
欠損データについて

この記事の狙い・目的
機械学習を取り入れたAIシステムの構築は、
①データセット作成(前処理)→ ②モデルの構築 → ③モデルの適用
というプロセスで行っていきます。
その際「データセット作成(前処理)」の段階では、正しくモデル構築できるよう、事前にデータを整備しておくことが求めらます。
このブログでは、その際に問題なることが多い、データの「欠損」とその対処方法について解説していきます。
欠損データとは
欠損データとは、なんらかの原因により、データの取得、登録ができなかったデータのことを言います。
欠損データの発生原因としては「データ登録の際、未入力項目が存在し、未入力を意味する値も登録されなかった」
「システム障害やプログラムのバグにより本来登録されるはずのデータが登録されなかった、または損失してしまった」
などが考えられます。
発生メカニズム
欠損データの発生メカニズムは、下記の3通りに大別できます。
1.Missing Completely At Random: MCAR
完全に"ランダムで"欠損するケース
例えば、アンケートへの回答漏れ・忘れなど。
2.Missing At Random: MAR
他の項目と関連して"ランダムで"欠損するケース
例えば、「性別:女性」の[体重]の入力拒否・未回答など。
3.Missing Not At Random: MNAR
その他の項目、またはその項目自体に関連して欠損するケース
低(高)所得者ほど、未入力拒否・未回答が多いなど。
既婚者のみを対象とする項目への回答など。
欠損データの分類
データ解析時において、欠損データを「無視可能」か「無視不可能」かを分けて解析する必要があります。
「無視可能」とは、欠損データの解析結果と、欠損していなかった場合の解析結果、その両者に違いがない状態のことを言います。
両者に違いがあれば、「無視不可能」となります。
無視可能な欠損データは、欠損データの発生メカニズムが「MCAR」「MAR」の状態を指します。この場合、そのままのデータを解析・使用するか、適切な手法を用いて解析するか決定する必要があります。
無視不可能な欠損データは、「NMAR」の状態を指します。この場合欠損データの発生原因やその影響を分析した上で、欠損データに対する対処手法を決定する必要があります。
対処手法について、詳しくは後述します。
処理手法
欠損データの処理手法としては、主に3通りがあります。
1.削除する
削除手法には、主に2通りの手法があります。
リストワイズ削除法は、欠損データを含む行・列をすべて削除する手法です。
ペアワイズ削除法は、欠損データの少ない列を残し、そこから欠損している行のみを削除する手法です。
リストワイズ削除法は、欠損したデータ量が少ない際は、解析結果への影響が少ない場合があります。
また、欠損データの発生メカニズムがMCAR(完全ランダム)の場合は、欠損データを無視可能となりますが、
MARの場合は、無視不可能(推定結果に偏りが生じる)となる場合があります。
いずれにしろ削除法は、欠損データ量、発生原因を考慮して行う必要があります。
2.補完する
欠損データを何らかの値で補完する手法があります。適切な手法で補完すれば、完全なデータセットに近い解析結果を得ることが期待できます。
手法には、大きく分けて2通りあります。「単一代入量」「多重代入法」です。
単一代入法とは、字のごとく、特定の単一の値を代入する手法です。
具体的には下記の手法があります。
・平均値代入法
・比例代入法
・回帰代入法
・確率的回帰代入法
・ホットデック法
ここではホットデック法について解説します。
ホットデック法とは、類似するデータを補完する手法です。
例えば、類似した背景を持つ回答者の値を、欠損データに補完するなどです。
メリットは回答者の属性等を解析結果に反映することができる点ですが、
作業が煩雑になることがあり、また欠損データが多い場合には類似データの割り出しが難しく、解析結果に偏りが生じることもあり、適さない手法になります。
多重代入法とは、1つの欠損データに対し、浮く数の値を代入する手法です。
具体的には、下記の手法があります。
・EMアルゴリズムによる補完
・マルコフ連鎖モンテカルロ法
多重代入法を使用するメリットとしては、欠損データが生じる不確実性を考慮した推計を行うことができる点であり、
短所としては、変数の種類や分析の目的に応じて適切な手法を選択しないと、結果にバイアスが小いる点があります。
3.そのまま使用する
統計モデルなどを仮定することで尤度に基づいた解析を行う手法です。
手法としては、「完全情報最尤推定法」などがあります。
注意点
欠損データの解析の際、下記の点に注意する必要があります。
・欠損データが他の値に置き換わっている場合
数値データの場合、0,99などに補完されているケースがあります。データの大部分、または全てが欠損している場合は、変数自体を削除することも一つの手です。
カテゴリー変数の場合、「欠損」という一つのカテゴリーとして扱うのも選択肢の一つでしょう。
・欠損に意味がある場合
その意味がわかる適切な値による補完が必要になります。
例えば「1=ON」という値で登録された変数あった場合、欠損データは「0:OFF」として補完することでバイナリ変数として扱うことが可能となります。
それでは実際のソースコードを見ながら、欠損値を確認していきましょう。
プログラム等の実行環境
Python3
MacBook pro(端末)
PyCharm(IDE)
Jupyter Notebook(Chrome)
Google スライド(Chrome)
欠損値の確認方法
import pandas as pd
# データ取得
user_table = pd.read_csv("./user_table.csv")
# 欠損データ表示
missing_user_table = pd.DataFrame()
for column in user_table.columns:
missing_user_table[column] = [user_table[user_table[column].isnull()].shape[0]]

user_table_drop = user_table.copy()
# リストワイズ削除法
user_table_drop = user_table.dropna()
rows = []
rows_drop = []
for column in user_table.columns:
rows.append(user_table[column].count())
rows_drop.append(user_table_drop[column].count())
df = pd.DataFrame()
df['項目名'] = user_table.columns
df['削除前件数'] = rows
df['削除後件数'] = rows_drop
df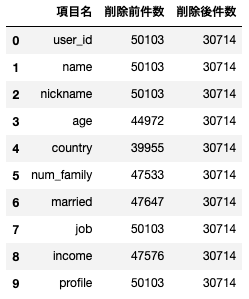
# ペアワイズ削除法
# 欠損値の多い列を削除
drop_df = user_table.drop(columns=['age', 'country'])
# リストワイズ削除法
user_table_drop = drop_df.copy()
user_table_drop = drop_df.dropna()
df = pd.DataFrame()
df['項目名'] = drop_df.columns
rows = []
rows_drop = []
for column in drop_df.columns:
rows.append(drop_df[column].count())
rows_drop.append(user_table_drop[column].count())
df['削除前件数'] = rows
df['削除後件数'] = rows_drop
df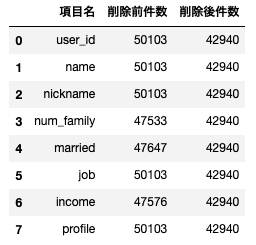
import matplotlib.pyplot as plt
%matplotlib inline
# 描画調整
fig,ax=plt.subplots(figsize = (20 , 5))
ax.set_ylabel('密度')
plt.legend(loc='upper left')
plt.grid()
# 代入前
sns.distplot(user_table['income'], label='before', kde=True, bins=50, color='blue')
# 代入後
user_table_fillna = user_table.copy()
# 平均値代入法
user_table_fillna['income'] = user_table['income'].fillna(user_table['income'].mean())
sns.distplot(user_table_fillna['income'], label='after', kde=True, bins=50, color='red')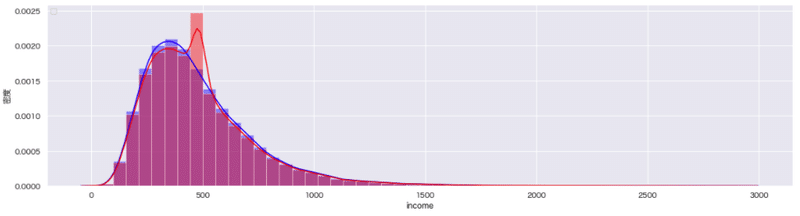
上記の例では、欠損データ数が2527件(全体の5%)あり、単一値(incomeの平均値)で補完していまうと、補完した値が突出して(偏りが出て)しまう。より適切な方法で補完する必要があることがわかる。
どのようなシチュエーションで活用しているのかは、「特徴量エンジニアリング」の記事で総括してまとめていきます。
参考文献
統計データの補完推計に関する調査
「第2章 調査における欠測の分類と対応」
公的統計における欠測値補定の研究:多重代入法と単一代入法
欠損データ分析--完全情報最尤推定法と多重代入法-
解析結果
github/purchase_forecast.ipynb
データセットは「コチラ」の「分析を始める前の準備 > データセットの用意」の章にあります。
まとめ
今回はデータ分析時の欠損データの取り扱い方法について記載しました。
多くのデータではなにかしらの欠損データを含むケースが多く、その扱い方法もケースバイケースであることから、より多くの手法を学ぶ必要性を再確認しました。
今回は記載していませんが、モデリング時には、アルゴリズムによって欠損データの解釈が異なるものがあり、また欠損データを含んで学習できないもの、学習はできるがより適切に補完した方が精度が高く出るもの等あり、欠損データの扱い方法もケースバイケースである為、別途モデリング時の欠損データの扱い方法を記載します。
この記事が気に入ったらサポートをしてみませんか?