
Dreamtalk on Google Colabでつくよみちゃんをリップシンク付きで喋らせてみた

表情豊かに顔画像をリップシンクできるDreamtalkをGoogle Colabで試してみました。今回はつくよみちゃんの音声と画像で試しています。
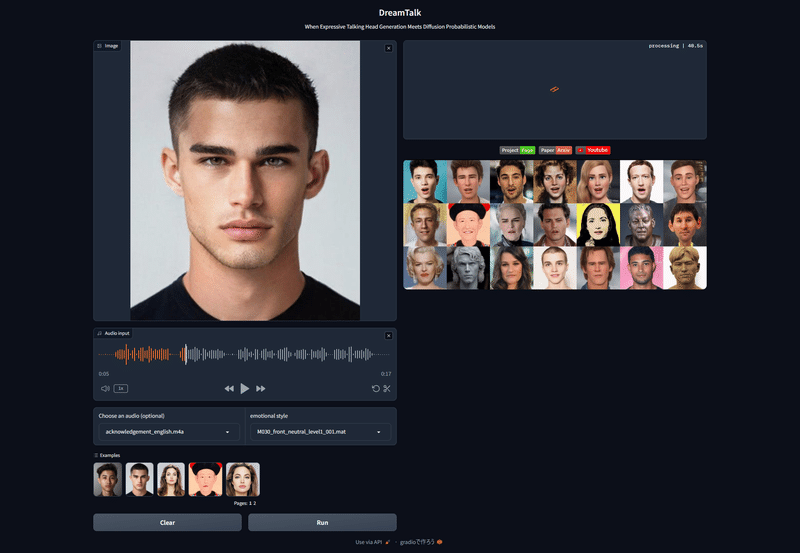
Exampleを試してみる
下記のdremtalk-colabのgithubのリンクからdreamtalk_gradio_colabのOpen in ColabをクリックしてColabを開きます。

Colabを開いたら早速実行をしてみましょう。しばらくするとgradioのリンクが発行されるのでクリックして開きます。リンクはRunning on public URL: の箇所になります。

開いたらExamplesにある適当な画像をクリックしてRunを実行してみましょう!リップシンクしている動画が生成されるはずです!
つくよみちゃんの音声で生成してみる
次に、つくよみちゃんの音声を追加して、つくよみちゃんの画像をリップシンクさせる動画を生成してみます。
先ほどのColabのページを開いて、左にあるフォルダアイコンからフォルダを表示してdreamtlak/data/audioのフォルダに下記のtukuyomichan01.wavという音声ファイルを追加します。

こちらの音声はつくよみちゃんの音声コーパスからモデルを作り、音声合成したもので下記の記事で作り方を紹介しているので気になった方はチェックしてみてください!
音声ファイルを追加したらコードを修正して、gradioのドロップダウンに追加した音声ファイル名を選択できるようにします。
audio_list = gr.Dropdown(
label="Choose an audio (optional)",
choices=[
"German1.wav", "German2.wav", "German3.wav", "German4.wav",
"acknowledgement_chinese.m4a", "acknowledgement_english.m4a",
"chinese1_haierlizhi.wav", "chinese2_guanyu.wav",
"french1.wav", "french2.wav", "french3.wav",
"italian1.wav", "italian2.wav", "italian3.wav",
"japan1.wav", "japan2.wav", "japan3.wav","tukuyomichan01.wav", # ここに追加
"korean1.wav", "korean2.wav", "korean3.wav",
"noisy_audio_cafeter_snr_0.wav", "noisy_audio_meeting_snr_0.wav", "noisy_audio_meeting_snr_10.wav", "noisy_audio_meeting_snr_20.wav", "noisy_audio_narrative.wav", "noisy_audio_office_snr_0.wav", "out_of_domain_narrative.wav",
"spanish1.wav", "spanish2.wav", "spanish3.wav"
],
value = "acknowledgement_english.m4a"
)コードの修正が終わったら、再び実行してgradioのページを開きます。開いたら下記のつくよみちゃんの画像をアップロードして、Choose an audioでtukuyomichan01.wavを選択してRunを実行してみましょう!

つくよみちゃん公式イラストだとエラーになり実行できない

上手くいけば下記のような動画が生成されるはずです!
DreamTalkでフェイシャルモーション付きでつくよみちゃんを喋らせてみた
— よしかい (@yoshikai_man) January 8, 2024
DreamTalkにアニメ顔の画像を渡すとエラーになってしまうので、DALL-Eで実写のつくよみちゃんの画像を生成してから、Style-Bert-VITS2で生成した合成音声と合わせてモーションを生成してます#つくよみちゃん pic.twitter.com/b4TSdXALYe
この記事が気に入ったらサポートをしてみませんか?