マッチングサイトpython集計分析その5~ラブルームパパ活事情を分析する~

前回の記事はこちら
前回分析を進めていく中で連絡先を交換したペアの中にもパパ活目的で連絡先交換をしているペアがいそうなことが分かった。ラブルームを覗くと確かにそれっぽいやり取りを目にする事が多く、今回はラブルームにおけるパパ活事情を深掘りしてみたい。
1、実際のパパ活のやり取りを見る
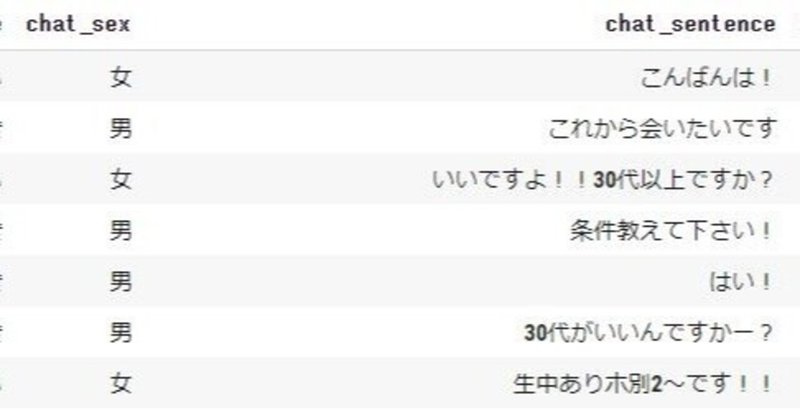
分かりやすいのは、↓のようなやり取りである。
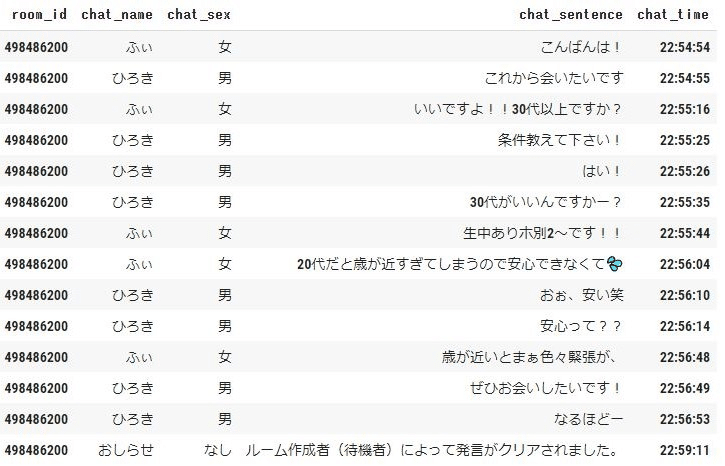
「条件」や「パパ」、「ホ別」といったキーワードが使われていて連絡先交換までに雑談がほとんどない所が特徴的である。
2、パパ活をキーワードで判別する(失敗)
連絡先交換したペアのうちパパ活関係のペアがどれくらい含まれるかを確認する。まずは連絡先交換までに「条件」「パパ」「ホ別」を含んでいたペアを集計する。
pair_df_papa = pair_df[['room_id', 'owner_name','owner_sex','owner_age','guest_name','chat_start','chat_end','chat_seconds','match']].copy()
#パパ活判別用のdfを作成。
papa_df = master_df_guest_match[['room_id','owner_name','owner_sex','owner_age','guest_name','chat_start','chat_end','chat_seconds','chat_sentence']].copy()
papa_df = papa_df.loc[(papa_df['guest_name']!="ゲストなし") & (papa_df['chat_sentence'].str.contains("ホ別|別1|別2|別3|穂別|パパ|条件"))].copy()
papa_df['papa'] = 1
papa_df = papa_df.drop_duplicates(subset=['room_id','owner_name','guest_name'])
papa_df = papa_df[['room_id','owner_name','guest_name','papa']]
#papa情報が紐づいたpair_dfが完成。
pair_df_papa = pd.merge(pair_df_papa, papa_df, on=['room_id', 'owner_name', 'guest_name'], how='left')
pair_df_papa['papa'].replace(np.nan, 0, inplace=True)
pair_df_papa = pair_df_papa[['room_id', 'owner_name','owner_sex','owner_age','guest_name','chat_start','chat_end','chat_seconds','match','papa']]
#display(pair_df_papa[pair_df_papa['papa']!=0])
# グラフ描画のためmatplotlibのpyplotをインポート
import matplotlib.pyplot as plt
#from matplotlib.font_manager import FontProperties
match_pair_cs = pair_df_papa.loc[(pair_df_papa["match"]>0) & (pair_df_papa['chat_seconds']>0),'chat_seconds']
papa_match_pair_cs = pair_df_papa.loc[(pair_df_papa["match"]>0) & (pair_df_papa['chat_seconds']>0) & (pair_df_papa['papa']>0),'chat_seconds']
papa_pair_cs = pair_df_papa.loc[(pair_df_papa['chat_seconds']>0) & (pair_df_papa['papa']>0),'chat_seconds']
# ヒストグラムを描画する
bins = 60
hist_range=(0,3600)
plt.figure(figsize=(11,6))
plt.xlim(0, 3600)
Y1, X1, _ = plt.hist(match_pair_cs, bins=bins, color = "hotpink", range=hist_range) #正規化したい場合はdensity=True
Y2, X2, _ = plt.hist(papa_match_pair_cs, bins=bins, color = "green", range=hist_range) #正規化したい場合はdensity=True
plt.show()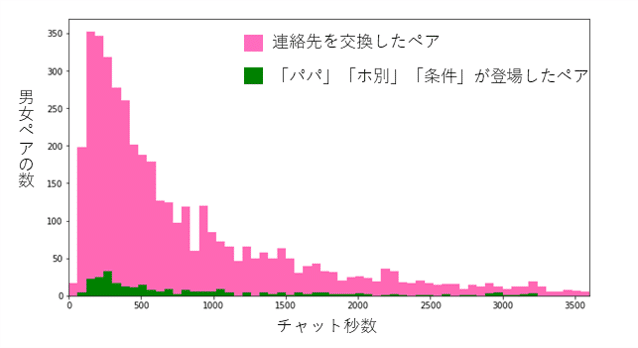
4,379組中282組で約6.4%が条件に当てはまる、という結果となった。これだけだとあまり多くない感じがするが、よく見ると、↓のようなやり取りはパパ活として判別できないことが分かった。
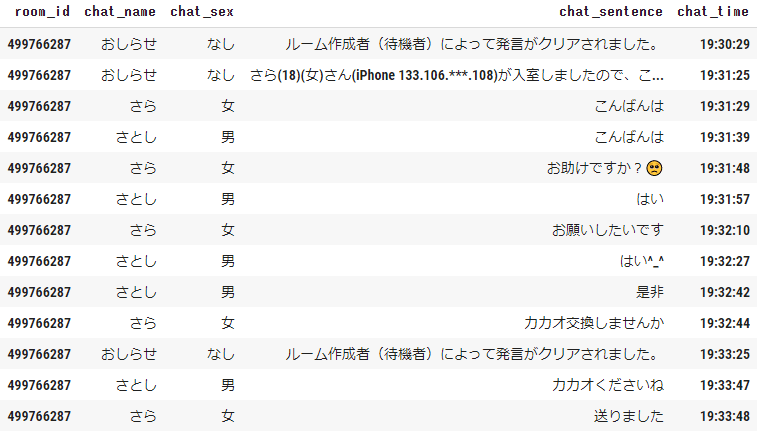
かといって、これを含めるために「お助け」「お礼」「サポート」「サポ」といったワードを広げすぎると例えば↓のようなパパ活ではないものもパパ活にカウントされてしまう。
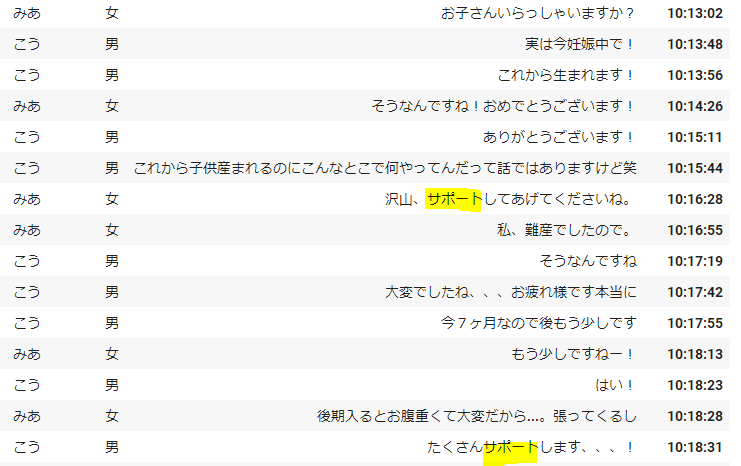
という訳で、キーワードを指定してパパ活を判別するのはなかなか難しそうだ。
よく考えたらパパ活女子側も警察の目に留まらないように色々な隠語を使って活動しているはずなので、判別が難しいのは当たり前なのかもしれない。
3、パパ活を会話時間で判別する
キーワードでの判別を断念したものの、パパ活のチャットにはもう一つの特徴がある。パパ活のチャットはあまりに目的がハッキリしているため、他のチャットよりも会話時間が短いということだ。
そこで連絡先交換のペアのヒストグラムを見てみると、明らかに凹んでいる部分があることが分かる。もしかするとここがパパ活とパパ活以外を分ける分水嶺なのかもしれない。
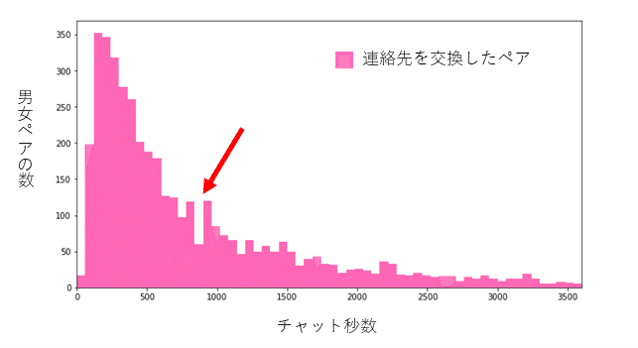
そこで、この800秒(13分程度)というチャット秒数を区切りにして、800秒未満/800秒以上での連絡先交換で登場する単語の差分を見てみる。
#800秒未満でマッチしたペアの形態素解析
sentences_sep_short_match_room = master_df_guest_match[(master_df_guest_match["chat_allseconds"] < 800) & (master_df_guest_match['chat_sex']!="なし") & (master_df_guest_match['match']!=0)]["chat_sentence"]
import MeCab
# インスタンスの生成
mecab = MeCab.Tagger(path)
# 区切ったレス群ごとに形態素解析を実行
chasen_list_short_match_room = [mecab.parse(sentence) for sentence in sentences_sep_short_match_room]
#空のリストを作っておく。
word_list_short_match_room = []
# ノイズ(不要品詞)の除去
for chasen in chasen_list_short_match_room:
for line in chasen.splitlines():
if len(line) <= 1: break
speech = line.split()[-1] ## 品詞情報を抽出
if "名詞" in speech:
if (not "非自立" in speech) and (not "代名詞" in speech) and (not "数" in speech):
word_list_short_match_room.append(line.split()[0])
#800秒以上でマッチした男子部屋の形態素解析
sentences_sep_long_match_room = master_df_guest_match[(master_df_guest_match["chat_allseconds"] >= 800) & (master_df_guest_match['chat_sex']!="なし") & (master_df_guest_match['match']!=0)]["chat_sentence"]
# 区切ったレス群ごとに形態素解析を実行
chasen_list_long_match_room = [mecab.parse(sentence) for sentence in sentences_sep_long_match_room]
#空のリストを作っておく。
word_list_long_match_room = []
# ノイズ(不要品詞)の除去
for chasen in chasen_list_long_match_room:
for line in chasen.splitlines():
if len(line) <= 1: break
speech = line.split()[-1] ## 品詞情報を抽出
if "名詞" in speech:
if (not "非自立" in speech) and (not "代名詞" in speech) and (not "数" in speech):
word_list_long_match_room.append(line.split()[0])
#頻度分析用のライブラリインポート
from collections import Counter
#800秒未満でマッチしたペアの頻度
short_match_room_word_counter = Counter(word_list_short_match_room)
short_match_room_word_df = pd.DataFrame(short_match_room_word_counter.most_common())
short_match_room_word_df.columns = ['word', 'short_match_room_count']
#マッチした男子部屋の頻度
long_match_room_word_counter = Counter(word_list_long_match_room)
long_match_room_word_df = pd.DataFrame(long_match_room_word_counter.most_common())
long_match_room_word_df.columns = ['word', 'long_match_room_count']
#頻度比較用のdf作成
compare_time_match_room_word_df = short_match_room_word_df.merge(long_match_room_word_df, how='outer', left_on='word', right_on='word')
compare_time_match_room_word_df.replace(np.nan, 0, inplace=True)
#正規化
compare_time_match_room_word_df['short_match_room_normal'] = compare_time_match_room_word_df['short_match_room_count'] / compare_time_match_room_word_df['short_match_room_count'].sum()
compare_time_match_room_word_df['long_match_room_normal'] = compare_time_match_room_word_df['long_match_room_count'] / compare_time_match_room_word_df['long_match_room_count'].sum()
#800秒以上/未満のマッチペアの頻出単語の比較
compare_time_match_room_word_df['long_room-short_room'] = compare_time_match_room_word_df['long_match_room_normal'] - compare_time_match_room_word_df['short_match_room_normal']
compare_time_match_room_word_df = compare_time_match_room_word_df.sort_values('long_room-short_room',ascending=False)
long_room_word = compare_time_match_room_word_df[(compare_time_match_room_word_df['long_match_room_count'] > 50) & (compare_time_match_room_word_df['short_match_room_count'] > 30) & (~compare_time_match_room_word_df["word"] .isin(["そ","人","あと","ご","者","ちゃん","さん","さ","的","前","とこ"]))]
print("800秒以上のマッチペア頻出単語")
display(long_room_word[["word","long_room-short_room"]])
compare_time_match_room_word_df['short_room-long_room'] = compare_time_match_room_word_df['short_match_room_normal'] - compare_time_match_room_word_df['long_match_room_normal']
compare_time_match_room_word_df = compare_time_match_room_word_df.sort_values('short_room-long_room',ascending=False)
short_room_word = compare_time_match_room_word_df[(compare_time_match_room_word_df['long_match_room_count'] > 50) & (compare_time_match_room_word_df['short_match_room_count'] > 30) & (~compare_time_match_room_word_df["word"] .isin(["ー","初め","きた","辺","おは","お"]))]
print("800秒未満のマッチペア頻出単語")
display(short_room_word[["word","short_room-long_room"]])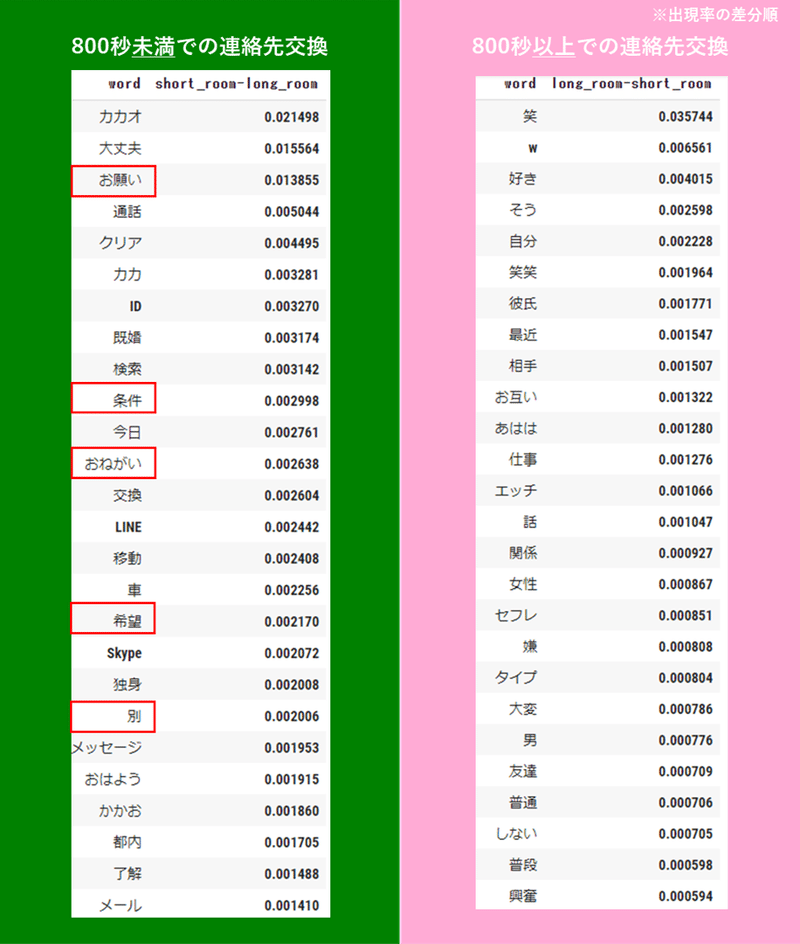
800秒未満のペアから「お願い」「希望」「別」「条件」といったパパ活の雰囲気が漂うキーワードが見事に上がってきた。つまり、若干乱暴かもしれないが、800秒未満での連絡先交換はほぼパパ活であると言っても良いのではないかと思う。
ちなみに、全ての連絡先を交換したペア4,379組中、800秒未満で連絡先を交換した組は2,687組の61.4%だった。
4、ラブルームでのパパ活実態まとめ
ということで、まとめると
・ラブルームにおけるパパ活比率は約60%(推定含む)。
・ラブルームでパパ活のマッチングにかかる秒数は13分20秒以内。
ということが今回分かった。
自分がパパ活女子だと仮定して、15分近く1人の男性とチャットしていられるかを想像してみるとなかなか絶妙なラインを突いているような気もする。
今後は、800秒以上チャットして連絡先交換すること=真の連絡先交換として詳細分析を進めていこうと思う。
この記事が気に入ったらサポートをしてみませんか?