
お絵描きAIに使われるGANと拡散モデルについて初学者向けに解説してみた(その1 : オートエンコーダー編)

こんにちは、こんばんは teftef です。今回はいよいよ Diffusion Model についての記事です。Diffusion Model は NovelAI や Stable Diffudsion , Midjyouney にも使われている生成モデルの一つです。これまでは生成モデルの覇権をとっていた GAN について 3 記事ほど書いてきて、「 GAN ってすごいよ!」というのをさんざん言ってきたのですが、今回の記事以降では Diffusion Model をめちゃめちゃほめていきます。
それと読み始める前に先に断っておきます。この記事では Diffusion Model にほとんど触れません!!この記事では Diffusion Model の考え方のもとになる変分オートエンコーダー (VAE) についてが9割を占めています。 Diffusion Model の説明はその2でやります。
それでは行きます。
生成モデル
識別モデルと生成モデル
そもそも GAN も Diffusion Model も同じ生成モデルに分類されます。"分類される" と言っているように、生成モデルとは別に『識別モデル』があります。識別モデルは(ほぼすべてが)教師あり学習であり、あるデータ(画像など)を与えられそれが何かを予測するです。それとは違い、生成モデルはデータを元に確率分布を推定する方法です。要はランダムなノイズからデータ(画像など)を確率的に生成します。
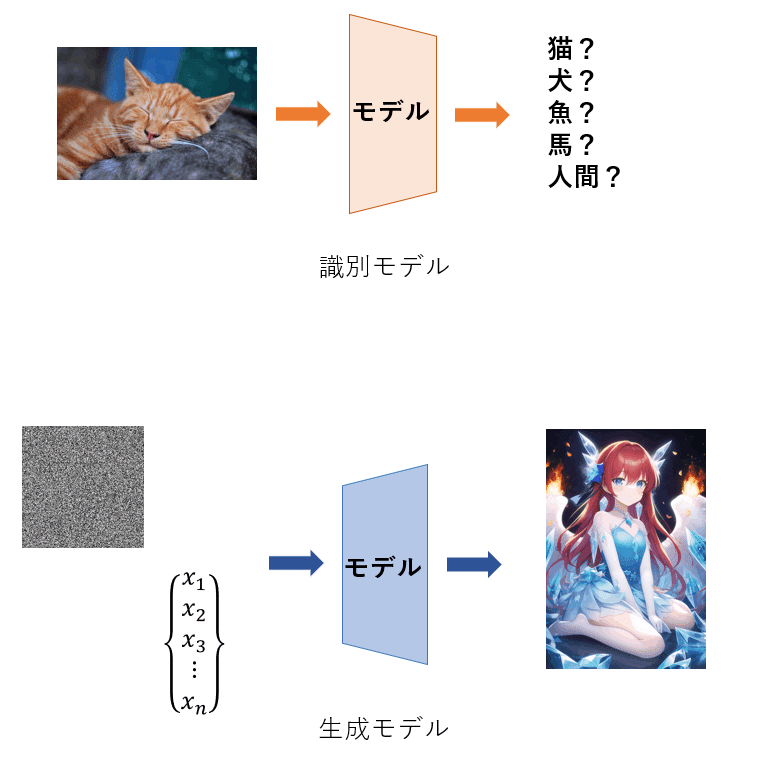
何に使うの?
ではこの生成モデルで何ができるのか、少し例を挙げてみていきます。
まずは何といっても画像生成ですね。NovelAI や Stable Diffudsion , Midjyouney といったサービスのほかに前の解説で扱った Style-GAN , Cycle-GAN のような敵対的生成ネットワーク、GAN と呼ばれる手法がこの分野の花です。また VAE のような復元をするネットワークも生成ネットワークです。これらは手法は多少違えど画像を生成するという使われ方をしています。
続いて音楽生成をする MiniBach、DeepBach なども生成ネットワークに属します。最近では Mubert-Text-to-Music のように text2music も登場しました。
そのほかにもマインクラフトやポケモンをプレイする AIも登場しています。
手法
様々なことができる生成モデルですが、大きく分けて 2 つの手法があります。それが『GAN』と『Diffusion Model』 です。GAN に関しては詳しくはこちらの記事をご覧ください。それではいよいよ Diffusion Model の中身を見ていきます。
AEとVAE
それでは Diffusion Model についてと言いたいところなのですが、まずは Diffusion Model の基礎になったともいわれる VAE(変分オートエンコーダー)について軽く見ていきます。(※興味のない方はこの章は読み飛ばしていただいても構いません)
オートエンコーダー (AE)
まずはオートエンコーダー (AE) についてです。なかなか本題に入れなくてすみません…💦、(でも基礎をしっかり学んだ方がいいと思いまして)
これがオートエンコーダー (AE) です。
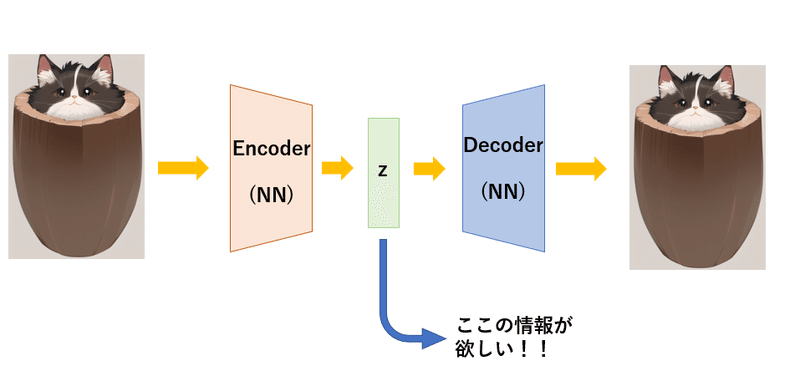
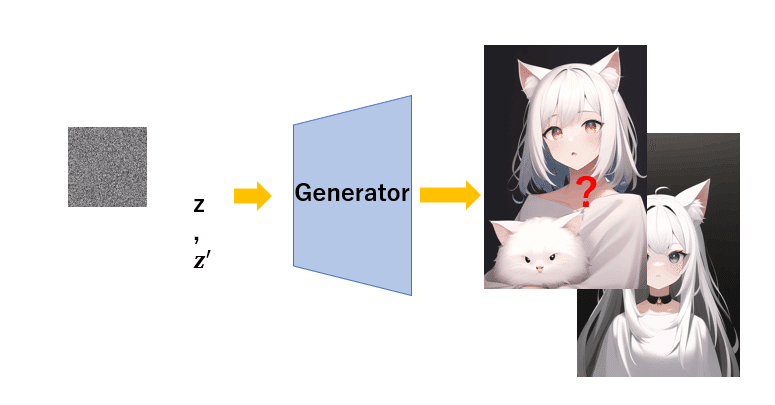
何をやっているかというと、画像の復元です。ん?これ何に使えるんだ?となりますよね。この記事が入っているマガジン『機械学習入門』の一番最初の記事(ニューラルネットワークのやつ)で書きましたが、画像をそのまま処理するのではなく、ニューラルネットワークが処理しやすい形にするために圧縮して処理すると書きました。そう、つまり一回圧縮しなければいけないのです。そして圧縮して一番ノードが少なくなった中間層(ボトルネック)を潜在空間といいましたね。この潜在空間 z がどのようになっているかを知りたいのです。なんで z が必要なのか?それはこのモデルを学習させ終えたときに Decoder が生成器 (Generator) となっていることがわかりますね。つまりここで "いい感じの" z やノイズを入れてあげると、このように画像生成することができます。 "いい感じの" z や "いい感じの" ノイズを調べるためにオートエンコーダーが使われます。
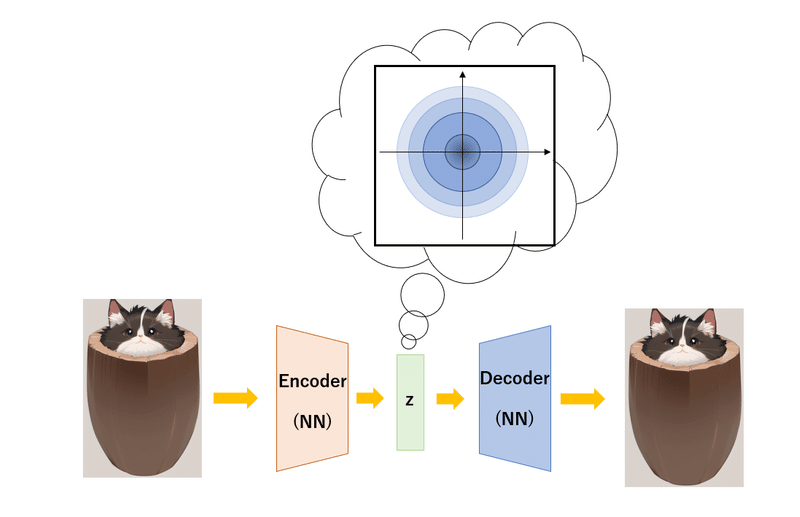
変分オートエンコーダー (VAE)
変分ってなんだ?数式の部分はまた別の機会で解説します。先ほど上で解説したオートエンコーダー (AE) で潜在空間 z が大切であるといいました。しかしこの z 中身を見てみると、もうすごい散らかっているんですよね。そこでこの z をある一定の領域に押し込みたい、散らかり具合をある一定の値以下にしたいというモチベーションのもとで作られたのが変分オートエンコーダー (VAE) です。では何に押し込むのか、それは確率分布です。図にするとこんな感じです。
まだちょっとイメージしづらいですね。では実際に Mnist データセット(手書きの 0~9 の数字を判別するやつ)をオートエンコーダー (AE) と変分オートエンコーダー (VAE) で処理したときの潜在空間を見ていきます。見てみるとオートエンコーダー (AE) では規則なく散らばっているのに対し、変分オートエンコーダー (VAE) では真ん中によっていますよね。それにこちらの方がまとまりがあるように感じます。
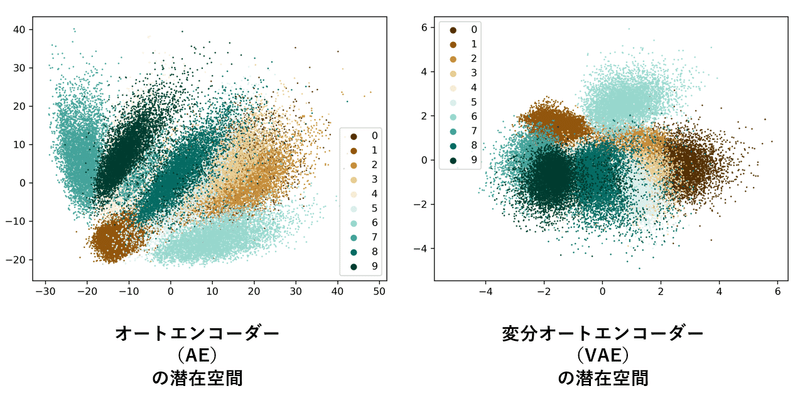
https://thilospinner.com/towards-an-interpretable-latent-space/ より拝借
Interpolation
じゃあ、まとまっている変分オートエンコーダー (VAE) は何がいいのか、それは Interpolation をとった時に滑らかに画像が変化するのです。Interpolation は日本語訳すると『補間』であり、機械学習の分野では潜在空間にある点を動かして、画像を変化させることを意味します。
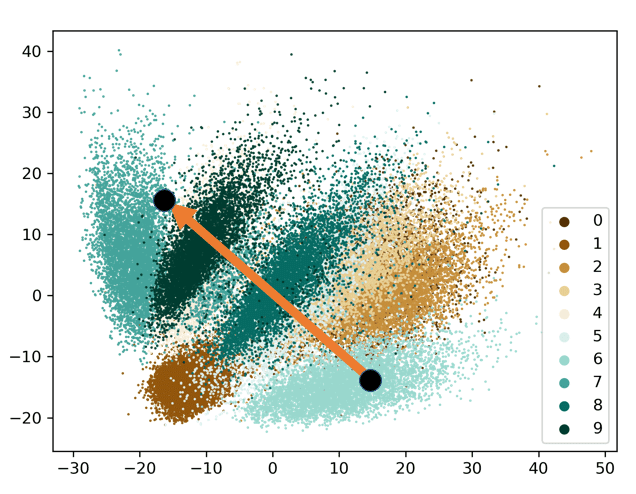
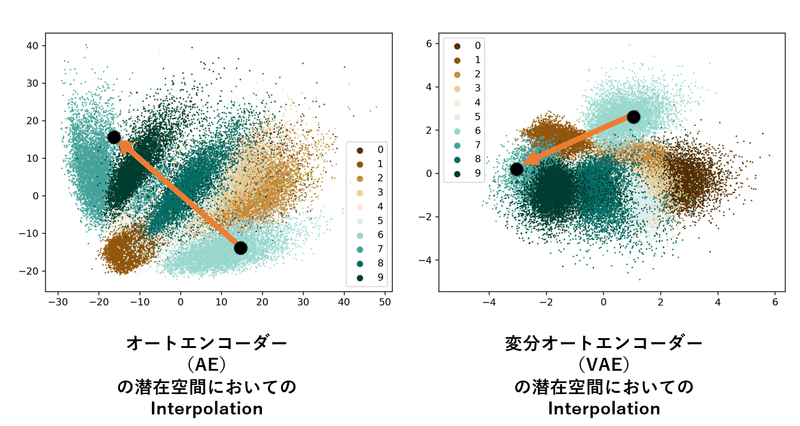
潜在空間 z で Interpolation を行った結果このようになりました (下図)。上がオートエンコーダー (AE) で作成した潜在空間を、下が変分オートエンコーダー (VAE) で作成した潜在空間を使っています。

↓ 変分オートエンコーダー (VAE) で Interpolation を行った結果
https://arxiv.org/pdf/2010.00679.pdf より拝借
するとどうでしょう、下の変分オートエンコーダー (VAE) で作成した潜在空間を使って Interpolation を行った結果のほうが滑らかに推移してませんか?(してますね(^-^)) 実際上のオートエンコーダー (AE) で Interpolation を行った結果は真ん中を見るとよくわからない記号になってしまっています。
ではなんでこうなったか、それは潜在空間において、オートエンコーダー (AE) に比べて変分オートエンコーダー (VAE) はよりまとまっているといいました。すると Interpolation を行ったときの矢印の通る道に注目すると、オートエンコーダー (AE) では点が ”疎” な部分を多く通っていますよね、それに対して変分オートエンコーダー (VAE) では点 "密" な部分を多く通っています。もちろん絶対に直線にする必要はなく、他のルートを考えると両方とも、"密" な部分を通すことが可能ですが、より集まっていたほうが "疎" の部分を通る率が減るのは直感的に明らかですよね。"疎" の部分を Decoder を使って画像に出力すると、数字と数字の間のよくわからない記号が出てきてしまうわけです。
Diffusion Model (原理)
いよいよ Diffusion Model の解説ですが、まずは数学的な話と VAE との関係についてです。ここ意外と大事ですが、わからない場合は数式の部分は飛ばしても (今は) 大丈夫です。
尤度
尤度というのはな馴染みのない言葉ですが、尤もらしさという意味です。こんな漢字初めて見た方が多いのではないでしょうか。主もこの漢字を『尤度』以外で使ったことがありません。犬と間違えないようにしましょう(笑)。では尤度とは何か、英語で書くと Likelihood です。大雑把に言うとこれは無造作に収集したあるデータが理想のデータとそれだけ近いかを表す度合いです。尤度が大きければ理想に近く、小さければ理想とかけ離れた状態です。
モデル
写真を大量に集めます、これをデータといいます。この時無造作に何かしらのデータ X をおそらく確率的に生み出すであろうものをモデルといいます。世の中のデータ全てをかき集めるとそれは正規分布になっていて (中心極限定理より) P(X)とします。この時P(X) は正規分布の確率密度関数でありこれを用意するのは無理でしょう。では膨大なデータを使ってP(X)に非常に近いP'(X)を作ることは可能ですね。これはP(X)を再現した経験分布となっています。ここで P'(X) ≈ q(X) となるように q(X) (確率密度関数)を作ることが目的で、これを 『モデル』といいます。q(X) は P'(X) を真似て作ったのできっと P'(X) のようにふるまうことが予測されます。そしてこの q(X) を P'(X) に(分布を)近づけることを『学習』といいます。そこで使われるのが最尤推定です。
最尤推定とKLdivergence
q(X) を P'(X) に(分布を)近づける、つまり尤度を最大にする手法を最尤推定法といいます。詳しい数式は省略します。次回でも軽く説明するつもりですが、Diffusion Model では、作成したモデルがいかに理想のモデル(正規分布)に近づけるかを『学習』させます。この時 q(X) を P'(X)の距離は以下の式で表すことができ、これを KLdivergence と呼びます。
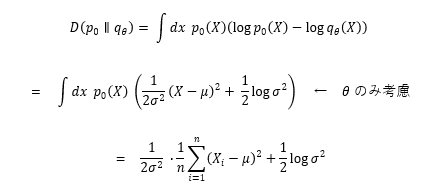
では q(X) を P'(X)の距離を最小(KLdivergence 最小化)にするにはこの式を最小化すればいいので、このように分散と平均を偏微分してやり、それが0になっていればいいですね。
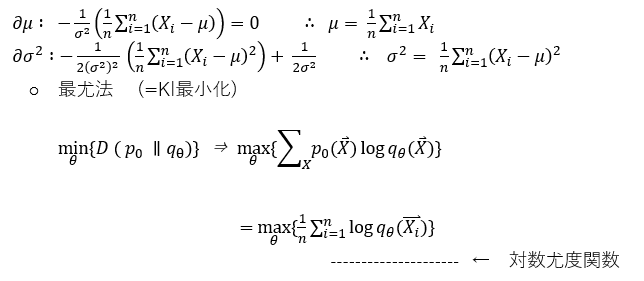
変分下限
結果的に q(X) を P'(X)の距離を近づけるというのは対数尤度関数を最大化すること、要するに尤度を最大にすることになります。この式によってq(X) を P'(X) に(分布を)近づけるように学習されます。で、この対数尤度を最大化するようなパラメータθを求めるときに変分下限を最大化すればいいのです。(かなり端折りました…)この変分下限を求める(KLdivergence 最小化)というのは変分オートエンコーダー (VAE) において損失関数に使われているのです。なので Diffusion model は変分オートエンコーダー (VAE) の原理を元にしているといわれているのです。
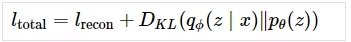
というわけで、変分オートエンコーダー (VAE) について長々と語ってきたのですがいよいよ Diffusion model の大まかな考え方に行きます。と言いたいのですが、長すぎるので次の記事に書きます。
最後に参考にした論文及び記事を載せます。
論文と参照
VAE
interpolation
https://arxiv.org/pdf/1812.04948.pdf
https://arxiv.org/pdf/2010.00679.pdf
Diffusion Model
https://arxiv.org/pdf/2006.11239.pdf
次回予告と宣伝
今回は Diffusion Model と書きながら、ほとんど触れませんでした。代わりに Diffusion Model の基礎になる考えとその使い道、オートエンコーダーについて詳しく書きました。次回の記事、 Diffusion Model 後半では GAN との比較もしていくつもりです。
最後まで読んでいただきありがとうございました。最後に少し宣伝です。主のteftefが運営を行っているdiscordサーバーを載せます。このサーバーではMidjourneyやStble Diffusionのプロンプトを共有したり、研究したりしています。ぜひ参加して、お絵描きAIを探ってみてはいかがでしょう。(teftef)
この記事が気に入ったらサポートをしてみませんか?