BigQuery の GAP_FILL 関数の使い所と、ユーザーランクデータを題材にした活用例

カレーフォワード マネーフォワードケッサイの tamiya です。
この記事では、最近 BigQuery に追加された GAP_FILL 関数(2024/03/03時点 preview 段階)について、その使い方と利用例を紹介します。
2024年2月27日に、BigQuery の time series 関数機能と range 関数機能が preview 公開されました。
いずれも DATE, DATETIME, TIMESTAMP 列を持つ時系列データの操作に関わる機能です。
その中でも GAP_FILL 関数は便利な機能で、間の値を補完しつつ等間隔な時系列データを作ることができます。
この関数を使うことで、これまでであれば連番テーブルを作成して cross join したり、 window 関数を組み合わたりして複雑なクエリを書く必要があった処理が、簡単に書けるようになりました。
本記事では、GAP_FILL 関数がどのような場面で役に立つかについて、例とともに紹介します。
GAP_FILL 関数でできること
日々の分析で扱う時系列データは、仕様上の理由や事故起因のデータ欠測などから間隔が綺麗に揃っておらず不均等な場合が大半です。
しかし、分析を行ううえではデータ間隔を等間隔(1分間隔、1時間間隔、24時間間隔、…)にしたい場面が度々あります。
そのようなケースで、時系列間隔を揃えたうえでギャップがあれば適当な値で埋める操作をできるのが、 GAP_FILL 関数です。
これを用いると、例えば時系列データの欠測値補完を行ったり、ユーザーごとの状態変更履歴データを元に日毎の状態を取得することができます。
模式的に表すと、以下のような操作ができます:
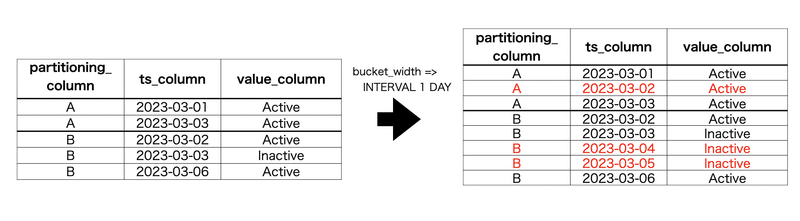
上記の図では補完する値がカテゴリカルデータの場合を例にしましたが、他にも数値データであれば線形補完することもできます。
Python の pandas を使われている方であれば、resample メソッドをイメージしていただくとわかりやすいかもしれません。
GAP_FILL 関数の使い方
GAP_FILL 関数は、DATE, DATETIME, TIMESTAMP いずれかの型の列を持つテーブルを入力とし、間隔を揃えて補完したテーブルを返します。
詳細は上記の公式ドキュメントに譲りますが、FROM 句内で主に以下のような内容を引数として記述します:
入力テーブルないしサブクエリ
参照する時系列カラム (ts_column)
揃えた後のデータ間隔 (bucket_width)
例: INTERVAL 1 MONTH
集約グループ (partitioning_columns)
例: ユーザーIDなど
補完対象の値カラムと補完方法 (value_columns)
[(column_name, gap_filling_method), ...] のような形で記述する。
gap_filling_method は、linear(線形補完)もしくは locf(直前の値を取ってくる)から選択する。
利用例: ユーザーランク変更履歴から日ごとのランクを取得する
GAP_FILL 関数の利用例として、変更履歴テーブルをもとに日毎の値を取得する方法を紹介します。
設定
ある EC サイトでは、ユーザーの購買額などを元にブロンズ (Bronze)・シルバー (Silver)・ゴールド (Gold)・プラチナ (Platinum) の4つのユーザーランクが付与されるとします。
このとき、日ごとのユーザーランクの構成比を集計しようと思います。
そのためには、以下のような形で過去の各時点でのユーザーランクのデータが必要になります:

しかし、手元には現時点でのユーザーごとのランクのテーブルか、以下のようなランクに変更があった場合のみ記録された変更履歴テーブルしか存在しません。
SELECT
*
FROM
`project_id.dataset_name.user_ranks`
ORDER BY
user_id
SELECT
*
FROM
`project_id.dataset_name.rank_change_log`
ORDER BY
user_id,
change_time
上記の変更履歴テーブルを見ると、例えば user_id=2 のデータでは 2023-03-01 と 2023-03-03 にはレコードがありますが、2023-03-02 はランク変更がなかったためレコードがありません。
3/2 は 3/1 と同じ Bronze ランクのはずというのは目で見ればすぐわかりますが、これをデータとして取得するにはどうすれば良いでしょう?
というわけで、履歴にレコードが存在しない日の値も埋めて、日ごと・ユーザーごとのランク一覧を取得するクエリを書きたいと思います。
GAP_FILL 関数を用いた解決方法
今回の場合、user_id 単位でレコードの間を埋めて1日間隔のデータを作るので、以下のようなクエリになります:
SELECT
*
FROM
GAP_FILL( TABLE `project_id.dataset_name.rank_change_log`,
ts_column => 'change_time',
bucket_width => INTERVAL 1 DAY,
partitioning_columns => ['user_id'],
value_columns => [ ('new_rank',
'locf') ] )
ORDER BY
user_id,
change_time
これを見ると、例えば user_id = 2 のレコードであれば履歴テーブルにはなかった 2023-03-02 についても値が埋められ、1日おきの等間隔なデータになりました。
しかし一方で、user_id ごとに最後にデータのある日付が揃っていません。 例えば、user_id =3 では 2023-03-05 までデータがあるのに対して、user_id = 1 では 2023-03-02 までしかレコードがありません。
全 user_id について、今日の日付(ここでは 2023-03-06 とする)までデータが入っていて欲しい、という場合は以下のように現時点でのランクのテーブルを一旦 UNION してから GAP_FILL を行います:
WITH add_current_date_row AS (
SELECT change_time, user_id, new_rank FROM `project_id.dataset_name.rank_change_log`
UNION ALL
SELECT TIMESTAMP('2023-03-06 00:00:00') AS change_time, user_id, current_rank AS new_rank FROM `project_id.dataset_name.user_ranks`
)
SELECT
*
FROM
GAP_FILL( TABLE add_current_date_row,
ts_column => 'change_time',
bucket_width => INTERVAL 1 DAY,
partitioning_columns => ['user_id'],
value_columns => [ ('new_rank',
'locf') ] )
ORDER BY
user_id,
change_time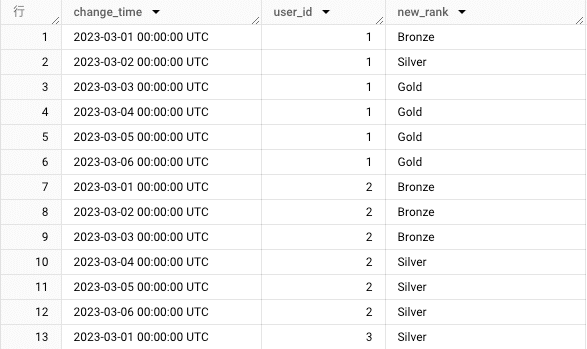
これで求めていたデータの完成です!
参考:GAP_FILL 関数を使わない書き方
さて、上記の内容を GAP_FILL 関数を使わずに実行するとなると、どうなるでしょうか?
その場合、
user_id × 日付連番テーブルを作成する
日付連番テーブルに日別の履歴テーブルを LEFT JOIN し、履歴のない日のランクが NULL のテーブルを作る
window 関数を用いて直近のランク変更を参照し、NULL を埋める
といった、複雑な操作が必要になります。
例えば、以下のようなクエリになるでしょう:
WITH
import_rank_change_log AS (
SELECT
*,
DATE(change_time) AS change_date
FROM
`project_id.dataset_name.rank_change_log` ),
-- ユーザーランク変更履歴テーブルを、時刻単位から日付単位にする
-- 会員登録初日に複数回ランク変更があった場合を考慮して、その日の初回の変更後ランクと最終変更後のランクを取得する。
find_daily_user_rank AS (
SELECT
user_id,
change_date,
MIN_BY(new_rank, change_time) AS initial_daily_user_rank,
MAX_BY(new_rank, change_time) AS final_daily_user_rank,
FROM
import_rank_change_log
GROUP BY
user_id,
change_date ),
-- 各ユーザーについて日付の連番テーブルを生成する
generate_user_date_range AS (
SELECT
DISTINCT user_id,
date
FROM
find_daily_user_rank,
UNNEST(GENERATE_DATE_ARRAY(DATE("2023-03-01"), DATE("2023-03-06"), INTERVAL 1 DAY)) AS date ),
-- 日付の連番テーブルと日付単位ユーザーランク変更履歴を JOIN する
-- これにより、ランク変更のない日付はランクが NULL になったテーブルができる
join_range_table AS (
SELECT
base.user_id,
base.date,
r.initial_daily_user_rank,
r.final_daily_user_rank
FROM
generate_user_date_range AS base
LEFT JOIN
find_daily_user_rank AS r
ON
base.user_id=r.user_id
AND base.date = r.change_date ),
-- NULL の部分のユーザーランクを埋めるために、最も最近のランク変更を拾い出す
obtain_previous_daily_rank AS (
SELECT
user_id,
date,
initial_daily_user_rank,
final_daily_user_rank,
LAST_VALUE(final_daily_user_rank IGNORE NULLS) OVER(PARTITION BY user_id ORDER BY date ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS previous_user_rank
FROM
join_range_table )
-- 会員登録日については NULL が残るので、初回のランクを埋める。
SELECT
user_id,
date,
COALESCE(previous_user_rank, initial_daily_user_rank) AS daily_user_rank
FROM
obtain_previous_daily_rank
ORDER BY
user_id,
dateまとめ
間隔が不均等な時系列データや等変更履歴データから一定間隔に値の入ったデータを作成したい、というケースは度々出くわしますが、これまでは複雑なクエリを頭を悩ませながら書く必要がありました。
しかし、ユーザーランクの例で見たように、GAP_FILL 関数を使うことで簡単に記述できるようになりました。
まだ本稿執筆時点では preview 段階の機能ではありますが、ここぞというタイミングで利用を検討してみてください。
この記事が気に入ったらサポートをしてみませんか?