
ComfyUI で動かす Stable Diffsion XL

こんにちはこんばんは、teftef です。今回は話題の Stable Diffusion XL についてです。と、言っても使い方の記事は調べればいくらでも出てくると思うので、主は依然として論文解説をします。使い方を見に来たという方々にとってはその目的にに沿わないと思うので、主が特に分かりやすいと思った記事を下に張っておきます。今回は SDXL が条件付けとして画像のサイズを使用していることについて詳しく書いていきます。またそれに対応した ComfyUI についても少し書きます。
私もまだ初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承ください。ぜひコメントなどをいただけたら幸いです。また、この記事を作成するにあたり、GPT-4 による校正、修正が含まれています。
論文
https://github.com/Stability-AI/generative-models/blob/main/assets/sdxl_report.pdf
Stable Diffusion
この記事から読み始めた方もいると思うので、少し復習から入ります。 Stable Diffusion は拡散モデルの一種である潜在拡散モデル( latent diffusion model、LDM)であり、 潜在変数を入力とし、Prompt と呼ばれる自然言語を条件付けにすることで、その Prompt に忠実な画像を生成できます。
以下のように VAE (エンコーダー)を通して画像を潜在空間に埋め込み、ノイズを付与します。ノイズが付与された潜在ベクトル(特徴量)を Unet に入力し、 Prompt から得られたテキスト特徴を条件付けにデノイズしていき、得られた潜在変数を VAE (デコーダー)を通じて実際の写真やイラストに引けを取らない高品質な画像を出力します。
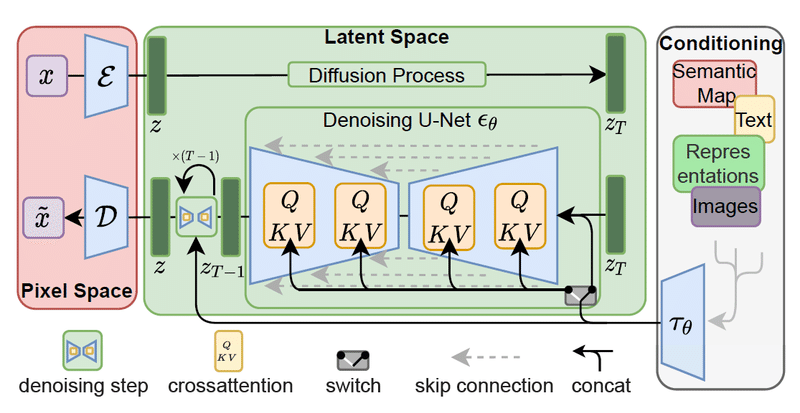
↑ 詳しくはこちらから
Stable Diffusion XL
そんな Stable Diffusion は今まで、基本的な ver 1.0 と Text Encoder にLAIONを用い、さらに潜在空間を増やして学習した ver 2.0 がありました。
今回 の Stable Diffusion XL は Unet のブロックを増やし、画像の高品質化のための Refiner を設けたりとさまざまな改良をこなすことで、1024 * 1024 の画像を生成できるようになりました。
今回はその工夫として、
ネットワークの最適化
画像のサイズを条件付けに用いる
オートエンコーダーの改善
Refiner による超解像
の 4 点を挙げます。
Unet の改良

まずはネットワークが全体的に最適化されています。
SDXL はStable Diffusion と比べて Transformer ブロックの場所を変更しています。具体的には、Unet の浅い層において Transformer ブロックを削除しています。また、Unet の深い層において Transformer ブロックを増やしています。(2つのブロックと 10つのブロック) またUnet の中間にあるボトルネック(Unet のエンコーダーの最終層) の 8×ダウンサンプリング層を削除することで、潜在空間の次元を大きくしています。また、Text Encoder に OpenCLIP ViT bigGとCLIP ViT-Lが組み合わせて使用され、これらが適切に concat されて条件付けとして入力されます。これれの変更によって、Unet のパラメータ数は 2.6 B となっています。
画像サイズを条件付けに用いる
従来手法の Stable Diffusion では 512 × 512 に満たない画像は学習データから排除されていました。これによって学習データの大部分(39%)が消えることになり、精度低下や汎化性能の低下につながります。また 512 × 512 に満たない画像をアップスケールし、それらを学習データに入れる手法も用いられましたが、これはぼやけた画像を生成してしまう可能性があるため却下されています。
クロップを工夫
まず、 Pytorch のバッチをまとめる処理では同じサイズのテンソルが必要なので、基本的には
(i) 画像をリサイズして最短のサイズが目的のターゲットサイズに一致するようにし(アスペクト比は保つ)
(ii) 画像を長い軸に沿ってランダムにクロップする。
という操作を取ります。
例えばターゲットサイズが 256 ピクセルで、元の画像のサイズが 400 ピクセル×300 ピクセルの場合、画像は 256 ピクセル× 342 ピクセル(アスペクト比を保つため)にリサイズされます。256ピクセル×342ピクセルの画像から、ランダムな位置で256ピクセル×256ピクセルの部分をクロップします。
この操作は画像をクロップする際に画像を切ってしまうため、そのような画像を用いて学習されたモデルはこのような画像が生成してしまいます。

この問題を解決するためにデータローダーに、クロップ座標 c_top と c_left(それぞれ、高さ軸と幅軸に沿って左上の角からクロップされたピクセル数を指定する整数)を一様にサンプリングし、それらをフーリエ特徴エンコーディングを介してモデルに条件付けとしてUnet に入力されれます。これによって画像をクロップする際に必要なオブジェクトを切ることなくクロップすることができます。経験上、(c_top , c_left) = (0,0)にすることで、最も良い結果になります。
画像のサイズを工夫
続いて、画像の縦横の長さを c_size =(c_height ,c_width)として学習します。しかし画像のアスペクト数値(単一の数値)をそのまま入力に使うことは学習に用いる表現力が欠如してしまうため (線形であるため)、フーリエ特徴エンコーディングを用いてデータをより高次元のフーリエ領域にマッピングしてから条件付けとして入力します。


実際にこのように、
CIN-512-only (一番上) では、少なくとも一辺が512ピクセル未満のすべての学習データを破棄し、これにより学習用データセットは70k枚の画像で学習する。
CIN-nocond (真ん中) では、全ての学習データを使用しますが、画像サイズによる条件付けは行いません
CIN-size-cond (一番下) では、全てのデータに対して、画像サイズによる条件付けを用いて学習します。
FID 及び IS において CIN-size-cond が最も良い結果となっています。CIN-512-onlyのパフォーマンスが低下した原因は、小さな訓練データセットへの過学習による一般化の悪さであり、CIN-nocond のサンプル分布のぼやけたサンプルのモードの影響がFIDスコアを下げていると考えられます。
正方形以外の画像の学習
しかし正方形の画像以外の画像に対応するために、学習データを異なるアスペクト比のバケットに分け、ピクセル数を可能な限り1024^2ピクセルに近づけ、高さと幅をそれに応じて64の倍数で変えます。モデルはバケットサイズを条件として受け取り、それを整数のタプルcar = (htgt,wtgt)として表現し、それを上記で説明したサイズおよびクロップ条件付けと同様にフーリエ空間に埋め込みます。
以上の操作のアルゴリズムをまとめると
入力 : 画像の集合 D
フラグ ← False
while フラグ do:
x ← D 内からランダムに画像を選ぶ
w_original ← 画像の高さ width(x)
h_original ← 画像の高さ height(x)
c_size ← (w_original , h_original)
if 画像が横長:
左からのクロップ位置 c_left を 0 からwidth(x)−sw の範囲でランダムに選ぶ
c_top = 0
elif 画像が縦長:
上からのクロップ位置 c_top を 0 からheight(x)−sh の範囲でランダムに選ぶ
c_left = 0
c_crop ← (c_top , c_left)
x ← 画像をサイズ s にクロップして左上の座標を c_crop とする
フラグ ← train(x , c_size , c_crop)オートエンコーダーの改良
従来手法のStable Diffusionに使われたのと同じオートエンコーダーアーキテクチャを、より大きなバッチサイズ(256)で訓練し、さらに指数移動平均で重みを追跡した結果、性能向上が見られました。

Refiner
経験的に、得られるモデルは時折、品質が低い画像を生成することがあります。画像の品質を改善するために、同じ潜在空間で高品質で高解像度のデータに特化させた別のLDMを学習します。このリファイメントモデルは最初の200の(離散的な)ノイズスケールに特化しています。推論時には、ベースのSDXLから潜在変数をレンダリングし、リファイメントモデルを使用して潜在空間で拡散過程およびデノイズ過程を行います。(同じ入力を条件付けに使用します)。このステップはオプションですが、詳細な背景や人間の顔の画像の品質を向上させます。

まとめると
以上の要素をまとめるとこのようなアーキテクチャとなっています。
Refiner はあってもなくても問題ありません。

ConfyUI で動かす
ComfyUI の記事はこちらから
Comfy UI でStable Diffusion XL を動かす際にこの通りにノードを組みます。
論文でも書いてある通り、SDXL は入力として画像の縦横の長さがあるのでこのようなノードになるはずです。

Refiner を入れると以下のようになります。

最後に
最後まで読んでいただきありがとうございました。今回は 流行りの SDXL についてです。先日、StableDiffusion WebUI にアップデートが入り、 SDXL が対応したらしいなのですが、おそらく ComfyUI を使ったほうがネットワークの構造をそのまま見ることができるので、分かり易いと思います。
宣伝
最後に少し宣伝です。主のteftefが運営を行っているdiscordサーバーを載せます。このサーバーではMidjourneyやStble Diffusionのプロンプトを共有したり、研究したりしています。ぜひ参加して、お絵描きAIを探ってみてはいかがでしょう。(4500 字,teftef)
↓↓もしよろしければこの記事と開発の支援お願いいたします!
※注意 : 支援してくださる方へ
※注意 : ここから先は何も内容がありません。しかし、この記事をお読みいただき、良かったと感じていただけたのであれば、この記事と開発の支援お願いいたします!
ここから先は
¥ 500
この記事が気に入ったらサポートをしてみませんか?