
Rを使った、住みたい自治体の人気度のデータ分析などについて

当記事によれば、2018年の東京都への女性の転入超過数は4.8万人となり、男性の転入超過数3.4万人を大きく上回っているとのことだ。転入超過数の男女の差は近年、大きくなっている。
経済学では、都市に人が集まる傾向をソーティングと呼ぶ。都市に人や企業が集まることで、集積の経済の正の外部性が働く。集積の経済は生産性を向上させ、労働者の賃金を上昇させることにもつながる。
都市部の課題として、少子化対策や待機児童の解消などがあるだろう。一方、地方の課題として、高学歴の女性が働くための職場を作ることなども考えられる。
都市部と地方では異なる視点で、異なる対策を打ち出していくことも大切だろう。
当文中では、住みたい自治体の人気度と25の指標を用いて、Rを使ったデータ分析を行うこととしたい。
1. Rでデータ分析する自治体、指標等について
まず、自治体*の人気度については、株式会社リクルート住まいカンパニーの住みたい街ランキング2019の点数(埼玉県さいたま市、神奈川県横浜市、神奈川県川崎市にある行政区については最も点数が高いものを採用)を引用した。また、自治体の人気度を分析するための指標*については、政府統計e-Statの社会・人口統計体系の市区町村データから引用した。
そして、これらのデータをもとにオリジナルデータを作成し、因子分析を実行した。また因子得点に基づいて自治体をクラスタリングし、特性の似た自治体ごとに分けた。
さらに、自治体の人気度について回帰分析し、実測値と理論上の推定値の差から、今後の自治体の在り方について考えてみることとする。
2. Rによるデータ分析
まず、上述したオリジナルデータ(ファイル名COMEMO(CSVファイル)とする。またファイルの1行目はヘッダー。1列目は市区町、2列目は行政コード、3列目は人気度、4~28列目は指標名とする)をRStudioを使って読み込んだ。
DF <- read.table("COMEMO.csv",
sep = ",", # カンマ区切りのファイル
header = TRUE, # 1行目はヘッダー(列名)
stringsAsFactors = FALSE) # 文字列は文字列型で取り込むデータの概要は、次のとおりである。
##データの概要を確認する
str(DF)
summary(DF[, -(1:2)])'data.frame': 89 obs. of 28 variables:
$ 市区町 : chr "千代田区" "中央区" "港区" "新宿区" ...
$ 行政コード : int 13101 13102 13103 13104 13105 13106 13107 13108 13109 13110 ...
$ 人気度 : int 998 823 2134 1096 941 374 323 437 1003 1282 ...
$ 世帯あたり人数 : num 1.76 1.78 1.86 1.63 1.82 ...
$ 年齢15歳未満比率 : num 0.1147 0.119 0.1234 0.0811 0.1069 ...
$ 年齢65歳以上比率 : num 0.176 0.161 0.175 0.196 0.191 ...
$ 男性比率 : num 0.502 0.478 0.472 0.501 0.482 ...
$ 女性比率 : num 0.498 0.522 0.528 0.499 0.518 ...
$ 転入者_対人口比 : num 0.1151 0.1061 0.0889 0.0929 0.0782 ...
$ 転出者_対人口比 : num 0.0915 0.0804 0.0802 0.0812 0.0693 ...
$ 昼間人口比_per : num 1461 431 387 232 158 ...
$ 第1次産業従業者数比 : num 5.01e-05 3.36e-04 1.66e-04 3.65e-04 3.27e-04 ...
$ 第2次産業従業者数比 : num 0.0865 0.0906 0.1068 0.0862 0.1114 ...
$ 第3次産業従業者数比 : num 0.913 0.909 0.893 0.913 0.888 ...
$ 千人あたり事業所数 : num 586.4 268.2 161.8 100.7 65.2 ...
$ 千人あたり小売店数 : num 60.4 25.3 15.7 12.7 7.8 ...
$ 千人あたり飲食店数 : num 67.25 37.84 23.76 17.05 6.85 ...
$ 千人あたり大型小売店数 : num 1.4896 0.7366 0.4357 0.3178 0.0956 ...
$ 千人あたり幼稚園数 : num 0.2055 0.1133 0.1233 0.0899 0.1229 ...
$ 千人あたり小学校数 : num 0.1883 0.1133 0.0822 0.0899 0.1092 ...
$ 千人あたり中学校数 : num 0.2397 0.0354 0.0904 0.048 0.1229 ...
$ 千人あたり高校数 : num 0.3082 0.0142 0.074 0.033 0.1183 ...
$ 千人あたり保育所等数 : num 0.171 0.241 0.177 0.132 0.205 ...
$ 千人あたり有料老人ホーム数 : num 0.0171 0.0142 0.0288 0.048 0.0319 ...
$ 千人あたり刑法犯認知件数 : num 76.8 25 23.4 32.5 11 ...
$ 千人あたり一般行政部門職員数: num 14.38 8.32 6.99 6.64 6.73 ...
$ 経常収支比率_per : num 70 73.1 65.4 81.7 76.8 81.3 83.3 75.9 71.1 79 ...
$ 実質公債費比率_per : num 1.3 0.6 -1.9 -2.9 -3.8 0.3 -0.2 -4.4 -3.9 -2.3 ...
人気度 世帯あたり人数 年齢15歳未満比率 年齢65歳以上比率 男性比率 女性比率
Min. : 60.0 Min. :1.627 Min. :0.08083 Min. :0.1575 Min. :0.4691 Min. :0.4832
1st Qu.: 115.0 1st Qu.:2.072 1st Qu.:0.11435 1st Qu.:0.2084 1st Qu.:0.4904 1st Qu.:0.4983
Median : 201.0 Median :2.291 Median :0.12089 Median :0.2324 Median :0.4962 Median :0.5038
Mean : 353.7 Mean :2.227 Mean :0.12004 Mean :0.2342 Mean :0.4954 Mean :0.5046
3rd Qu.: 437.0 3rd Qu.:2.407 3rd Qu.:0.12871 3rd Qu.:0.2517 3rd Qu.:0.5017 3rd Qu.:0.5096
Max. :2134.0 Max. :2.844 Max. :0.14919 Max. :0.3684 Max. :0.5168 Max. :0.5309
転入者_対人口比 転出者_対人口比 昼間人口比_per 第1次産業従業者数比 第2次産業従業者数比 第3次産業従業者数比
Min. :0.01619 Min. :0.02322 Min. : 74.9 Min. :1.215e-05 Min. :0.05555 Min. :0.6121
1st Qu.:0.03848 1st Qu.:0.03706 1st Qu.: 85.9 1st Qu.:3.344e-04 1st Qu.:0.10926 1st Qu.:0.7944
Median :0.04915 Median :0.04403 Median : 91.7 Median :9.987e-04 Median :0.16233 Median :0.8373
Mean :0.05263 Mean :0.04853 Mean : 120.8 Mean :1.647e-03 Mean :0.16723 Mean :0.8311
3rd Qu.:0.06332 3rd Qu.:0.05730 3rd Qu.: 99.8 3rd Qu.:1.661e-03 3rd Qu.:0.20531 3rd Qu.:0.8883
Max. :0.11509 Max. :0.09146 Max. :1460.6 Max. :1.484e-02 Max. :0.38672 Max. :0.9431
千人あたり事業所数 千人あたり小売店数 千人あたり飲食店数 千人あたり大型小売店数 千人あたり幼稚園数 千人あたり小学校数
Min. : 22.69 Min. : 3.538 Min. : 1.881 Min. :0.04949 Min. :0.04074 Min. :0.07337
1st Qu.: 29.31 1st Qu.: 5.165 1st Qu.: 3.224 1st Qu.:0.10981 1st Qu.:0.06694 1st Qu.:0.08994
Median : 34.10 Median : 6.105 Median : 3.925 Median :0.13101 Median :0.07909 Median :0.10297
Mean : 49.42 Mean : 7.737 Mean : 5.999 Mean :0.17001 Mean :0.08434 Mean :0.11115
3rd Qu.: 43.20 3rd Qu.: 7.746 3rd Qu.: 5.170 3rd Qu.:0.16770 3rd Qu.:0.09353 3rd Qu.:0.11715
Max. :586.41 Max. :60.439 Max. :67.253 Max. :1.48957 Max. :0.20546 Max. :0.23175
千人あたり中学校数 千人あたり高校数 千人あたり保育所等数 千人あたり有料老人ホーム数 千人あたり刑法犯認知件数
Min. :0.03542 Min. :0.009011 Min. :0.09529 Min. :0.01079 Min. : 7.352
1st Qu.:0.04802 1st Qu.:0.022084 1st Qu.:0.12437 1st Qu.:0.02877 1st Qu.:12.662
Median :0.05760 Median :0.027690 Median :0.14224 Median :0.04837 Median :15.150
Mean :0.06314 Mean :0.034790 Mean :0.15116 Mean :0.04943 Mean :16.377
3rd Qu.:0.06706 3rd Qu.:0.039369 3rd Qu.:0.17266 3rd Qu.:0.06213 3rd Qu.:17.332
Max. :0.23970 Max. :0.308188 Max. :0.24082 Max. :0.15027 Max. :76.773
千人あたり一般行政部門職員数 経常収支比率_per 実質公債費比率_per
Min. : 3.518 Min. :65.40 Min. :-6.400
1st Qu.: 4.060 1st Qu.:81.80 1st Qu.:-0.200
Median : 4.437 Median :89.20 Median : 1.800
Mean : 4.832 Mean :86.89 Mean : 2.309
3rd Qu.: 5.169 3rd Qu.:92.10 3rd Qu.: 5.000
Max. :14.382 Max. :97.70 Max. :18.000
2-1 平行分析により適切な因子数の判断などを
因子分析のために、平行分析(parallel analysis)を実行し、適切な因子数や主成分数の目安を確認した。
まず平行分析のためのfa.parallel()関数を実行するために、ライブラリpsychを読み込む。
##ライブラリの読み込み
library(psych)そして、平行分析を実行。
result.prl <- fa.parallel(DF[, -(1:3)], fm = "minres")fm=因子抽出法(minres 最小残差法、pa 主因子法、ml 最尤法)について、最尤法で平行分析を実行したところエラーメッセージが発生したため、最小残差法を実行(最小残差法でも警告メッセージが表示されたが、ここではあまり気にせずに進める)。
平行分析を実行したところ、the number of factors = 3となり、因子分析で適切な因子数は3、the number of components = 3となり、主成分分析で適切な主成分数は3と示唆された。
2-2 因子分析の実行
適切な因子数が3と判断されたため、nfactors=3と指定して因子分析を実行する。
resultFA <- fa(DF[, -(1:3)],
nfactors = 3, # 因子数を指定
fm = "minres", # pa 主因子法,ols 最小二乗法,ml 最尤法
rotate = "varimax", # varimax 直交、promax 斜交
scores = "regression") # regression 回帰法
さらに、因子負荷量を基準にソートし、結果を図で表示する。
print(resultFA, digits = 2, sort = TRUE)fa.diagram(resultFA,
rsize = 0.8, e.size = 0.1, # 四角と円のサイズ
marg = c(.5, 5, .5, .5), # 余白の設定
cex = .6) # 文字サイズ
また、因子得点をデータフレームに変換しておく。
##因子得点をデータフレームに変換
DFfa <- as.data.frame(resultFA$scores)
因子分析の結果は次のとおりである。
Factor Analysis using method = minres
Call: fa(r = DF[, -(1:3)], nfactors = 3, rotate = "varimax",
scores = "regression", fm = "minres")
Standardized loadings (pattern matrix) based upon correlation matrix
item MR1 MR2 MR3 h2 u2 com
千人あたり小売店数 13 0.96 -0.18 0.03 0.960 0.040 1.1
千人あたり事業所数 12 0.95 -0.25 -0.05 0.962 0.038 1.1
昼間人口比_per 8 0.94 -0.22 -0.08 0.936 0.064 1.1
千人あたり飲食店数 14 0.92 -0.30 0.01 0.933 0.067 1.2
千人あたり大型小売店数 15 0.90 -0.25 -0.03 0.871 0.129 1.2
千人あたり一般行政部門職員数 23 0.87 -0.32 0.15 0.878 0.122 1.3
千人あたり高校数 19 0.85 -0.07 0.10 0.747 0.253 1.0
千人あたり刑法犯認知件数 22 0.80 -0.31 -0.23 0.779 0.221 1.5
千人あたり中学校数 18 0.79 0.27 0.19 0.740 0.260 1.4
千人あたり幼稚園数 16 0.72 0.22 0.22 0.615 0.385 1.4
千人あたり保育所等数 20 0.22 0.00 0.03 0.051 0.949 1.0
世帯あたり人数 1 -0.20 0.91 -0.13 0.879 0.121 1.1
転入者_対人口比 6 0.35 -0.89 0.04 0.908 0.092 1.3
転出者_対人口比 7 0.31 -0.88 0.08 0.874 0.126 1.3
年齢65歳以上比率 3 -0.08 0.72 0.28 0.600 0.400 1.3
経常収支比率_per 24 -0.37 0.61 -0.07 0.513 0.487 1.7
第1次産業従業者数比 9 0.13 0.59 0.14 0.389 0.611 1.2
千人あたり小学校数 17 0.47 0.59 0.14 0.585 0.415 2.0
第3次産業従業者数比 11 0.12 -0.56 0.54 0.609 0.391 2.1
実質公債費比率_per 25 0.01 0.52 -0.14 0.295 0.705 1.1
年齢15歳未満比率 2 -0.14 0.39 -0.25 0.240 0.760 2.0
男性比率 4 -0.08 0.01 -0.93 0.866 0.134 1.0
女性比率 5 0.08 -0.01 0.93 0.866 0.134 1.0
第2次産業従業者数比 10 -0.12 0.54 -0.54 0.596 0.404 2.1
千人あたり有料老人ホーム数 21 -0.19 0.26 0.28 0.184 0.816 2.8
MR1~MR3が共通因子ごとの因子負荷量であり、MR1とMR2の絶対値を確認していくと、「千人あたり保育所等数」と「世帯あたり人数」の間で逆転する。よって、「千人あたり保育所等数」より上が、MR1に寄与する項目、「世帯あたり人数」より下が、MR2に寄与する項目となる。同様にMR2とMR3を確認していくと、「年齢15歳未満比率」と「男性比率」の間で絶対値が逆転する。よって、MR2に寄与する項目は、「世帯あたり人数」から「年齢15歳未満比率」まで、MR3に寄与する項目は、「男性比率」以降の項目となる。また、因子負荷量の値がマイナスとなっているものは、その変数が共通因子に対して負の効果を持つことを表している。たとえば、「転入者_対人口比」のMR2に対する因子負荷量は-0.89となっているが、転入者_対人口比の値が小さいほうが共通因子MR2の値が大きくなることを意味する。
MR1 MR2 MR3
SS loadings 8.41 5.68 2.79
Proportion Var 0.34 0.23 0.11
Cumulative Var 0.34 0.56 0.67
Proportion Explained 0.50 0.34 0.17
Cumulative Proportion 0.50 0.83 1.00
Cumulative Var(累積寄与率)はProportion Var(分散説明率)の値を累積したものであり、第3因子まで抽出した結果、全体の分散の67%が説明されたことになっている。
因子分析の結果を図で表したものが下図(変数と因子負荷量の関係)である。
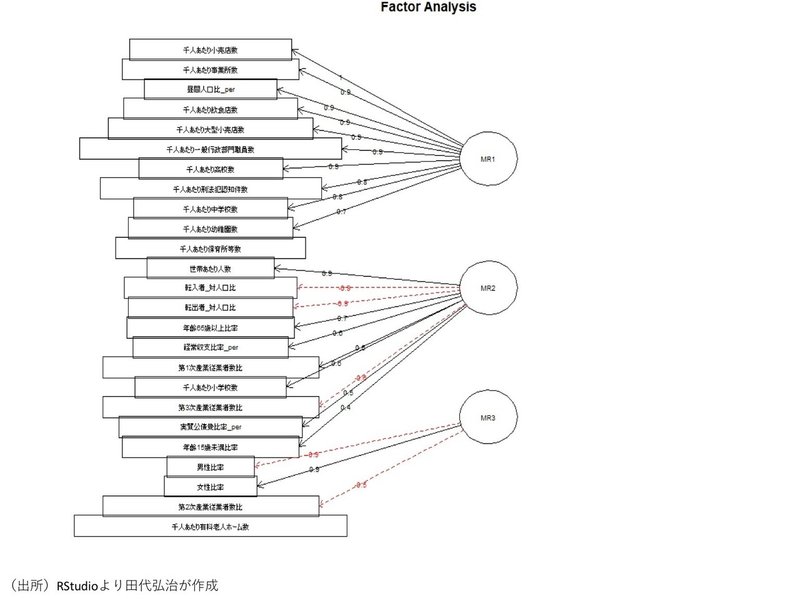
2-3 因子分析の結果の解釈
MR1への因子負荷量が高い項目を確認すると、千人あたり小売店数、千人あたり事業所数、昼間人口比_per、千人あたり飲食店数、千人あたり一般行政部門職員数などとなっている。これらが多いほど、MR1の値は大きくなる。これらを仮に「インフラ度」と名付ける。
MR2は、世帯あたり人数が多く、転入者_対人口比が小さく、経常収支比率が高く、第3次産業従業者数比が小さいほど、その値が大きくなる。これらを仮に「生活度」と名付ける。
MR3は、女性比率が高く、第2次産業従業者数比が小さいほど、その値は大きくなる。これらを仮に「男女度」と名付ける。
これらの関係をプロットしたものは次のとおりである。
まず、第1因子MR1と第2因子MR2の関係をプロットしたものが下図である。
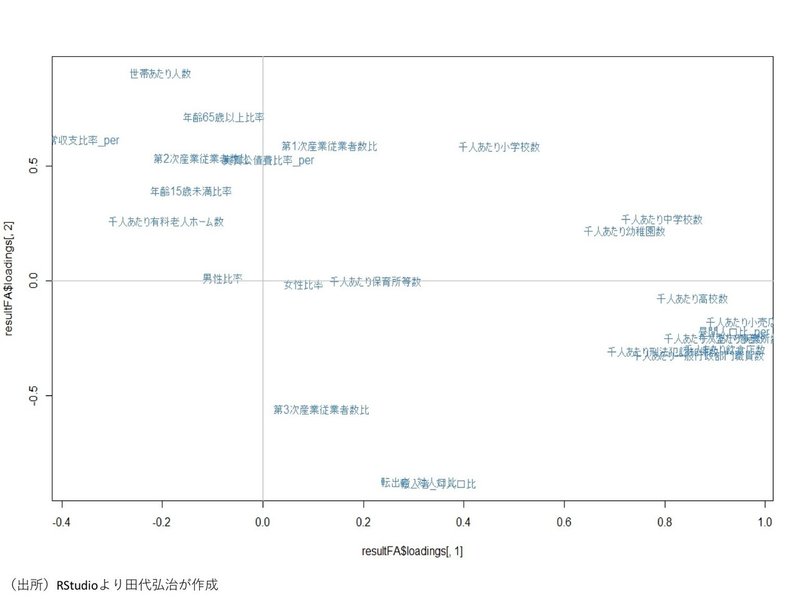
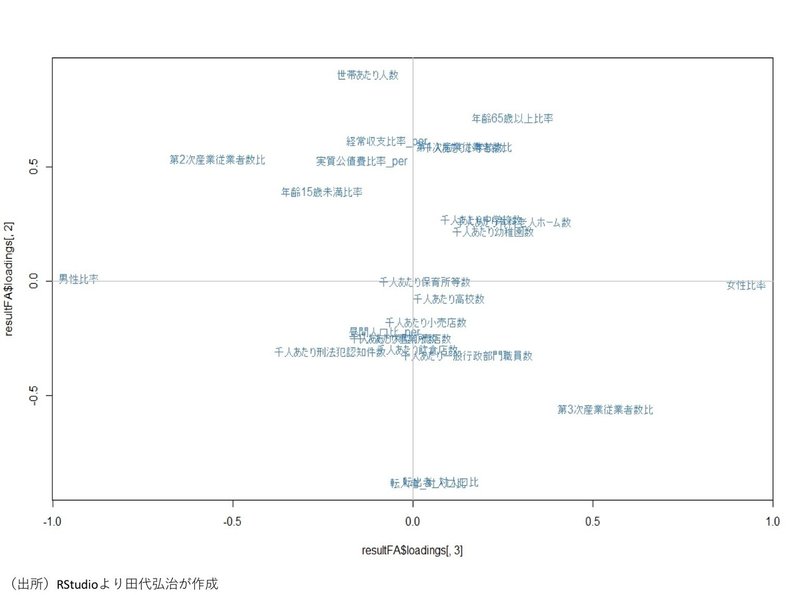
また、第3因子MR3と第2因子MR2の関係をプロットしたものは下図である。
2-4 因子得点に基づくクラスタリング
続いて、25の指標に基づいて、特性の似た自治体をクラスタリングする。
##因子得点をもとにクラスタリング
kmFA <- kmeans(DFfa, 4, iter.max = 50)
##色ラベルの配列を作るためにクラスタ番号の配列をコピー
color.kmFA <- kmFA$clusterさらに、クラスタごとに色分けしてプロットする。
##因子得点(サンプルごとの点数)の値を色分けしてプロットする
##ラベル(市町村名=DFfaの行の名前)をrownames(DFfa)で表示
##クラスタの色名color.kmFAで色分けして表示
plot(DFfa$インフラ度,
DFfa$生活度, type = "n")
text(DFfa$インフラ度,
DFfa$生活度, rownames(DFfa), col = color.kmFA)
lines(c(-10, 10), c(0, 0), col = "grey")
lines(c(0, 0), c(-5, 5), col = "grey")
第1因子(インフラ度)と第2因子(生活度)でプロットしたものが、下図である。

また、第3因子(男女度)と第2因子(生活度)でもプロットする。
plot(DFfa$男女度,
DFfa$生活度, type = "n")
text(DFfa$男女度,
DFfa$生活度, rownames(DFfa), col = color.kmFA)
lines(c(-10, 10), c(0, 0), col = "grey")
lines(c(0, 0), c(-5, 5), col = "grey")
第3因子(男女度)と第2因子(生活度)でプロットしたものが、下図である。

2-5 クラスタごとの人気度の分布、および自治体の人気度を説明する回帰分析について
まず、元のデータに因子得点とクラスタ番号を付加する。
##元のデータに因子得点とクラスタ番号を付加
DF <- cbind(DF, DFfa) # 列同士を結合
DF$kmFA <- color.kmFA # 色の名前で付加
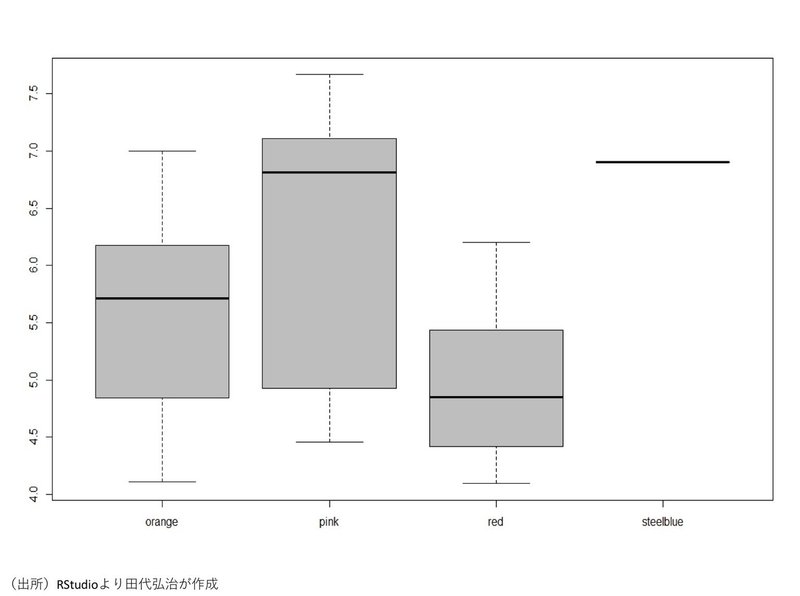
次に、クラスタごとの人気度の分布をボックスプロット(箱ひげ図)する。
##クラスタごとの人気度の分布
boxplot(log(DF$人気度) ~ DF$kmFA, col = "grey")
クラスタごとの人気度の分布をボックスプロットしたものが下図である(上の図と色が変わっており、orange(さいたま市、草加市、朝霞市、和光市、浦安市、新宿区、品川区、中野区、荒川区、横浜市、川崎市、等)、pink(館山市、中央区、港区、文京区、目黒区、渋谷区、世田谷区、杉並区、武蔵野市、国立市、多摩市、鎌倉市、等)、red(水戸市、つくば市、ひたちなか市、川越市、熊谷市、川口市、春日部市、三郷市、千葉市、佐倉市、柏市、我孫子市、八王子市、町田市、横須賀市、藤沢市、等)、steelblue(千代田区)となっている)。
続いて、被説明変数を人気度、説明変数を因子得点とする回帰分析を実行する。
##因子得点を使った回帰分析(因子得点のみを説明変数に使う)
Lm <- lm(log(人気度) ~ ., data = DF[, c(3, 29:31)])
さらに、人気度の理論的な推定値を求め、実測値と理論上の推定値をプロットする。
##Lmによる人気度予測結果(理論的な推定値)
pred <- predict(Lm, newdata = DF)
##実測値と理論上の推定値
plot(log(DF$人気度), pred, type = "n")
text(log(DF$人気度), pred, DF$市区町, col = color.kmFA)
lines(c(0, 10), c(0, 10), col = "grey")
実測値と理論上の推定値をプロットしたものが下図である。

回帰分析の結果、実測値が理論上の推定値より低い自治体に、中央区、荒川区、板橋区、調布市、国分寺市、国立市、朝霞市、和光市、館山市、等がある。一方、実測値が理論上の推定値より高い自治体に、港区、品川区、目黒区、世田谷区、つくば市、ひたちなか市、さいたま市、川越市、川口市、市川市、柏市、横浜市、鎌倉市、藤沢市、等がある。
3. まとめ:人気度の実測値と理論上の推定値から自治体の今後を考える
人気度の実測値が理論上の推定値より低い自治体は、伸びしろがある自治体と考えることもできる。今回の分析では、荒川区、板橋区、朝霞市、和光市などが該当する。実測値が理論上の推定値より低い要因には、たとえば自治体のイメージなどもあるかもしれない。このような自治体は、子育て世代のための政策を打ち出したり、強いリーダーシップを発揮する若い首長が現れると、自治体の人気度も向上するかもしれない。荒川区であれば、「東京23区で唯一スタバがない区だけど、暮らしやすい街」等のイメージを作り上げてもよいだろう。
一方、人気度の実測値が理論上の推定値より高い自治体は、港区や世田谷区、世田谷区、さいたま市、横浜市、鎌倉市などとなっている。今回の分析で実測値が理論上の推定値より高くなっている自治体を確認すると、なんとなく都会的なイメージがあったり、女性や若者にも人気がある自治体が多い(住みたい自治体の人気度の回帰分析のため、当然と言えば当然かもしれないですが…)。
今回、Rを使ってデータ分析した指標は一部のものである。住みたい自治体の人気度には、今回の指標には含まれていない交通や住環境、教育環境(教育の充実等)、自治体のイメージなどもあるだろう。
実測値が理論上の推定値より低くなっている自治体は、政策等による伸びしろが大きいと考えることもできる。一方、人気度が高い自治体は今後、伸び続ける可能性も高い。
首長のリーダーシップや民間、公共、社会の垣根を超えるトライセクター・リーダーが活躍することなどにより、各々の地域の課題を解決すること、改善を繰り返すことで、生活しやすい街、選ばれる自治体になることが、今後ますます重要になるだろう。
* Rでデータ分析した自治体
茨城県:水戸市、日立市、土浦市、つくば市、ひたちなか市(5自治体)
埼玉県:さいたま市、川越市、熊谷市、川口市、秩父市、所沢市、春日部市、狭山市、上尾市、草加市、越谷市、戸田市、入間市、朝霞市、志木市、和光市、久喜市、三郷市、ふじみ野市(19自治体)
千葉県:千葉市、銚子市、市川市、船橋市、館山市、木更津市、松戸市、成田市、佐倉市、習志野市、柏市、流山市、八千代市、我孫子市、浦安市、印西市(16自治体)
東京都:千代田区、中央区、港区、新宿区、文京区、台東区、墨田区、江東区、品川区、目黒区、大田区、世田谷区、渋谷区、中野区、杉並区、豊島区、北区、荒川区、板橋区、練馬区、足立区、葛飾区、江戸川区、八王子市、立川市、武蔵野市、三鷹市、府中市、昭島市、調布市、町田市、小金井市、小平市、日野市、国分寺市、国立市、多摩市、西東京市(38自治体)
神奈川県:横浜市、川崎市、横須賀市、平塚市、鎌倉市、藤沢市、小田原市、茅ヶ崎市、逗子市、厚木市、大和市(11自治体)
*人気度を分析するための指標
(1)世帯あたり人数(2)年齢15歳未満比率(3)年齢65歳以上比率(4)男性比率(5)女性比率(6)転入者_対人口比(7)転出者_対人口比(8)昼間人口比_per(9)第1次産業従業者数比(10)第2次産業従業者数比(11)第3次産業従業者数比(12)千人あたり事業所数(13)千人あたり小売店数(14)千人あたり飲食店数(15)千人あたり大型小売店数(16)千人あたり幼稚園数(17)千人あたり小学校数(18)千人あたり中学校数(19)千人あたり高校数(20)千人あたり保育所等数(21)千人あたり有料老人ホーム数(22)千人あたり刑法犯認知件数(23)千人あたり一般行政部門職員数(24)経常収支比率_per(25)実質公債費比率_per
【参考文献】
有賀友紀・大橋俊介(2019)『RとPythonで学ぶ実践的データサイエンス&機械学習』技術評論社
この記事が気に入ったらサポートをしてみませんか?