup(res_room.content, "html.parser")
global no
no = print_roominfo(no)
t2 = time.time()
elapsed_time = t2-t1
print(f"room後経過時間:{elapsed_time}")
#各ルームに対して同じ処理を行う
global room_ids
global room_urls
global chat_no
for room_id, room_url in zip(room_ids, room_urls):
chatlog(room_id, room_url, chat_no)
t2 = time.time()
elapsed_time = t2-t1
print(f"chat後経過時間:{elapsed_time}")
#DataFrameへの追加・重複行の削除
global room_df
global sexes
global ages
global introductions
new_room_df = pd.DataFrame({'room_id':room_ids, 'sex':sexes, 'age':ages,'introduction':introductions})
room_df = pd.concat([room_df, new_room_df])
room_df = room_df.drop_duplicates().reset_index(drop=True)
global chat_df
global chat_room_ids
global chat_names
global chat_sexes
global chat_sentences
global chat_times
new_chat_df = pd.DataFrame({'room_id':chat_room_ids, 'chat_name':chat_names, 'chat_sex':chat_sexes, 'chat_sentence':chat_sentences, 'chat_time':chat_times})
chat_df = pd.concat([chat_df, new_chat_df])
chat_df = chat_df.drop_duplicates().reset_index(drop=True)
room_df.to_csv("room.csv")
chat_df.to_csv("chat.csv")
#空のリスト(room)
nos = []
guids = []
room_ids = []
genre_keys = []
room_urls=[]
sexes=[]
ages=[]
introductions=[]
no = 0
#空のリスト(chat)
chat_room_ids = []
chat_nos = []
chat_names = []
chat_sexes = []
chat_sentences = []
chat_times = []
chat_no = 0
t2 = time.time()
elapsed_time = t2-t1
print(f"DF後経過時間:{elapsed_time}")
wait_time = 90 - elapsed_time
if wait_time > 10:
time.sleep(wait_time)
else:
time.sleep(10)
t2 = time.time()
elapsed_time = t2-t1
print(f"最終経過時間:{elapsed_time}")
if __name__=="__main__":
main()ちなみにサーバが503などを返してきた場合にLINEで通知されるように下記も合わせて実装した。これも偉大な先人の参考リンクからコピペした。
import requests
token = "LINE用のトークン"
def line_notify(message):
line_notify_token = token
line_notify_api = 'https://notify-api.line.me/api/notify'
payload = {'message': message}
headers = {'Authorization': 'Bearer ' + line_notify_token}
requests.post(line_notify_api, data=payload, headers=headers)
def main():
line_notify("TEST")
if __name__=="__main__":
main()その結果、ついにスクリプトの自動実行が動き出し、1万行以上のCSVファイルを生成することに成功した。
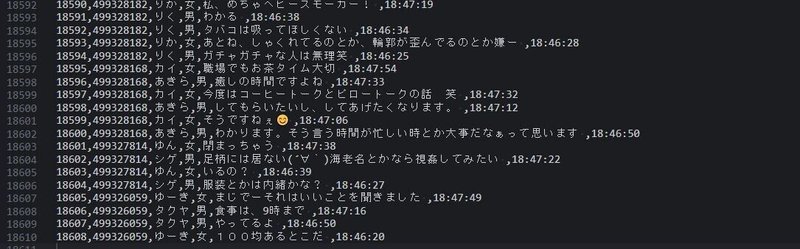
要約すると、こんな感じだが、途中発生した回り道や行き止まりで長い時間を使ってしまい、気づくとGWはこのスクリプト作成と環境構築で終了していた。
次回は抽出したデータの整備について記載していく。
この記事が気に入ったらサポートをしてみませんか?