
AI を自分好みに調整できる、追加学習まとめ (その1 : 概要)

こんにちは、こんばんは teftef です。今回は最近流行りの「追加学習」について書いていこうと思います。今回の記事は追加学習の大まかな解説とどのような手法があるのかについてまとめていきます。私もまだつい最近まで初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承ください。ぜひコメントなどをいただけたら幸いです。
モデルの作成
AI (人工知能) を作るためには多くの手順がかかります。
まずはデータを用意して、そのデータにラベルと呼ばれる「正解」データを付与させます。
続いて、うまくそのデータを学習させるためのニューラルネットワークを組みます。
そして大量の GPU と 電気代を払って学習を回します。
1 回で成功できるわけではありません。何回も失敗を繰り返し、原因究明し、それを元にハイパーパラメーター調整をする… (3,4 をひたすら繰り返す)
やっとの思いで作ったモデルを使ってそれに見合うだけの対価を得ることはとても難しいのです。しかもおまけに「で、それ何の意味あるの?」って教授とか偉い人に言われたらメンタル崩壊です…
追加学習の意味
短時間かつ小計算量で自分の欲しいモデルを作りたい!というか、できれば楽したい!そんなことを主は常に思っているのです。
そこで、使えるのが「追加学習」たちです。追加学習というのは大まかに説明すると、誰かほかの人が学習させた学習済みモデルに対して自分好みに変更したり、学習させたりするときに、0から学習するのではなく、学習済みのネットワークをある程度活用して学習する手法の一つです。追加学習には様々な手法があり今回は大きく分けて 3 つあり、今回はその『転移学習』『ファインチューニング』『蒸留』についてそれを使うメリットとデメリット、簡単な概要を説明していきたいと思います。それぞれの要素と詳細についてはまた順次解説を出していきたいと思います。
転移学習 (Transfer Learning)
概要
まずは転移学習(Transfer Learning)についてです。やっていることをわかりやすく身近な例で話します。「ピアノ弾ける人にヴァイオリンを教えると上達が早い」というのはなんとなく想像しやすいのではないでしょうか。「音楽」という知識の土台を持っているのでより早く上達するのとほぼ同じような感覚です。
手順
それでは転移学習が何をやっているかをざっくり書いていきます。まずは学習済みモデルを用意します。そのモデルの最終ノードを消して、これを使って「特徴量」を取り出します。つまり最終層の1つ前の部分を取り出すという感じです。続いて先ほど消したところに新しくノードをいくつか追加します。そしてモデルの再学習を行います。ここで学習時にネットワークの浅いほうの学習率を 0 にしてやる(重みを凍結する)と過適合を防ぐことができます。最後に転移後のモデルの評価をします。(個々の理由は後程)

メリット、デメリット
転移学習ではデータが少ないケースに有効な手法となっています。今までの大量のデータに対してある程度の知識を有した状態で学習し始めるので、限られたデータでもそのまたこれはすべての追加学習に共通しますが、学習済みモデルをほぼ丸ごと使うので、モデルを0から作る時と比べて短時間で済ますことができます。
しかし一つだ注意するとすれば、常にうまく学習できるとは限らず、転移の方法を間違えたりすると負転移(negative transfer)が起こってしまいます。なので最後に転移後のモデルと元のモデルを比べて評価します。
蒸留 (Distilation)
概要
この手法は、学習済みのモデルを「教師モデル」と呼び、学習させたいモデルを「生徒モデル」と呼びます。そう、お察しがいい方はもうお気づきかもですが、蒸留は教師が生徒を教えることを参考にしています。
手順
まず、教師モデルとして予測精度が良い学習済みモデルを用意します。続いて何も学習させていないモデルを用意して、これを生徒モデルとします。あとは簡単、教師モデルを使って生徒モデルを学習させてしまえばいいのです。
少し詳しく説明します、soft target loss と hard target loss という2つの損失関数を小さくすることで学習します。soft target loss は簡単に言うと学習モデルの生成した出力と生徒モデルが生成した出力の差です。 hard target loss は正解出力(真値)とです。生徒モデルが生成した出力の差です。
この中でも特に soft target loss というのが非常に重要で、正解だけを学ぶのではなく、敢えて教師モデルが生成した間違いを含んだデータについて学ばせます。
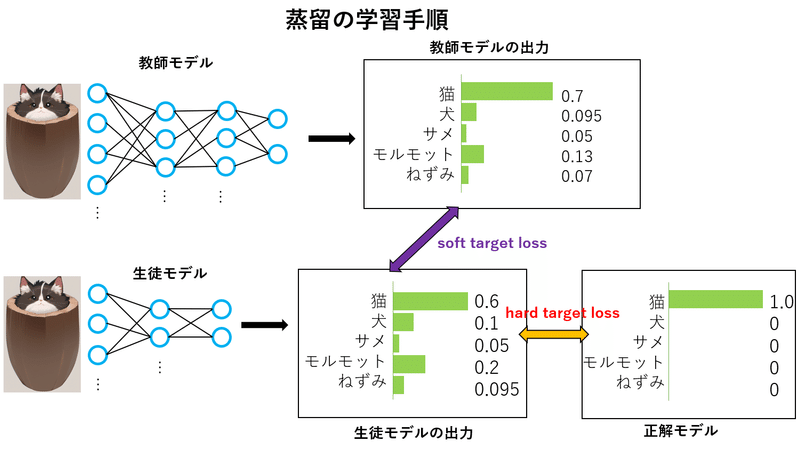
http://codecrafthouse.jp/p/2018/01/knowledge-distillation/ 参照
メリット、デメリット
まずはもちろん何といっても時間と計算量を節約できます。また使用する生徒モデルは小さいモデルにすることができます。しかし人間とは違って、生徒が教師を超えることはなかなか難しく、生徒は教師を超えることはなく、限りなく近づくことしかできないようです。
ファインチューニング (fine tuning)
概要
これを一言で表すと微調整です。転移学習だと既存のネットワークに少しノードを付加させて学習させています。だいぶ時間と計算量を抑えることができたのですが、追加学習したいデータの量が多すぎると逆にもっと時間がかかってしまうことがあります。こういう時にファインチューニングが使えます。ファインチューニングでは学習済みモデルのネットワーク全体 (もしくは大部分) の重み全体を学習させます。
手順
これに関しては手順はもうほとんど説明済みで、追加データを用意し、学習済みモデルのパラメータを調整していきます。詳しい調整法はまた別の記事でファインチューニングに特化して書こうと思います。
メリット、デメリット
追加学習したいデータを大量に持っていてるときにファインチューニングを使うと過学習を起こしにくくいです。直感的にも既存の優れた学習済みモデルのパラメーターを調整するので、ベースがしっかりとできているとわかります。ただし転移学習に比べてデータを大量に必要とすることや、学習時間と計算量が多くなってしまうのはトレードオフとなっています。
ファインチューニングの学習はこちら↓
その他、少し変わった手法
ここから先は、違った手法の追加学習です。ファインチューニングに近いのですが、一応分けておきました。
Textual Inversion
追加学習の一つです。学習させたい画像の "スタイル" を「擬似単語」として emdedding 空間に埋め込み、それを元に画像を出力させます。言語として表しにくい画像やその画像の絵柄を元にした画像が出てきます。
DreamBooth
追加学習の一つです。学習させたい画像を [Identifier] として emdedding 空間に埋め込み、それを元にText Transformer , Unet をファインチューニングし、画像を出力させます。言語として表しにくい画像やその画像の絵柄を元にした画像が出てきます。Textual Inversion と比べてこちらのほうが忠実に再現できますが、時間とリソースが要求されます。
hypernetwork の調整(学習)
lattent diffusion Model の追加学習の一つです。学習済みモデルのパラメーターを変化させずに学習させます。これに関してはあまり多くの情報がないため、こちらの記事を参考にしていただいた方がわかりやすいと思います。
学習方法はこちら↓
データセットの収集
出典
次回予告と宣伝
今回は追加学習の手法『転移学習』『ファインチューニング』『蒸留』を大まかにまとめました。それぞれの詳しい手法や論文に関してはまた後々記事を書こうと思っています。ボルツマンマシンについては追加学習の話が終わったら書こうと思っています。次回は textual inversion についてです。
最後まで読んでいただきありがとうございました。最後に少し宣伝です。主のteftefが運営を行っているdiscordサーバーを載せます。このサーバーではMidjourneyやStble Diffusionのプロンプトを共有したり、研究したりしています。ぜひ参加して、お絵描きAIを探ってみてはいかがでしょう。(teftef)
この記事が気に入ったらサポートをしてみませんか?