
情報銀行は本当にワークするのか

「データは21世紀の石油である」と言われ、生活・ビジネス全般のデジタル化進展が著しく、一方でGAFAのデータ占有が問題視されるなど、データ・情報に大きな注目が集まっている。
そうしたなかで、政府主導で提唱され、総務省と日本IT団体連盟が開催した「認定に関する説明会」には当初想定の約4倍と多数の企業が殺到するなど、関心を集めているのが「情報銀行」である。
情報銀行とは
内閣官房IT総合戦略室が実施した「AI、IoT時代におけるデータ活用ワーキンググループ」の中間とりまとめによれば、情報銀行のイメージおよび定義は以下の通りである。
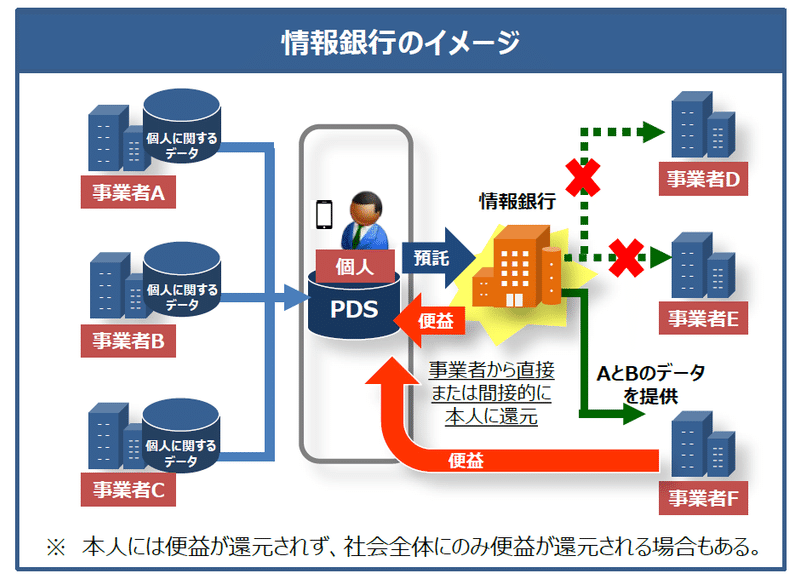
「情報銀行(情報利用信用銀行)とは、個人とのデータ活用に関する契約等に基づき、PDS等のシステムを活用して個人のデータを管理するとともに、個人の指示又は予め指定した条件に基づき個人に代わり妥当性を判断の上、データを第三者(他の事業者)に提供する事業。」
(PDSは、Personal Data Storeの略)
狙いは、「情報・データの活用を促進すること」、それが「個人の関与・コントロールの下で行われること」、ただし個人はノウハウやシステムを保有していないケースが多いことから「事業体=情報銀行が個人を代行すること」ということになろうか。GAFAのような大規模事業者から、個人にコントロールを取り戻す、ということも狙っているのかもしれない。
銀行が「お金」の活用を促進する仕組みは大雑把に言えば、
「預金としてお金を集め、貸出として資金ニーズがある事業体に提供して利息を受け取り、その一部を預金者に利息として還元する」
ということである。
このアナロジーで言えば、「情報」の活用を促進する仕組みとして、「情報を集めて、情報の活用ニーズがある事業体に提供して利用料を受け取り、その一部を情報の対象である個人に還元する」ということができる。
一見うまくいきそうであるが、本当にワークするのだろうか、考えてみよう。
関係者それぞれの立場から見た問題点
■情報提供者
情報銀行の仕組みは、情報提供者(=データを保有している事業者、上図のA・B・C)がデータを提供することが前提となっている。
しかし、「データを保有している事業者」は本当にデータを提供するのだろうか。
例えば、Amazonは、自社のビジネスにフル活用して競争力の源泉となっている「顧客の購買データや閲覧データ」を情報銀行に提供するのだろうか、同様にGoogleは「ユーザーの検索データ」を提供するのだろうか。
先にあげた「情報銀行のイメージ図」でもそうであるが、「AI、IoT時代におけるデータ活用ワーキンググループ」中間とりまとめの概要を見ても、「データを保有している事業者」がデータを提供することへのインセンティブについては明記されていない。
まさか、親方日の丸が命じれば提供するだろう、と思っているわけでもないであろうが、事業者はデータを取得し保管・管理するにもコストがかかっている。
これを外部に提供するとなれば、そのための開発や運用コストもかかることからすると、無償は難しいのではないか、と考えられる。仮に有償だとしたら、少なくともこうしたコストに見合う水準であることが求められる。
それよりも本質的な問題として、
AmazonやGoogleを例としてあげたように、それが有効なデータ、活用することがビジネスにつながるデータであればあるほど、外部提供などせずにデータを囲い込んでいく、自分だけがそのデータの恩恵を享ける戦略に向かうのではないだろうか。
「そのデータは個人のデータであり、事業者には囲い込む権利はない」と決めつけて、データを保有する権利を否定したり、データ提供を強制したりすることは可能なのだろうか。
いや、例えばAmazonで買い物した記録は、個人の購買データである一方で、Amazonにとっても自社の取引記録であり、保有する権利は否定できないだろう。
事業者の立場からは、個人がデータを必要とするのであれば購入記録として個人が自分でデータ化(Excelに入力しておくとか)すればいいではないか、それを情報銀行に提供すればいいではないか、ということになるのではないだろうか。
(ただし、後述するように、データの信ぴょう性や、ハンドリングしやすい統一化されたデータ形式の観点から、個人がそれぞれとりためたデータは活用にあたって問題が多い)
余談だが、「取引データのユーザーへの還元・提供」については、銀行はインターネットバンキングで既に構築しており、この観点では進んでいる、ということができるかもしれない。
■情報活用者(データの要件)
一方で、データを活用する側はどうだろうか。
データを活用する事業者(上図のD・E・F)にとっては、それがどんなデータか、がポイントとなる。
まず何よりも、目的に合致したデータかどうか、が問題となる。いくつかの観点が想定されるが、例えば、データの項目が十分かどうか。
商品開発で20代女性をターゲットにするのであれば、そのターゲットの趣味嗜好を分析できることが要件なので、20代女性のみに絞ったデータ、または性別年齢の属性が付与されたデータが必要、ということになる。
One to Oneのマーケティングアクションに使うのであれば、氏名のほか、電子メールアドレスや住所が必須であろう。
更に、マーケティングアクションに先立って、個々人の趣味嗜好を分析したい、というニーズは高いと思われるが、複数の情報提供事業者からデータを受領する場合には、「どの個人のデータなのか」という名寄せが前提となる。しかしながら、複数の情報提供事業者それぞれのデータにおいて名寄せが可能なデータ項目(氏名・生年月日・住所など)が揃っているかどうか、は心もとない。
電車から降りて改札を通ったところで、その街に関する情報を提供したい、というような場合には、タイムリーさも欠かせない。情報銀行を経由して1日後にデータを受け取るのでは役に立たないのである。
AIのマシンラーニングに使いたい、という場合には、結果の有意性を確保するためにはかなりのデータ量が必要となる。また、質の悪いデータではAIが間違ったロジックを構築してしまう恐れがあるので、量だけでなく質の担保も欠かせない。
追加的に学習してレベルアップしていくようなAIプロジェクトの場合には、良質のデータを継続的に受け取れる、ということも大切なポイントとなろう。
次に、というか、そもそもの前提だが、データの真正性を確保することが必要であろう。実在する人物に関するデータか、本当にその個人に関するデータなのか、その内容は正しいのか。
仮に、情報提供者にデータ提供の対価として報酬を支払う、となると、その報酬狙いのフェイクデータのリスクが出てこよう。完全に嘘のデータでなく、実在する人物のデータではあるものの、その中身の一部が水増しされている、というようなケースも考えられる。
先ほど、「個人が自分で記録するデータ」について触れたが、名の通った事業者からのデータ提供でなく、個人からのデータ提供では、量も確保しにくいうえに、(悪意でなかったとしても)間違いなく漏れなく記録されているのかどうか、入力ミスはないのか、など色々と課題がありそうだ。
最後にコストである。
情報活用者の狙いは、データを集計・分析・活用して収益をあげる、あるいは社会的な便益を得る、ということであるが、その収益水準や便益の内容に見合った値段で必要なデータを入手する必要がある。
情報銀行をワークさせるには
■情報・データの特性
よく言われるように「お金」には色がない。コツコツためても、一攫千金でかせいでも、100万円は100万円。そして、その100万円は、住宅購入にも、工場建築にも、競馬にも使える。
一方、ここで活用したい「情報・データ」には色がある。データは内容・形式が様々であり、それぞれの使える範囲・目的は決まってしまう。データハンドリングに伴うリスクも、値段も様々である。
内容の分類としては、一例であるが、属性データ(アンケート調査でFaceと言われる。性別・年齢・国籍など)、取引データ(通販などの購入、航空券の購入、銀行の入出金、検索ページの利用履歴など)、その他のデータ(食べ物飲み物など趣味嗜好、SNSへの投稿など)があげられる。
また、「データの存在状況」の観点では、既に存在するデータ、今後の取引で自動的に取り貯められるデータ、一日の歩数などセンサーなどを使ってわざわざ蓄積するデータ、趣味嗜好など頭の中にあることを外部に記録しないと出てこないデータなどの分類も考えられる。
それぞれ、蓄積しやすさ(量)、質の確保のしやすさ、蓄積するコスト、機微性・リスクが異なるので、データの活用にあたっては、こうした特徴を踏まえることが必要となる。
■情報をもっと活用するために
どんな商品・サービスでも、最終的なユーザーが便益・効能を享受して始めて付加価値が実現するように、「情報活用事業スキーム」においても、結局のところは情報活用者がデータを活用してどのような収益・便益・効能を生み出せるのか、がスキーム全体の成功の鍵となる。なお、ここでいう便益・効能には、収益事業のみならず社会的なベネフィットも含まれる。
したがって、本件のような「データの活用」にあたっては、情報活用者のニーズ、もっとシャープにいうと情報活用者が手掛ける「個々のデータ活用案件・ビジネス」におけるデータへのニーズが鍵であり、このニーズを出発点として、それを満たすことを目指してスキームを構築すべきである。
誰かの課題を解決して始めて付加価値が生まれる。データの値段も、実現される収益・便益・効能の水準に応じたプライシングができるような仕組みにするのである。
最もプリミティブな形としては、データ元となる情報提供者と、それを付加価値につなげる情報活用者との間で直接取引すればよい。
このような2者間取引では済まずに、データ元が複数になったり、個人の承諾が求められたり、専門的なプライシングが必要となったりと、取引にかかる多様な機能が必要となってきたら「仲介組織」を組成して、全体がうまく流れるように運営していくことになる。
最初に「一つの」案件・ビジネスを契機に組成した「仲介組織」が、いくつかの案件・ビジネスを手掛けていくなかでノウハウも蓄積され特徴ができてくる。
そうして、得意とするデータ種類・領域、親しく取引する情報提供者や情報活用者などが異なる、多様な特徴ある「仲介組織」が生まれてくる。例えば、健康データ専門仲介組織や、交通情報に強い組織、高齢者の趣味嗜好に強い仲介組織などである。そうした「仲介組織」の一つのカタチとして「情報銀行」が存在することになるかもしれない。
「仲介組織」としては、銀行のように情報をストックしておいて必要なときに情報活用者に提供するタイプ(どの情報活用者にいくらで提供するか、完全に委託されているタイプと、都度指図を受けるタイプが考えられる)、マーケットプレイスのように活用者ニーズと提供者の保有データをマッチングするタイプ(そこに個人の承諾機能を付与)に大きく分けられるであろうが、これも得意とする領域、ビジネスの特性に合わせてタイプを選択すればよい。
なお、「技術と応用」において、応用側のニーズから出発するだけでなく、「こういう技術がある」と知って初めて応用のアイディアを思いつく、という面もあるように、「データと活用」でも「こういうデータがある」と知って初めて活用のアイディアが出てくることもあることを踏まえて、情報活用者に「こういうデータがある」と伝えることも「仲介組織」の重要な機能となるであろう。
残る問題点
このように、情報活用者のニーズから出発して、案件・プロジェクトを積み上げることで継続的な仲介組織が運営されていくことが想定できるが、やはりデータ提供の段階での問題点が気になる。
すなわち、情報提供者は、そのデータの入手・蓄積・記録にコストをかけており、それを外部提供するには追加的なコストもかかる。更には、データを囲い込むことをあきらめて提供してもらわなくてはならない。そのインセンティブは何か。
この点に鑑みると、情報銀行あるいは仲介組織が「情報を運用して得た収益」の配分は、個人というよりは、情報提供者となる事業者に厚くする必要があるのではないか、そうでないとこのスキームは成り立たない場合が多いのではないか。
(したがって、冒頭の図のようなスキームでなく、すなわち「色んな情報を集めた銀行」のような存在ではなく、個人から個別個別のデータを集めてそれを販売していく、というような「単品型の情報仲介者」としての情報銀行が中心となっていく)
「情報は21世紀の石油」と言われるように情報に価値があるのであれば、油田に対価を払うように、情報元に対価を払わざるを得ないのではないだろうか。そういう意味では、GAFAなど大規模事業者から個人に、情報コントロールを取り戻すというのは容易ではないのかもしれない。
関連note:情報銀行はデータコントロールを個人の手に取り戻せるのか?
最後までお読みいただきありがとうございました。
(「スキ」や「フォロー」を頂けると、励みになりますので、よろしければ是非お願いいたします)
この記事が気に入ったらサポートをしてみませんか?