
画像生成AIで1000枚画像を作ってわかったこと

仕事で、画像生成AIを使うことがありました。
その中で、1000枚の画像を生成してみて、気づいたことがありましたので、ここに整理しておきます。
自分自身の振り返りメモ的になりますので、あまりオチがありませんが、ご容赦ください😅
まとめ
現在の画像生成AIの技術レベルからして、人物の画像生成は20~50%、動物ならば10~30%ぐらいの割合で失敗作(特に指や関節部分が歪に描かれるなど)となってしまう
対処方法としては、以下が良いと感じた
人物よりも動物の画像にする
画質が粗めの出力スタイル(ピクセルアート、ローポリなど)にする
世界観が出来上がっている出力スタイル(ネオンパンクなど)にする
それらを差し引いても、画像生成AIの威力は凄まじい。このクオリティの画像1000枚を人力で作成したら1年はかかる。。それを8時間程で出来たから驚異的。
さて、それでは以降で詳細を書いていきたいと思います。

活用した生成AIツール
業務上の必要性があったので、このVrewというサービスを用いました。
Vrewは、実は僕も今回の仕事のために、初めて聞いた生成AIツールです。
昨今であれば、人気や話題でいくと
DALL-E
Midjourney
Stable Diffusion
あたりをよく聞くように思います。
また、無料でかなり使える画像生成AIならば、
MyEdit
Canva
Bing Image Creator
など、複数あります。
MyEditとCanvaは、以前の僕のnoteでも使ってみて、使い勝手が良いなとの感想は持っています。
しかし、今回はVrewにしました。
と言うのも、無料のツールは利用の枚数制限があるので、1000枚も作るのはかなり難しいです。
「1000枚の画像を最も安く生成できるツールはどれだ?」
という視点で選ぶと、Vrewに行き着いた、というのが理由です。
ちなみに、1ヶ月の間で1000枚の画像を作るだけならば、
Vrewは716円で使えます。(2024年1月時点)
以下のVrewの価格表で言うところのLightプランになります。
これが決め手でVrewを選びました。
どんな画像を作ったか?
こんな感じのものを作成しました。



基本的にはイラストものです。
対象は、人間や動物、物もありました。
ジャンルは問わず、ですね。
なんせ1000枚も作りますから、様々なタイプの画像を作りました。
なお、風景にあたる画像は作っていません。
Vrewの特徴と画像の作り方
▶︎ Vrewの特徴
そもそもVrewの主目的は、動画の編集のようですね。
それにAI機能を付与しています。
その機能の一つで、テキストから静止画(や動画)の生成も出来るようです。
ちなみに、本社がソウルにあり、韓国のスタートアップですね。
▶︎ 画像生成の仕方
特段難しい操作はありません。
基本的にVrewのHPの説明に従えば十分に出来ます。
簡単にさらっと説明すると、
Vrewのアプリケーションをダウンロード
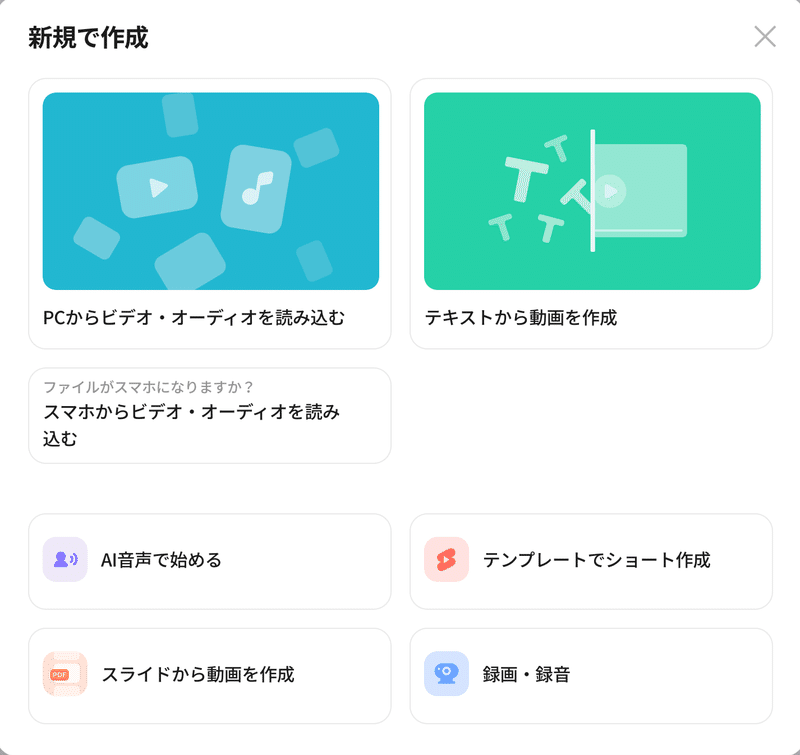
以下の画像で「テキストから動画を作成」を選択(実際には動画ではなく静止画を作成)
作りたい画像のプロンプトを、テキストで入力
以下の画像で、出力する画像生成のタイプを選択
といった感じです。
枚数によりますが、数秒〜数分で生成してくれます。

なお、プロンプトを入力と言っても、話し言葉のような簡単な一文でかまいません。
「踊っている猫」
などの表現で十分です。
これで、Vrewは踊っている猫の画像を作ってくれます。
1000枚生成してわかったこと
▶︎ ポジティブな面
A) 驚異的な威力。作業時間は本当に100分の1になる
いやー、恐れ入りました。
Vrew、すごいです。
というか、画像生成AIが凄いです、ですね。
ほんまにこのクオリティの画像を1000枚作ろうと思ったら、人間が自力でやったら
・作業時間ならば1年以上
・外注したら、金額で500万円ぐらい?
は、かかったと思います。
なんと、それが
・たったの716円
・生成に関わる作業時間は実質8時間ぐらい
で出来てしまいました。
感動ものです。
僕は結構プロンプトをいじったので、8時間もかかってしまいました。
プロンプトを固定して、一気に1000枚を作るのであれば、もしかしたら2時間かからず出来るかもしれません。
さてさて。
とは言っても、「うまく」AIを使わねばなりません。
そういった意味で、今回感じた反省点的なこと、改善点的なことを、以下に整理しておきます。
▶︎ ネガティブな面
B)どう足掻いても10~50%は失敗の画像が生成されてしまう
まず、これは大前提の話です。
今回やってみてわかったこととして、一番大きな学びです。
どれだけプロンプトを工夫したり、生成する画像スタイルを適したものに選択しても、最小でも10%ぐらいは失敗画像が出来てしまいます。
このことを覚悟した上で、画像生成の仕事をせねばなりません。
なので、例えば画像を100枚AIで生成する仕事があるとします。その場合は、110〜150枚は生成するつもりが良いと思います。
ちなみに、画像生成AIにおける”失敗”とは、どんなのでしょうか?
実は、かなり見ることに抵抗がある失敗です。。
noteに掲載するのもはばかられますので載せませんが、例えば人物の画像を作成しても、腕や指の数がおかしかったり、顔が顔でなかったり。。
猫の画像を生成しても、前足のところから尻尾が生えている画像が描かれていたこともありました。。
また、例えば
「ビールを飲む猫」
というプロンプトで画像を生成しようとしても、結果、出力されたのは、猫耳を付けたおじさんがビールを飲んでいる画像でした。
きっと、ビールを飲むというテキストに引っ張られて、AI側ではおじさんを生成してしまったのでしょう。
このように、生成しようとする画像が多岐に渡れば渡るほど(プロンプトが様々なシチュエーションを指定するほど)、不確定要素が大きくなり、従って生成される画像の質もバラつきます。

少し本題とはズレますが、僕がやっている予測AI開発でもそうなんです。
AIに完璧を求めることはほぼ不可能です。
ある程度のズレがあることを前提に、AIを活用するという業務設計が必要です。
そのことを再認識しましたね。
同じことは、ChatGPT などの文章生成AIでも言えると思います。
C) 人物は不気味さが目立つ。動物の方がマシ。
上記のAがメインの理由です。
それから派生して、言えることです。
人間は、当然ながら毎日人間を見て生活しているので、人物の画像を見たときに、違和感があると気付きやすく、また違和感を受け入れ難いです。
また、あくまで僕が今回感じた範囲の話ですが、人間の指や関節はかなり複雑な構造をしており、まだ「なんとなくこんな感じかな」でしか生成を出来ない現代のAIにとっては、緻密な再現を失敗することが多いです。
印象としては、かなり指の部分の画像の生成を、VrewのAIは失敗していましたね。
そういった意味で、まだ動物の方が、人間は気付きにくいと感じました。
つまり、生成AIが、動物の指の部分の画像生成を多少失敗していても、例えば、緻密にライオンの指の構造を覚えている人は少ないように、その失敗に気付きにくいと言えます。
本質的な解決には、なーんにもなっていないことも、僕もわかっています。
が、AIの技術レベルがそういった感じなので、AI利用者側の人間は、それにあわせて仕事を進めないといけないな、ということです。

D) 画質粗めにするなど、出力スタイルや世界観でごまかす。
さて、もう少し力技の対処方法を書いておきたいと思います。
言っても、まだ「なんとなくこんな感じか」で生成しているAIへの付き合い方として、僕は出力スタイルの工夫が一番効果的と思いました。
上述の通り、Vrewは、出力のスタイルを15種類選べます。
この15種類をよく見ると、画質粗めで敢えて出力できるスタイルがあります。
・ピクセルアート
・ローポリ
です。
ピクセルアートは、90年代のファミコンのような画像ですね。
これはもう、細かな描写は一切不要です。
なので、画像生成AIの作成するイラストとしては、かなり適しています。
また、ローポリは、基本的に曲線が無く、直線だけで描かれます。よって、自動的に細かな描写に適していません。
逆に、直線だけで、味わいのある画像になります。(以下のように)
ローポリのスタイルで描かれていると、見る側としても、細かな描写がなくても(例えば指が細かく描かれていない)、ほとんど違和感を感じません。
また、画像生成AIでよくあるのが、体部分の画像と、顔部分の画像が、別途描かれたかのような出力です。
この問題も、ローポリで描かれていれば、違和感を感じにくいです。
また、今回やってみて意外に良かったのが、ネオンパンクです。
このスタイルです。
いや、どんだけイキったウサギやねん。という話です。
ですが、これが良いんです。
世界観が出来上がっているので、AI側としても生成しやすいのかもしれません。
ネオンパンクで生成すると、ほとんどの出力画像が、サングラスをかけてて、帽子ぽいものをかぶって、手袋をして、カッコ良い服を着て、という感じです。
出力スタイルが、ほぼ確立されています。
よって、ネオンパンクで生成すると、どれも似通った感じにはなってしまうというデメリットがあるものの、生成される画像のクオリティは、失敗が少なかったように思います。
E)不気味さが際立つスタイルは写真、アニメなど
これも書いておきます。
写真やアニメなどのスタイルだと、どうしても見る側が、自然と「それなりのクオリティを求める目」で見てしまいます。
画像生成AIも背景や静止物(椅子や机、本など)などは、ほぼ完璧に描けるんです。
それに対して、メインとも言えるキャラクター部分のクオリティが低いと、一気に画像としての完成度が落ちてしまうように感じます。
結果、その画像を採用したくなくなってしまいます。
以下のサンプルは、アニメのスタイルで生成し、上手く出来た方です。
これらのスタイルは、かなり生成の失敗率が高かったですね。
F)ChatGPTのプロンプトは手直し必須
最後に、プロンプトについてです。
ついつい、画像生成AIに生成させる命令文のプロンプトすらも、生成AIに作らせようとしてしまいます。
結果、僕は、ChatGPT が作ったプロンプトをそのまま使ってしまって、最初の100枚ぐらいはかなり低いクオリティの画像を作ってしまいました。
ChatGPT に、プロンプトの叩き台を作らせるのは良いと思います。
でも、まだまだ人間によるチェックは必須だなと思いました。
今回は1000件もプロンプトが必要だったので、全部チェックするのは面倒でしたが、しょうがないです。
具体的には、例えばChatGPT の作るプロンプトは、
「歩く動作の猫の画像」
などと書いていました。
すると、どうも生成される画像のバランスが悪いように感じました。
これよりは、ただシンプルに
「歩いている猫の画像」
とプロンプトを直しました。
この方が、良い画像が生成出来ました。
さらに、以下のような画像を生成するには、プロンプトで
「スーツを着ていて、眼鏡をかけている猫。真剣な表情で正面を向いて・・・」
などと、指示する必要がありました。
ChatGPT も、Vrewに適したプロンプトを書けるわけではありません。
この辺は、かなり人間の手が必要と感じましたね。
長くなりましたが、一旦以上とさせて頂きます。
後半は、ネガティブな記載が多くなりました。
しかし、総じて、Vrewの素晴らしさを感じたという気持ちが90%あります。
とても楽に仕事が出来ました。
素晴らしい体験でした😃
今日も読んで頂いて有難う御座いました😃
最後までお読みいただき有難う御座います! サポート頂ければ嬉しいです😃 クリエイターとしての創作活動と、「自宅でなぜ靴下が片方無くなることがあるのか?」という研究費用に使わせて頂きます!