
ComfyUI で動かす Latent Consistency Models LoRA (LCM-LoRA)

こんにちはこんばんは、teftef です。 Latent Consistency Models の LoRA (LCM-LoRA) が公開されて、 Stable diffusion , SDXL のデノイズ過程が爆速でできるようになりました。LoRA なので既存モデルでも使えます。今回は ComfyUI でその LCM-LoRA を使用する方法についてです。(いつもの論文とかは後で書きます。)
※この記事は有料となっていますが、最後まで内容が読めます。
私もまだ初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承ください。ぜひコメントなどをいただけたら幸いです。また、この記事を作成するにあたり、GPT-4 による校正、修正が含まれています。
Latent Consistency Models
Consistency Models と Latent Consistency Model について、詳しくは、こちらを見てください。見なくても使えます、でも読んでくれたらうれしいです。
ComfyUI
よく使っている Stable Diffusion webUI とは異なり、ComfyUI という GUI もあります。
詳しい導入と使い方はこちらから。
Comfy UI で LCM-LoRA を使う
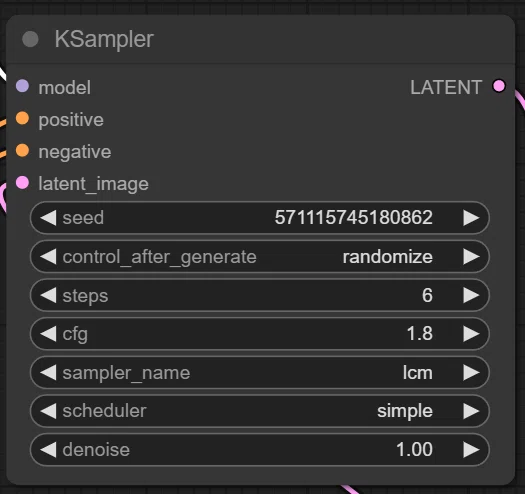
ノード配置 (SD1.5)
以下の画像のような感じで配置します。Sampling の部分を全部 lcm にするのを忘れずに。

配置を読み込む json file はこちらで配布します。
https://drive.google.com/file/d/1HDtAT1E5J4xWK0zNLVoACgElwrWsCeF1/view?usp=sharing
LCM-LoRA のダウンロード
LoRA モデルのダウンロードはこちらから行い、指定の場所 (ComfyUI\models\loras) に入れてください。
画像生成
ノードが組み終わったら、画像生成をしましょう。 cfg スケールは小さめに指定することをお勧めします。
lcm は少ないステップ数で画像を生成できることが売りなので steps = 5~6 ステップくらいで大丈夫です
upscale
Hires fix の部分も LCM-LoRA を 入れることによって爆速生成することができます。

ノードの json はこちらに置いておきます。
https://drive.google.com/file/d/1Uxln8Ue7XNEFOt1MigZ6Ca8NZBNjn3UZ/view?usp=sharing
生成速度
今回、画像生成に使用した GPU は RTX 2070 Super です。
512 × 512 の縦長画像を 10 枚生成したところ 10 秒かかりませんでした。
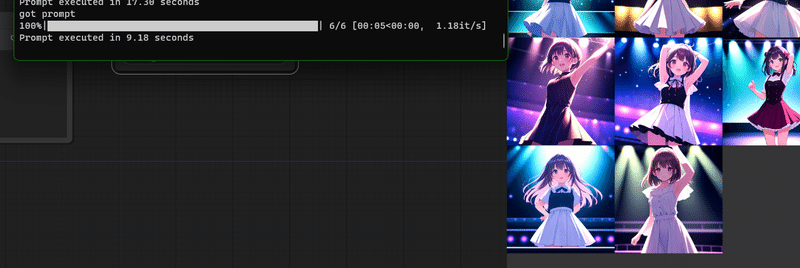
512 × 768 の縦長画像を 10 枚生成したところ 15 秒ちょっとでした。

512 × 768 の縦長画像を 10 枚生成し、さらに upscale をすると 100 秒くらいです。

おまけ : 他の LoRA と組み合わせる
LoRA を複数個利用するときはこのように直列でつなぎます。

最後に
Latent Consistency Models LoRA を ComfyUI で使う時の方法についてざっくり書きました。 Consistency Models については、なんかさんの記事がものすごくわかり良いのでぜひ、ご一読ください。
最後に少し宣伝です。主のteftefが運営を行っているdiscordサーバーを載せます。このサーバーではMidjourneyやStble Diffusionのプロンプトを共有したり、研究したりしています。ぜひ参加して、お絵描きAIを探ってみてはいかがでしょう。(1,500 字,teftef)
↓↓もしよろしければこの記事と開発の支援お願いいたします!
※注意 : 支援してくださる方へ
※注意 :ここから先は何も内容がありません。しかし、この記事をお読みいただき、良かったと感じていただけたのであれば、この記事と開発の支援お願いいたします!
ここから先は
¥ 500
この記事が気に入ったらサポートをしてみませんか?