マッチングサイトpython集計分析その3~ラブルームで取得したチャット内容を分析用に整備する~

前回の記事はこちら
今回は、前回スクレイピングで取得したデータから分析用のDataFrameを作成したい。最後に連絡先を交換したチャットの比率を確認してみた。
1、チャット情報とルーム情報を結合する
GWを全て費やしてとりあえずラブルームのチャット内容を自動抽出して以下のような形式の10万行程度のCSVファイル(chat.csv)が得られた。

同時にチャットルームの一覧が載っている3,000行ほどのCSV(room.csv)も合わせて抽出したので、この2つを使って分析用のDataFrameを作成していきたい。

なお、分析の作業は比較的使い勝手の良いGoogle Colaboratoryを使うことにした。
#pandasのインポートとcsvの読み込み。
import pandas as pd
chat_df = pd.read_csv("/content/chat.csv",index_col=0)
room_df = pd.read_csv("/content/room.csv",index_col=0)まずはchat_dfからroom_dfにルームオーナーの名前を追加してみる。カラムの名前も「owner_name」等に変更。
#room_ownerの名前をroom_dfに記載
owner_df = chat_df[['room_id','chat_sex','chat_name']].drop_duplicates()
owner_df.columns = ['room_id','sex','chat_name']
room_df_owner = room_df.merge(owner_df, on=['room_id','sex'], how='left')
room_df_owner = room_df_owner[['room_id','chat_name', 'sex','age','introduction']]
room_df_owner.columns = ['room_id','owner_name','owner_sex','owner_age','introduction']
display(room_df_owner)
room_idをキーにしてroom_dfとchat_dfを結合する。
#chat_dfとroom_dfをまとめてmaster_dfにmerge
master_df = chat_df.merge(room_df_owner, on="room_id" , how="left")
master_df = master_df.drop_duplicates(subset=['chat_sentence', 'room_id','chat_name','chat_time']) #紹介文変更による重複カウントを削除。
display(master_df)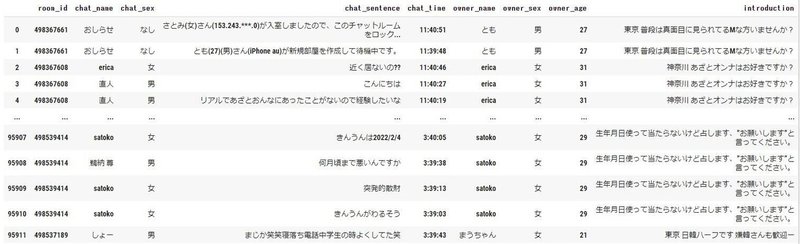
2、チャット日またぎ問題を解決する
ラブルームではチャットの際に時間のみ表示がされる。これが結構問題で、何が起きるかというと23:50にチャットを開始して0:10にチャットを終了するような、日をまたいだチャットをする場合、普通に集計すると開始時間と終了時間が逆になってしまう。
以下のようなやり方で解決したが、行数も多いのであまりうまい方法ではないのかもしれない。
#chat_time列をtime型に変換。
import datetime
if type(master_df['chat_time'][0]) != datetime.time:
master_df['chat_time'] = pd.to_datetime(master_df['chat_time']).dt.time
#room_idごとに並べてchat_timeごとに順番を変更
master_df = master_df.sort_values(['room_id','chat_time'])
#room_idをkeyにしてroom_start情報(日またぎ問題解決前)を各レコードに付与する。
master_df['room_start']=""
master_df.loc[~master_df.duplicated(subset='room_id'),'room_start']= master_df['chat_time']
#空白をNaNに変換し、前の値で埋める。
import numpy as np
master_df['room_start'].replace("", np.nan, inplace=True)
master_df['room_start'].fillna(method='ffill',inplace=True)
#同じようにroom_end情報(日またぎ問題解決前)を付与
master_df['room_end']=""
master_df.loc[~master_df.duplicated(subset='room_id',keep = "last"),'room_end']= master_df['chat_time']
master_df['room_end'].replace("", np.nan, inplace=True)
master_df['room_end'].fillna(method='bfill',inplace=True)
#日またぎ後の判断列を追加
master_df['2days'] = 0
master_df.loc[(master_df['room_start'] < datetime.time(8, 00)) & (master_df['room_end'] > datetime.time(16, 00)) & (master_df['chat_time'] < datetime.time(8, 00)),'2days'] = 1
master_df= master_df.sort_values(['room_id','2days','chat_time'])
#room_idをkeyにしてroom_start情報(日またぎ問題解決後)を各レコードに付与する。
master_df['room_start']=""
master_df.loc[~master_df.duplicated(subset='room_id'),'room_start']= master_df['chat_time']
#空白をNaNに変換し、前の値で埋める。
import numpy as np
master_df['room_start'].replace("", np.nan, inplace=True)
master_df['room_start'].fillna(method='ffill',inplace=True)
#同じようにroom_end情報(日またぎ問題解決後)を付与
master_df['room_end']=""
master_df.loc[~master_df.duplicated(subset='room_id',keep = "last"),'room_end']= master_df['chat_time']
master_df['room_end'].replace("", np.nan, inplace=True)
master_df['room_end'].fillna(method='bfill',inplace=True)
#indexを整える。
master_df = master_df.reset_index(drop=True)
#日またぎのチャットで確認。
display(master_df.loc[master_df["room_id"]==498486629,['chat_time','chat_sentence','room_start','room_end']])
3、ゲスト情報やチャット開始時間などのカラムを追加
ルームオーナーが分かっているのでルームゲストの情報もカラムとして追加。
import numpy as np
#guest情報を入れるためdfを作成。
master_df_guest = master_df
master_df_guest['guest_name'] = ""
#入室アラートからguest_name情報を記入(よく分からんが、直接ではなくSeries型の変数を作ってatで該当のセルを指定してやる必要があるみたい))
master_df_guest.loc[(master_df_guest['chat_sex'] == "なし") & (master_df_guest["chat_sentence"].str.contains('が入室しましたので、このチャットルームをロックしました。')),'guest_name'] = master_df_guest['chat_sentence']
guest_name = master_df_guest['guest_name']
for index, value in guest_name.iteritems():
guest_name.at[index] = value[0:value.find("(")]
#新規部屋の際の情報を記入
master_df_guest.loc[(master_df_guest['chat_sex'] == "なし") & (master_df_guest["chat_sentence"].str.contains('が新規部屋を作成して待機中です。')),'guest_name'] = "ゲストなし"
#退出(強制退出や自主退出)の際の情報を記入
master_df_guest.loc[(master_df_guest['chat_sex'] == "なし") & (master_df_guest["chat_sentence"].str.contains('待機中になります。')),'guest_name'] = "ゲストなし"
#chat_nameからguest_nameに転記
master_df_guest.loc[(master_df_guest['chat_sex'] != "なし") & (master_df_guest['chat_sex'] != master_df_guest['owner_sex']),'guest_name'] = master_df_guest['chat_name']
#空白をNaNに変換し、前の値で埋める。
master_df_guest['guest_name'].replace("", np.nan, inplace=True)
master_df_guest['guest_name'].fillna(method='ffill',inplace=True)
#ついでにowner_nameのNaNを空白にする。
master_df_guest['owner_name'].replace(np.nan, "", inplace=True)
display(master_df_guest)チャット開始時間と終了時間、開始されてから何秒経ったかの列を追加。
import datetime
#room_idとguest_nameをkeyにしてchat_start情報を各レコードに付与する。
master_df_guest['chat_start']=""
master_df_guest.loc[~master_df_guest.duplicated(subset=['room_id','guest_name']),'chat_start']= master_df_guest['chat_time']
#空白をNaNに変換し、前の値で埋める。
master_df_guest['chat_start'].replace("", np.nan, inplace=True)
master_df_guest['chat_start'].fillna(method='ffill',inplace=True)
#同じようにchat_end情報を付与
master_df_guest['chat_end']=""
master_df_guest.loc[~master_df_guest.duplicated(subset=['room_id','guest_name'],keep = "last"),'chat_end']= master_df_guest['chat_time']
master_df_guest['chat_end'].replace("", np.nan, inplace=True)
master_df_guest['chat_end'].fillna(method='bfill',inplace=True)
#chat_secondsを追加。
master_df_guest['chat_seconds']=""
#全てがtime型になっているため、datetime型に変換するSeriesを作成。
chat_time_dt = master_df_guest['chat_time'].copy()
for index, value in chat_time_dt.iteritems():
chat_time_dt.at[index] = datetime.datetime.combine(datetime.date.today(), value)
chat_start_dt = master_df_guest['chat_start'].copy()
for index, value in chat_start_dt.iteritems():
chat_start_dt.at[index] = datetime.datetime.combine(datetime.date.today(), value)
#経過時間のSeriesを生成し、master_df_guestに反映。
chat_sec = (chat_time_dt - chat_start_dt).dt.seconds
master_df_guest['chat_seconds']= chat_sec.values
display(master_df_guest)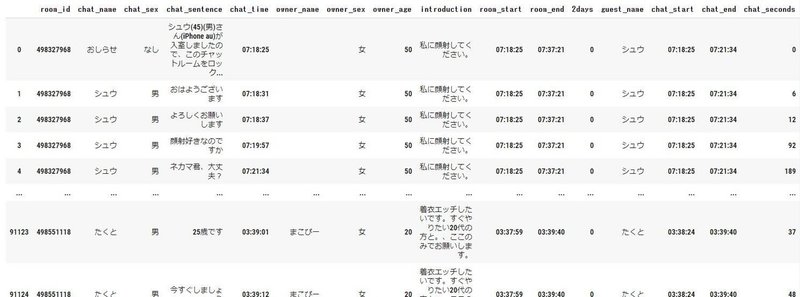
これであらかた使いそうなカラムは用意できた。
4、連絡先を交換したチャットの判別用の列を追加
ラブルームは規約上は連絡先交換NGなのだが、「良い相手が見つかった」となるとカカオトークやSkypeで個別のやり取りに持ち込まれることが多い。先の分析用に連絡先交換を判別できるように列を追加したい。
ラブルームは公開チャットルームのため、連絡先交換は(主に男性が)カカオトークやSkypeのIDをチャットで送った後にチャット履歴をクリアする、というのがお作法になっている。
これを踏まえて、「連絡先交換」を以下のように定義したい。
連絡先交換の定義:「最後の発言から5分以内に"ルーム作成者(待機者)によって発言がクリアされました。"が発生した」かつ「同じチャットルームで新たにペアが発生しなかった」
例えば、具体的には以下のようなやり取りでチャットルームが終わっている場合を連絡先交換とカウントする。

(発言がクリアされるので交換前の細かいやり取りが断絶してしまう場合が多い。)
これを踏まえて、連絡先交換したペアのやり取りが見えるようにマスタを更新して、マスタを完成とした。
#カップルに紐づくdfを新規で作成。
pair_df = master_df_guest[['room_id','owner_name','guest_name','chat_start','chat_end','chat_seconds','chat_sentence']].copy()
#マッチペアの定義:「最後の発言から5分以内に"ルーム作成者(待機者)によって発言がクリアされました。"が発生した」かつ「同じroom_idで新たにpairが発生しなかった」ペア
#発言クリアのdfを作成。ID交換以外でのタイミングでのクリアを回避するために30秒より長く経った場合を条件とする。
room_clear_df = pair_df.loc[(pair_df['chat_seconds'] > 30) & (pair_df['chat_sentence'].str.contains("ルーム作成者(待機者)によって発言がクリアされました。"))].copy()
#room_idごとに最後のゲストのdfを作成。
last_guest_df = pair_df.drop_duplicates(subset= 'room_id', keep = 'last').copy()
#両方のdfを突合。
match_df_raw = pd.merge(room_clear_df, last_guest_df, on=['room_id', 'owner_name', 'guest_name'])
match_df_raw = match_df_raw.loc[(match_df_raw['chat_seconds_y'] - match_df_raw['chat_seconds_x']) < 300]
match_df = match_df_raw[['room_id', 'owner_name','guest_name']].copy()
match_df['match'] = 1
#会話時間とcv情報が紐づいたpair_dfが完成。
pair_df = pair_df.drop_duplicates(subset= ['room_id','guest_name'], keep = 'last')
pair_df = pd.merge(pair_df, match_df, on=['room_id', 'owner_name', 'guest_name'], how='left')
pair_df['match'].replace(np.nan, 0, inplace=True)
pair_df = pair_df[['room_id', 'owner_name','guest_name','chat_start','chat_end','chat_seconds','match']]
#masterにマッチ情報を紐づけ。
pair_df_part = pair_df[['room_id', 'owner_name','guest_name','match']]
master_df_guest_match = pd.merge(master_df_guest, pair_df_part, on=['room_id', 'owner_name', 'guest_name'], how='left')
#カラムの位置を整えて最終的なdataframeを作成。
master_df_guest_match = master_df_guest_match[['room_id', 'chat_name', 'chat_sex', 'chat_sentence','chat_time', 'chat_seconds', 'owner_name', 'owner_sex', 'owner_age', 'introduction', 'room_start','room_end' , 'guest_name' , 'chat_start', 'chat_end', 'match']]
#マッチしたペアのみ抽出して確認
display(master_df_guest_match[master_df_guest_match["match"]>0])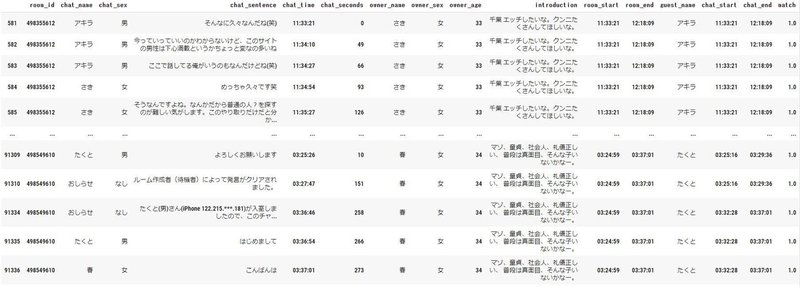
これで分析用に整備したDataFrameが完成した。
5、連絡先を交換した会話の比率を確認する
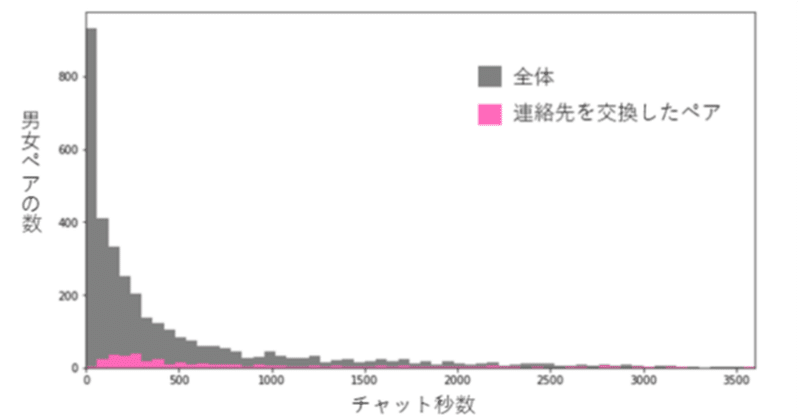
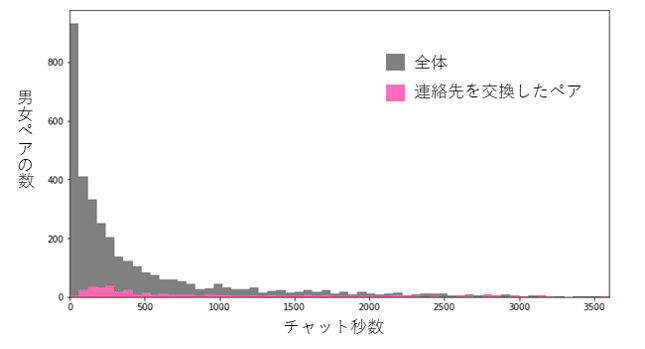
本格的な分析は次回に行うとして、連絡先交換したペアは3,536組中337組で連絡先交換率は約9.5%だった。
これが高いか低いかはちょっと何とも言えないが、チャット終了時間を1分ごとに並べると下のような感じになった。
3分程度で半分以上のチャットが終了するというなかなか世知辛い状況が分かったが、中には1時間くらいチャットしているペアもいるようだ。
次はもう少しチャットの中身にも踏み込んで女心を丸裸にしていきたい。
この記事が気に入ったらサポートをしてみませんか?