
外れ値検出について

この記事の狙い・目的
機械学習を取り入れたAIシステムの構築は、
①データセット作成(前処理)→ ②モデルの構築 → ③モデルの適用
というプロセスで行っていきます。
その際「データセット作成(前処理)」の段階では、正しくモデル構築できるよう、事前にデータを整備しておくことが求めらます。
このブログでは、その際に問題なることが多い、「外れ値」とその対処方法について解説していきます。
プログラム等の実行環境
Python3
MacBook pro(端末)
PyCharm(IDE)
Jupyter Notebook(Chrome)
Google スライド(Chrome)
外れ値とは
外れ値とは、あるデータ点が分布から大きく外れているもの、つまり他のデータと比べて極端に離れた値のことを言います。
外れ値検出のアプローチ
外れ値検出のアプローチには大きく分けて「統計ベース」「ルールベース」の2通りがあります。
1.統計ベース
統計ベースのアプローチでは、母集団の形状や確率分布に仮定を置くことで検出を行います。
単純な例では、データが正規分布に従うと仮定した際に、平均値から±3σ以上離れた値を外れ値とみなす方法があります。
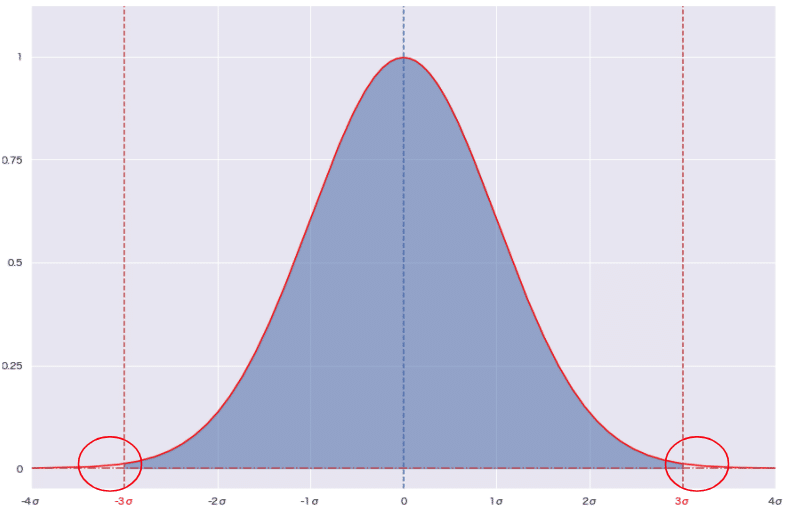
ただし、一般に正規分布に従うデータは少なく、単純に検出が困難なケースが多くあります。その為、例えば二項分布やポアソン分布など、様々な確率分布の中から近似する分布をまずは探索していく作業が必要になります。加くは別の記事で解説していきたいと思います。
また、標準偏差と平均値を用いる場合は、平均値が外れ値に引っ張られてしまうため注意が必要になります。
それ以外の方法として、ここでは以下の3通りの手法を紹介します。
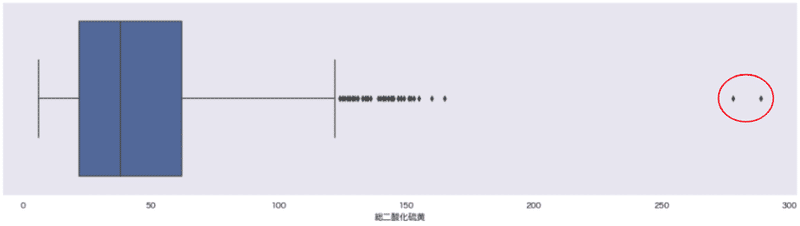
1.箱ひげ図、ヒストグラム、散布図での描画
単一変数の外れ値は、箱ひげ図(と四分位数)、ヒストグラム、散布図を用いて検出できる場合があります。
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
# データ取得
wine_red = pd.read_csv("./winequality-red.csv", sep=',')
plt.grid()
sns.boxplot(x='総二酸化硫黄', data=wine_red);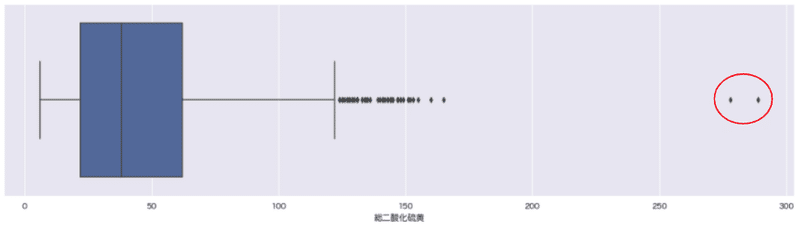
plt.figure(figsize=[20,10])
plt.grid()
sns.histplot(wine_red['総二酸化硫黄'], color='red');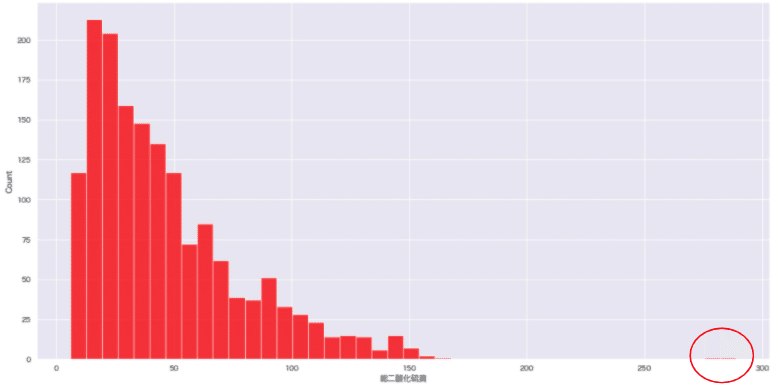
sns.relplot(data=wine_red['総二酸化硫黄']);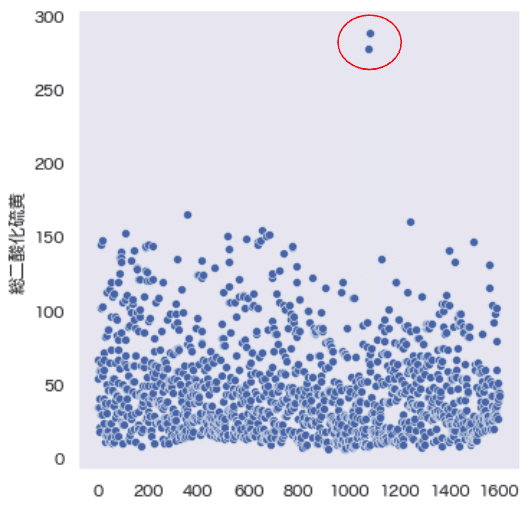
2.外れ値検定
「スミルノフ=グラブス検定」という検定手法を用いて外れ値を検出する方法もあります。
スミルノフ=グラブス検定とは、データが正規分布に従うことを前提に、測定対象データの外れ値を検出する手法です。
帰無仮説は、全てのデータが同じ母集団からなるものである
対立仮説は、対象データの最大・最小の値は外れ値である、とします。
つまり、対象データの内、平均値から最も外れているデータが、他の対象データと同じ正規分布に従うかどうかを検定します。
そして、帰無仮説が棄却された場合は、そのデータを外れ値とみなします。
この検定を、外れ値が検出されなくなるまで繰り返し行うのがスミルノフ=グラブス検定です。
import numpy as np
from scipy import stats as st
# スミルノフ=グラブス検定
data = wine_red['総二酸化硫黄']
alpha = 0.5
x, o = list(data), []
while True:
n = len(x)
t = stats.t.isf(q=(alpha / n) / 2, df=n - 2)
tau = (n - 1) * t / np.sqrt(n * (n - 2) + n * t * t)
i_min, i_max = np.argmin(x), np.argmax(x)
myu, std = np.mean(x), np.std(x, ddof=1)
i_far = i_max if np.abs(x[i_max] - myu) > np.abs(x[i_min] - myu) else i_min
tau_far = np.abs((x[i_far] - myu) / std)
if tau_far < tau: break
o.append(x.pop(i_far))
not_out = np.array(x)
out = np.array(o)
out.astype('int').tolist()
# 結果:[289, 278, 165]統計検定のメリットは、"165"も検出していることから、定量的に検出を行うことでプロット図で検知できなかった値も検出できることです。
その為、箱ひげ図等の描画と照らし合わせて解析する必要がありそうです。
異常値について
少し話が逸れてしまいますが、ここで異常値について解説しておきます。
異常値とは、外れ値の中でも例えば下記のような原因により発生した値のことを言います。
システムや機器の故障・プログラムのバグ
ヒューマンエラー(例えば入力ミス)
また、何らかの原因により許容される基準値を超えた値なども異常値となります。
例えば先ほどの「スミルノフ=グラブス検定」で算出した結果:[289, 278, 165]ですが、食品衛生法に定められた「総二酸化硫黄」の含有量の使用基準量は0.35g/kg未満となっており、大幅に基準値を超えていることから異常値であると考えられます。
外れ値≠異常値となるケースもありますが、このように外れ値=異常値となるもある為、解析時は「外れ値と異常値」を区別して考える必要があります。
3.二変量解析
これまで単一変数の解析による外れ値の検出方法について解説してきました。
これ以外にも「複数変数」のデータ同士の関係性を解析して初めて外れ値となるケースも存在します。
例えば、散布図を描いた際に、X軸では外れていないが、X軸・Y軸の組み合わせで見た際に外れているケースなどです。
plt.grid()
sns.scatterplot(data=wine_red, x="遊離二酸化硫黄", y="総二酸化硫黄")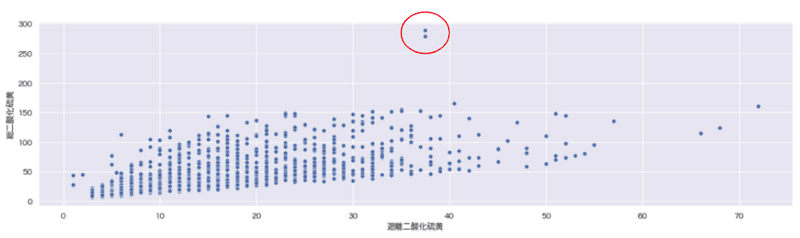
その他にもクラスター分析を用いて、二変量(以上)の関係性を把握し、解析する方法があります。
またクラスター分析には大きく分けて「非階層クラスタリング」「階層クラスタリング」の2通りがあります。
# 階層クラスタリング
from scipy.cluster.hierarchy import linkage,dendrogram
li = linkage(wine_red.corr())
r = dendrogram(li, labels=wine_red.columns)
plt.show();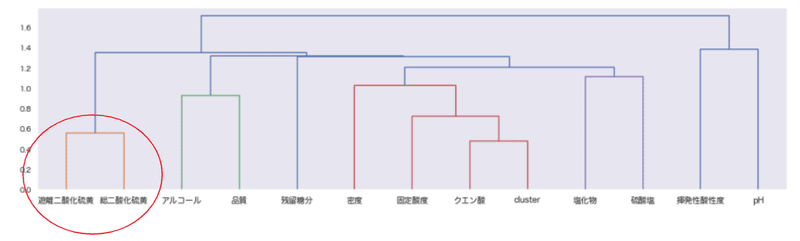
類似の二変数「遊離二酸化硫黄」「総二酸化硫黄」に対してクラスター分析を行います。
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
# 非階層クラスタリング(クラスター分析)
sc = StandardScaler()
wine_red_cls = wine_red[['遊離二酸化硫黄', '総二酸化硫黄']].copy()
clustering_sc = sc.fit_transform(wine_red_cls)
kmeans = KMeans(n_clusters=2, random_state=0)
clusters = kmeans.fit(clustering_sc)
wine_red_cls['cluster'] = clusters.labels_
pca = PCA(n_components=2)
x = clustering_sc
pca.fit(x)
x_pca = pca.transform(x)
pca_df = pd.DataFrame(x_pca)
pca_df['cluster'] = wine_red_cls['cluster']
for i in wine_red_cls['cluster'].unique():
tmp = pca_df.loc[pca_df['cluster'] == i]
plt.scatter(tmp[0], tmp[1])
plt.grid()
plt.show();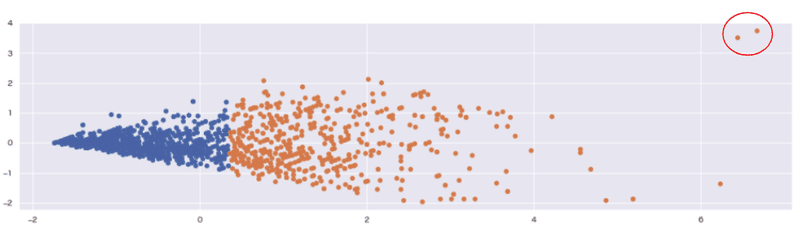
二変数の合成変数を2つのクラスタに分類した結果、[cluster=1]のグループに外れ値を検出することができました。(右上の赤丸印)
2.ルールベース
これまで「統計ベース」の外れ値検出のアプローチ方法について解説してきました。
ここからは「ルールベース」のアプローチ方法について解説します。
ルールベースの手法も様々あります。例えば、当該システム的にありえる値なのかどうかを判断する方法や、ドメイン観点から判断して異常値なのかどうかを判断する方法などがあります。
今回は、既知のサンプルを収集し、汎用的なルールを定めそのルールに乗っ取って外れ値(異常値)を検出する方法を以下で紹介していきます。外れ値検出のアルゴリズム
外れ値検出のアルゴリズム
ここで今一度、外れ値検出の理論を解説しておきます。今回は下記の3つを解説します。
①k-近傍法 (k-NN)
k-近傍法では、距離に基づく外れ値の検出を行います。
測定された点からk個の点までの距離は、正常データ程小さく、外れ値程大きくなることから、距離εが閾値を超えた点を外れ値とみなして検出を行います。
この手法は多次元データにも適用可能な点がメリットではありますが、全ての点からの距離を計算する必要がある為、計算量が多くなる点がデメリットとしてあげられます。
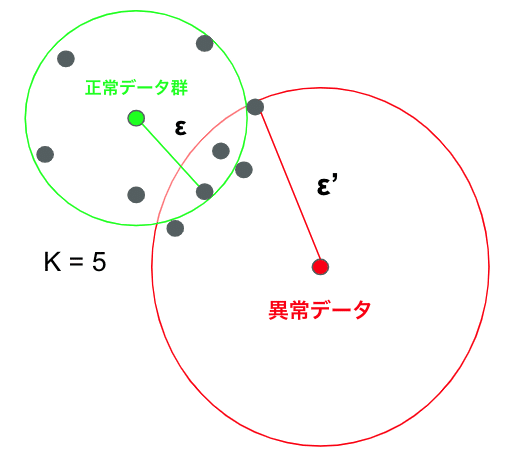
ただし、この閾値を決め、それ以上以下のデータを外れ値として扱う手法は少ないデータでは検出が困難なケースがあるようです。
また、閾値はデータの分析目的、業務要求、発生確率等を考慮した上で決定する必要があります。
②Local Outlier Factor (LOF)
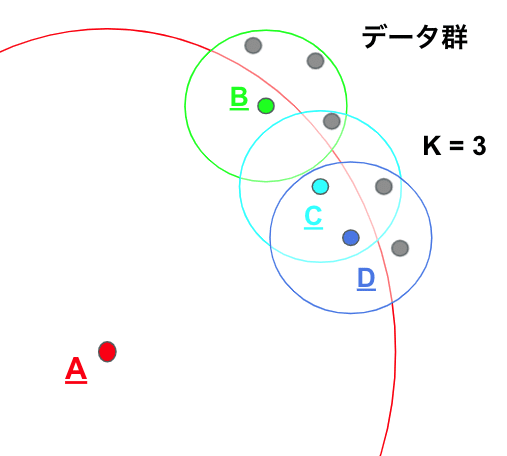
k-近傍法では「距離」に着目したアルゴリズムでしたが、LOFは「密度」に着目したアルゴリズムです。
LOFでは、正常データ群の局所密度(Local density)が小さく、外れ値の密度が大きくなることから、最大密度の値を外れ値としてみなして検出を行います。
下記の図の通り「近傍点:B,C,D」は「外れ値:A」に対して局所密度が小さく、近くにデータが集まっていることがわかります。
③ホテリング理論
ホテリング理論とは、測定データが正規分布に従うときに、外れ値(異常値)を検出する手法です。
具体的には、異常度を算出し、その異常度が閾値以上・以下かを判定することで、正常データ・外れ値(異常データ)かを識別することができます。
ここでは計算の流れを見ていきましょう。

異常度:a(x')の計算式の意味を解説しておきます。
検証データ:x'から平均値:μを引いているのは、平均値との差の大小から、外れ値を判定する為です。
外れ値の方が、平均値との差がより大きくなる為です。
また、分散(標準偏差:σの2乗)で除算しているのは、ばらつきの大きさを考慮して外れ値の判定を行う為です。
ばらつきが大きければある程度の幅を持って判定を行い、ばらつきが小さければ少しの外れでも外れ値(異常値)として判定します。
次に外れ値判定の閾値の設定方法と、判定方法を見ていきましょう。
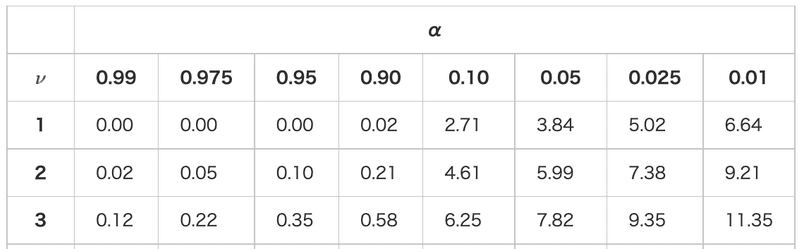
閾値は、カイ二乗分布の分布表を元に決定します。その際、異常度の有意水準値は「どの程度までを水準値とみなすか」データや業務要求、発生確率等を考慮し決定します。
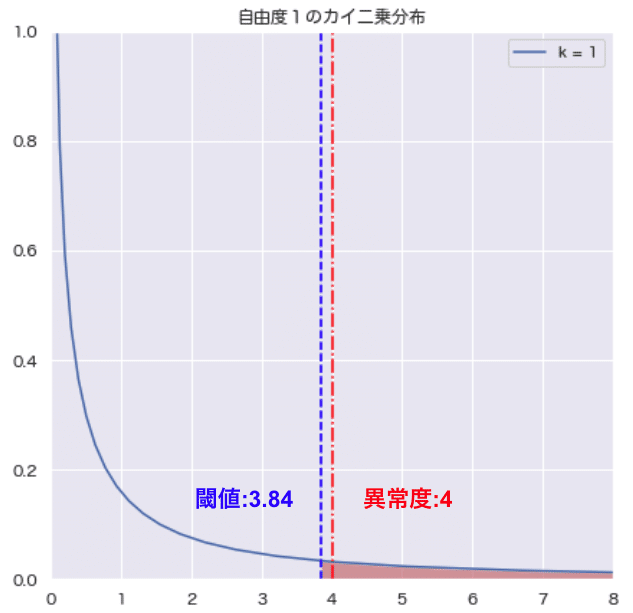
どういうことかと言うと、ホテリング理論では、検証データ:x'は正規分布を仮定している場合、異常度の計算結果は(データ数が十分に大きければ)「自由度1のカイ二乗分布」に従うとしています。
有意水準値は、例えば滅多に観測できないようなデータのみを外れ値として検出したい場合は、有意水準:α=0.01(1%)などとします。そうすると分布表から、自由度1のカイ二乗分布では、有意水準:0.01の場合、閾値:kは6.64となります。
結果、例えば異常度が4の場合、異常度:4<閾値:6.64となり、閾値を超えておらず、外れ値としては判定されません。
また、自由度1のカイ二乗分布で、有意水準:0.05の場合、閾値:kは3.84となります。
異常度が4の場合、異常度:4>閾値:3.84となり、閾値を超えている為、外れ値として判定されます。
再び解析
外れ値を除外し再び解析を行います。
# 外れ値=289, 278, 165
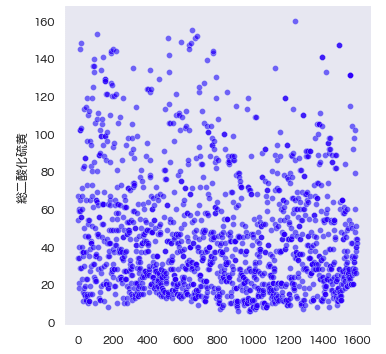
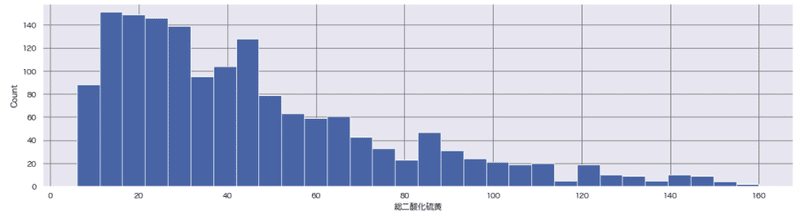
re_wine_red = wine_red[wine_red['総二酸化硫黄']<165]
plt.grid(color='gray')
# 箱ひげ図
sns.boxplot(x='総二酸化硫黄', data=re_wine_red)
# 散布図
sns.relplot(data=re_wine_red['総二酸化硫黄'], color='blue', alpha=0.5)
# ヒストグラム
sns.histplot(re_wine_red['総二酸化硫黄'], bins=30);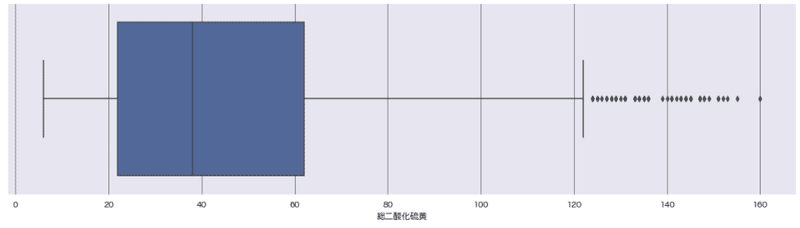
まとめ
これまで測定されたデータの描画により外れ値を検出することが多く、多少主観的な判断によるところもあったことが懸念点でしたが、今回「スミルノフ=グラブス検定」を実際に行ってみて、客観的・定量的に外れ値を検出する方法を学べたことはとても有意義であると感じました。
また、ホテリング理論を学んだことで統計的な(外れ値の検出方法の)知見を深めることができました。
どちらも今後のデータ解析に活かしていきたいと思います。
参考文献
統計WEB 32-1. 外れ値
統計WEB 22-2. カイ二乗分布表
統計WEB 23-3. 有意水準と検出力
外れ値を検出する方法とその特性に関する研究
時系列データに対する効果的な外れ値検出手法
Tips forB・F・T 連載第19 回 「ワイン醸造の基礎 -亜硫酸の話-」
フィラディス実験シリーズ第10弾『ワインの「添加物」徹底研究 Part 2 -SO₂(二酸化硫黄)』
解析結果
github/wine_quality.ipynb
サンプル・データセット UCI Machine Learning Repository
参考資料
この記事が気に入ったらサポートをしてみませんか?