【Aidemy X Bio】機械学習はがん細胞を見分けられるか?:遺伝子解析データをもとに教師あり学習(分類)を行ってみる!

これまで乳がん細胞と正常細胞の遺伝子発現データをつかって、Aidemyの機械学習のコードを利用しながらいくつかプラットフォームをつくってきた!
詳しくは
【Aidemy X Bio】Aidemyのコースを応用して、遺伝子解析データ用の教師なし学習プラットフォームを作ってみた
をみてください。
今回は教師あり学習のうち、分類ができるかどうか試してみた!
使うデーターは乳がん細胞と正常がん細胞10個ずつのあらかじめ正規化した遺伝子発現データです(ダウンロードはこちらから)。
%matplotlib inline
from sklearn.cluster import AffinityPropagation, KMeans, DBSCAN, SpectralClustering
from sklearn.manifold import MDS, TSNE, Isomap
from sklearn.metrics import silhouette_score
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from scipy.linalg import logm, expmまずは大まかなライブラリー読み込み!
df_wine = pd.read_csv("TNBC10vNormal10_cpm_2.csv", sep=",",header=0, index_col=0)
df_wine_2 = df_wine.T
df_wine_2 = pd.DataFrame(df_wine_2)
X,y = df_wine_2.iloc[:, :].values, np.array([1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0,0])データをオブジェクトに読み込んで
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
import matplotlib
mds = MDS()
mds_coords = mds.fit_transform(X)
X1 = mds_coords
train_X1, test_X1, train_y, test_y = train_test_split(X1, y, random_state=42)
MDSにて次元を下げ、それをX1によみこんで、学習データとテストデータにわける!
# モデルの構築
model = LogisticRegression()
# train_Xとtrain_yを使ってモデルに学習させる
model.fit(train_X1, train_y)
# test_Xに対するモデルの分類予測結果
pred_y = model.predict(test_X1)
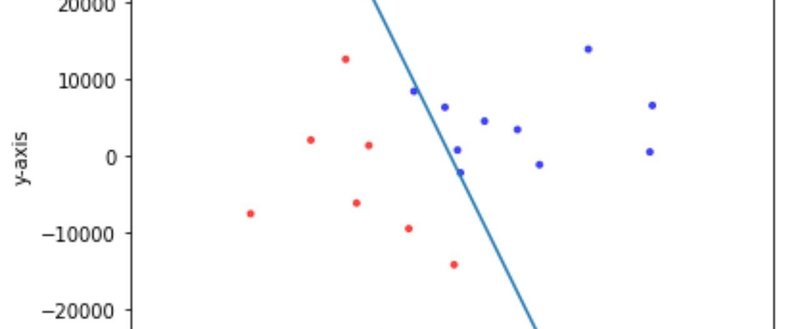
# 生成したデータをプロット
plt.scatter(mds_coords[:,0], mds_coords[:,1], c=y, marker=".",
cmap=matplotlib.cm.get_cmap(name="bwr"), alpha=0.7)
# 学習して導出した識別境界線をプロット
Xi = np.linspace(-60000, 60000)
Y = -model.coef_[0][0] / model.coef_[0][1] * \
Xi - model.intercept_ / model.coef_[0][1]
plt.plot(Xi, Y)
# グラフのスケールを調整
plt.xlim(min(mds_coords[:,0]) - 1000, max(mds_coords[:,0]) + 1000)
plt.ylim(min(mds_coords[:,0]) - 1000, max(mds_coords[:,0]) + 1000)
plt.axes().set_aspect("equal", "datalim")
# グラフにタイトルを設定する
plt.title("classification data using LogisticRegression")
# x軸、y軸それぞれに名前を設定する
plt.xlabel("x-axis")
plt.ylabel("y-axis")
plt.show()予測させ、予測したデータをもとに境界線をプロットしたデータに表示!

同様にして、Linear SVCでも予測

試しに学習に利用する遺伝子の数をもともとの14000強の遺伝子から、500まで減らしておこなってみた。


やはり二つの集団の差が別れにくいので、分類もいまいちですね!
この記事が気に入ったらサポートをしてみませんか?