ポケモン対戦エージェント : POKE´LLMON

こんにちはこんばんは、teftef です。今回は,ポケモンを LLM でプレイしてみたという論文です。ぱっと見た感じ見た感じよくある「エージェント」の論文ですが、ちょっと結果が面白かったので、メモ程度に書いていこうと思います。(主がポケモンをやっていたから気になるというのもあります。)
私もまだ初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承ください。ぜひコメントなどをいただけたら幸いです。また、この記事を作成するにあたり、GPT-4 による校正、修正が含まれています。
※この記事は有料となっていますが、最後まで内容が読めます。
エージェント
LLM を用いたエージェントに関する論文はこれまでいくつか出ていて、
「ザ・シムズ」のようにプレイヤー間のやり取りを調べた論文や Mincraft のようなオープンワールドでエージェントの行動を調べたりする論文があり、いわゆるサンドボックスゲームでエージェントを構築する研究がいくつかされています。これらはの試みは強化学習を用いた手法が多く提案されており、 2023 年に GPT が台頭してから、 LLM を使っていくという手法が散見されるようになりました。
将棋やカードゲームのような対戦ゲームも強化学習を用いた手法やそもそも機械学習を用いないアルゴリズム的な手法が主流であり、LLM を使ってタスクを遂行するというのは珍しく思います。
LLM の発展により、サンドボックスゲームだけでなく、対人ゲームでも 使えるのではないかという論文をいくつか見るようになりました。
エージェントの問題点
これらのエージェントの論文を読んでいると、LLMが「ハルシネーション」と呼ばれる状態に陥いてしまい、克服する方法が多く提案されています。LLM における「ハルシネーション」は、同じような単語を無限ループしてしまうことであり、今回の POKE´LLMON においても、相手に効果のない技を連続で打ったり、相性が不利なタイプのポケモンを出し続けてしまうといったことが確認されています。
また、パニックスイッチと呼ばれる、エージェントが強力なポケモンに遭遇したときにパニックに陥り、連続して異なるポケモンを交換してしまうといった現象が発生します。
これらの問題を解消しつつ、対人戦で勝率を高めることを目標とします。
POKE´LLMON
ポケモン対戦の簡単なルール
ポケモン対戦をやったことがある方ならもうわかると思いますが一応書いておきます。
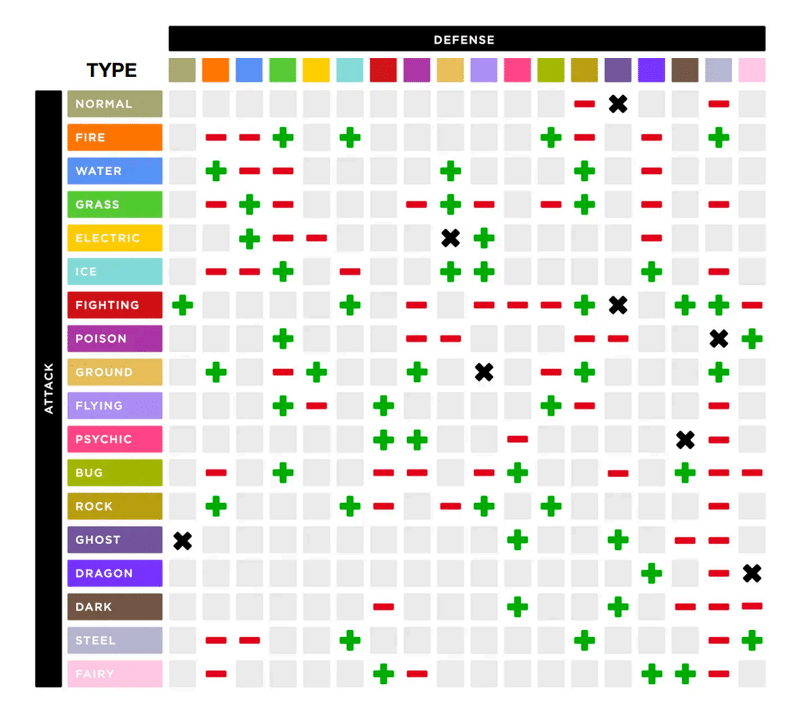
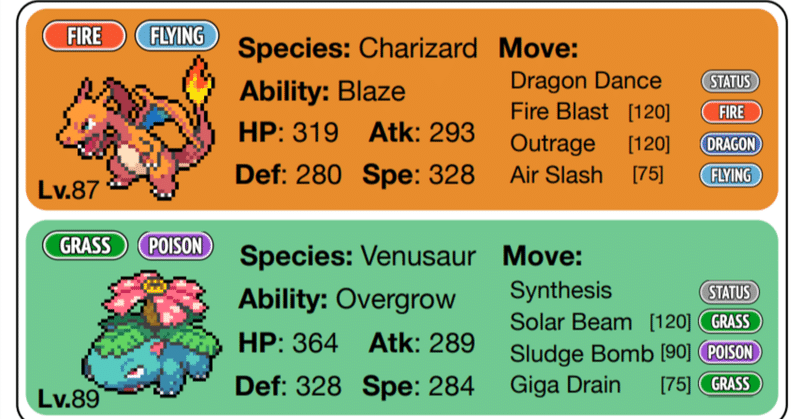
ポケモンは 1~2 つのタイプがあり、それぞれ4つの技を覚えます。
1ターンずつ動作を選択し、攻撃をするか、交代をするかの選択を行います。攻撃を行う時はHP、攻撃、防御、特攻、特防、素早さの6つのパラメーターとタイプ相性、天候、状態を参照して与ダメージと被ダメージが計算されます。技にはダメージを与える攻撃技とバフやデバフをかける変化技があります。交代するときは、それが1ターンとカウントされ、そのターンは行動できません。もちろん例外はありますが、基本的に上記のルールで進んでいきます。
環境
プレイの環境は、pokemon showdown を用い、ローカルでサーバー構築を行います。
プレイした際の Log を json 形式で記録し、LLMでできた bot に渡してその返答を入力します。
LLM ごとの違い

まずは、何も考えずに 様々な LLM を用いた結果です。当たり前ですが、何の工夫もないので勝率はとても低いです。その中でも GPT-4 は他の LLM を突き放してダントツに精度がいいことがわかります。この先は基本的に GPT-4 を使っていきます。
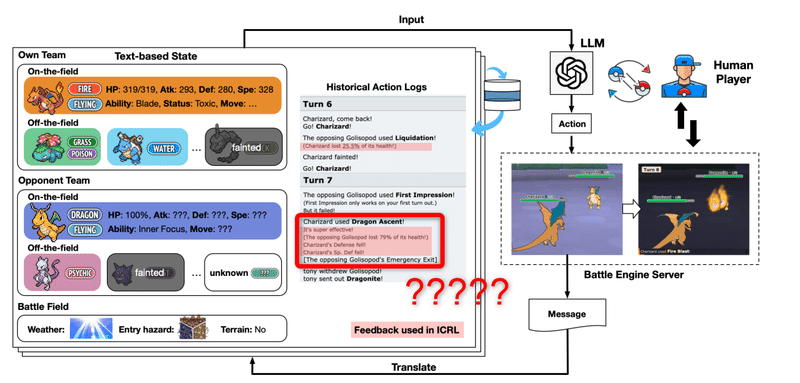
全体の構造

構造は上のようになっていて、行動や技、場の状態、ポケモンの名前や状態、パーティーのポケモンの構成 (相手の技やステータスや持ち物、特性はわからない) を LLM に入力していきます。基本的に人間と対戦した際のスコアを算出します。
工夫① : ICLR (In-Context Reinforcement Learning)
対戦を通じて、効果なしの技を連続して撃っていたり、攻撃を無効にする特性に同じ技を撃つことがあります。これは、LL< に渡す情報に状態説明に含まれないためです。
そこで、対戦 Log だけではなく、 行動をした後のフィードバックを LLM に渡すようにします。こうすることで、前ターンまでの情報をしっかりと考慮して意思決定を行います。攻撃による 2 ターンにおけるHPの変化、攻撃の効果(効果抜群など)、行動の順番、ステータス変化など、4種類のフィードバックが生成されます。

工夫② : KAG (Knowledge-Augmented Generation)
ハルシネーション防止のために、事前知識(ポケモン攻略サイトにある基本情報)を導入します。相性や技の特性、効果などを事前に LLM に渡しておきます。


鋼フェアリータイプのクレッフィの弱点は地面・炎であり「いたずら心」という変化技の優先度が +0.5 される特性を持っている。地面タイプのポケモンでガブリアスやランドロスは炎技を持ていることが少ない。これらのポケモンの前で電磁浮遊を先制して撃つことで、地面タイプ弱点を消して、しっかりと役割遂行できるという、割と流行った型だぞ!(オタク)
工夫③ : 一貫性のある行動、CAG (Consistent Action Generation)
LLM の出力結果の信頼性を上げるためにいくつかの工夫があります。
CoT(Chain-of-Thought)は今までの戦況を分析するような文章を生成し、それを元に次の行動を決定します。
Self-Consistency (SC) は、 LLM の出力を n 回生成しそれらの結果に対して、投票を行い、最も投票されたものを答えとして次の行動を決定します。
Tree-of-Thought (ToT) はSC と似ていて、n つの行動を生成し、自ら評価した最良のものを選びます。( 正直SC との違いが判らない)
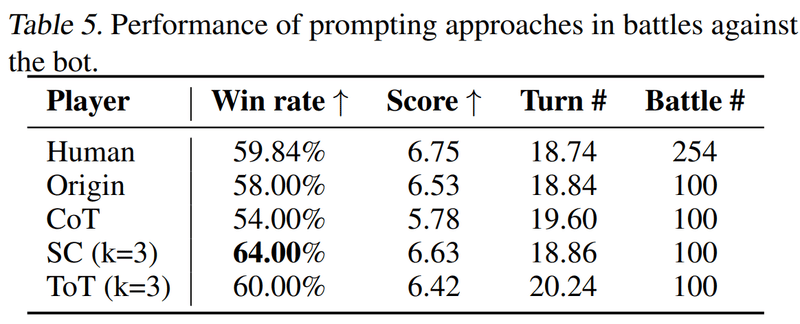
CoT(Chain-of-Thought)によってスコアが下がってしまいました。対して、 SC や ToT ではスコアを向上させることが空できました。これはおそらく、CoT に大きな問題がある (CoT には他の問題がある) というより、LLM の出した行動の自体の精度 (合理的な行動をする精度) が低くいのが問題なのではないかと思っています。
LSI (Large Scale Integration) の設計でも、投票システム()を採用することで、システムの信頼性を上げるような設計をすることがあり、それが、まさに Self-Consistency (SC) や Tree-of-Thought (ToT) のようなものです。この設計はどのエージェントを作るのにおいても参考になるものだと考えていて、実行時間との兼ね合いを見て投票システムを設計することが大きな信頼度向上につながりそうです。
システムの最終的な設計図

最終的な勝率がこのようになりました。

一般の対戦(フリーバトルのようなもの)では勝率が 48.57 % で、長年対戦しているプレイヤー(15年以上) と対戦させた際の勝率が 56.00 % でした。
推測ですが、長くプレイをしている人は、良くあるミスをしません。(例えばエーフィーに変化技を撃ったりしませんし、型破りドリュウズの前にミミッキュを出したり忘れがちなミス) そのため、合理的な行動が多く、LLM もプレイヤーのミスから突然起こる合理的でない行動によって乱されることがないからではないでしょうか。対して、一般の対戦では様々なレベルのプレイヤーがいて、突然起こる合理的でない行動によって LLM の出力する結果もかなり影響があるのではないでしょうか。
問題点
パニックスイッチ
CoT によって生成された結果にパニックスイッチが見られます。自分より強いポケモンと対面したときの行動として、交代をすることで有利な盤面にできることがあります。しかし、交代した先のポケモンが「耐久はあるが相手より遅い」ポケモンとなった時に、LLM は「相手より遅いかつ相手打点がある」という思考に陥り、交換を繰り返すことがあります。これは、LLM が未来の行動を予測して次の行動をするということができていないからであると思っています。(似たようなことを論文も考察している)
受けループ

は有名な受けループ
あと一枠はメガヤドランやメガヤミラミを入れることもある
このよう、得意の耐久とタイプ相性を盾に、毒を使って相手の HP を削り、回復技を使って自分のHP を確保するパーティに弱いです。「自己再生」は1ターンでHPの50%を回復するため、もし攻撃が相手ポケモンに1ターンで50%以上のHPダメージを与えない場合、(急所に当たらない限りは) 一生倒すことができません。対策として、剣の舞など自身にバフを付けて、回復が追い付かないダメージを与えることがありますが、このエージェントは長期的な戦略を考慮に入れていないため、このように長いターンをかけて相手を倒すような構築に対する弱さを持っています。
釣り交換

ジガルデ(自分)とクチート(相手) の対面でクチートには地面が抜群なので、ホワイトキュレムに交換します。(ここなんでこの交換をするか正直よくわからん)
キュレムはドラゴン技が抜群なので、相手はジガルデのドラゴン技を誘います。
続いて、フェアリータイプのカプ・ブルルに交換することでドラゴン技を無効にして、有理対面を作ります。
(別にすぐにカプ・ブルルに交換でよくね?と思うのは主だけでしょうか) オタク
釣り交換は相手に効果抜群の技を撃たせることを狙って、効果なしタイプや耐性があるタイプに交換することで盤面を有利にするテクニックです。
LLM が見事に釣られていることがわかります。これもやはりLLM が未来の行動を予測して判断を出していない (現在の状態情報のみに基づいて決定している) ためと考えられます。うまいプレイヤーは相手の未来の行動を読んで行動を選択することが多く、簡単に LLM を釣ることができてしまいます。
まとめ
LLMを用いたエージェントでポケモン対戦をするという試みであり、一般の対戦(フリーバトルのようなもの)では勝率が 48.57 % で、長年対戦しているプレイヤー(15年以上) と対戦させた際の勝率が 56.00 % を達成しました。ICRL 、KAG、CAG の3つの手法で、ハルシネーションに対処し合理的な判断を行う対戦エージェントを構築しています。これはどのタイプのエージェントを作成するにあたっても参考にできるのではないでしょうか?
これまで3種類のエージェントに関する論文や文章を見てきましたが、やはり「長期的な未来を予測して次の行動を決める」ということが苦手に感じます。今回に限らず、目の前の目標を達成することに全力を尽くすようになっています。この能力は DNN を使って何とかなるものなのかなーと疑問に思っています。記憶の研究は Transformer や LSTM など様々なアーキテクチャが出てきていますが、長期的な未来予測のアーキテクチャはあんまり知らないので、面白いものがあったら教えていただきたいです。
余談
これチートじゃね?
参考文献
最後に
というわけで、今回はポケモンをプレイする対人ゲームエージェントについて書きました。個人的にはこのように「え?おもしろそう!」と思える論文って、その分野に興味を持つきっかけになったりするので、批判するのはどうかと思っています。
個人的な偏見かもしれませんが、学術って、興味を持ってもらえない理由に難しすぎて、どこから入るかわからないっていうのが多いと思うんですよね。偉い人に聞こうとしても「もっと勉強して来い」とか言われそうで怖いですし、参考書買ってもよくわからないことが多いと思います。それを、如何に面白く伝えるか、興味を持ってもらえるかが大切だと思っています。(というか「この分野あんまり注目されなくて…」って言ってるのを聞くと、「PR 下手だからじゃない?」と思ってしまいます。)
最後に少し宣伝です。主のteftefが運営を行っているdiscordサーバーを載せます。このサーバーでは Midjourney やStable Diffusionのプロンプトを共有したり、研究したりしています。ぜひ参加して、お絵描きAIを探ってみてはいかがでしょう。(5,500 字,teftef)
↓↓もしよろしければこの記事と開発の支援お願いいたします!
※注意 : 支援してくださる方へ
※注意 :ここから先は何も内容がありません。しかし、この記事をお読みいただき、良かったと感じていただけたのであれば、この記事と開発の支援お願いいたします!
ここから先は
¥ 500
この記事が気に入ったらサポートをしてみませんか?