【Aidemynote】Pythonでこの猛暑がどれくらいヤバいのかデータ分析してみた

今年の夏は猛暑そして熱中症で話題が持ちきりですね。
そんな中、
Phythonでこの猛暑がどれくらいヤバいのかデータ分析してみた
っていうタイトルでブログかくと、PV稼げるチャンス!!!
というtweetをみて試してみたくなりました!
適当に気温のデータとるのがたいへんだなとおもったのですが、なんとググってみると、
気温データは気象庁のサイトから手軽にデータのCSVファイルがダウンロード可能!!!
そして東京に限って言えば、1878年くらいからデータがそろっているんです。ペリーが黒船にのってやってきたのが、1853年ですから、その約25年後からデータが残っているってものすごいことです!
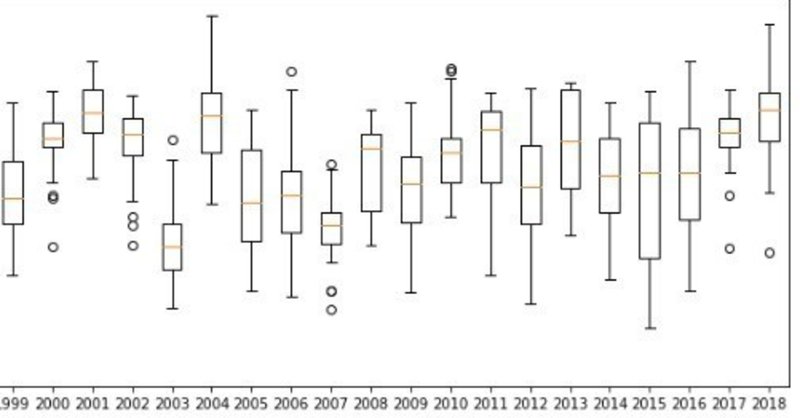
まずは今年のデータと比較するために1878年から2018年までの7月1日から23日までのデータを落として解析してみました!
まず全体をみてみると、
%matplotlib inline
from sklearn.cluster import AffinityPropagation, KMeans, DBSCAN, SpectralClustering
from sklearn.manifold import MDS, TSNE, Isomap
from sklearn.metrics import silhouette_score
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from scipy.linalg import logm, expm
df_wine = pd.read_csv('temp_TOKYO_7.csv', sep=",", header=0,index_col=0)
df_wine
df_wine = df_wine.T
df_wine
plt.figure(figsize=(8, 5))
plt.boxplot(df_wine,labels=list(df_wine.index))
気温の増加傾向はあるのですが、はっきりしません。
それで過去50年の気温データに注目してみました
plt.figure(figsize=(25,5))
labels=list(df_wine.index.values[-50:])
fs = 2
plt.boxplot(df_wine[-50:],labels=labels)
plt.show()
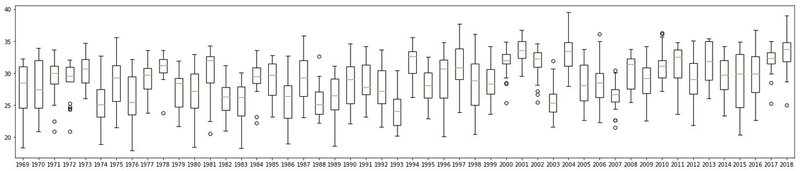
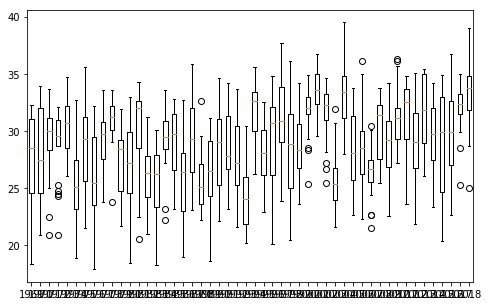
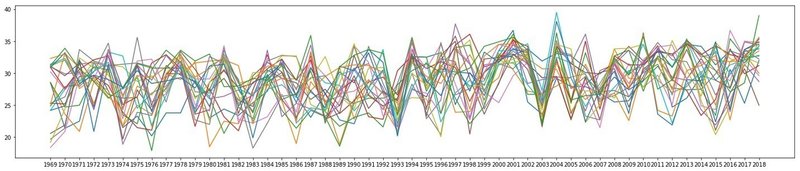
そうすると、2000年代に入って増加傾向があることがわかります。
さて問題の今年
2018年ですが。。。
やはりトップクラスの暑さですね!
今までにこんなことがなかったかというわけではなく、同様の暑さの年が
2001、2004、2010年
にあったということもわかります。
なかでも2004年は今年と同レベル
喉元すぎれば暑さを忘れるではないですが、2004年東京にいたはずなのに全く猛暑のことを覚えていないんですね。
Wikepediaによると
6月は記録的に暖かく、全国的に梅雨明けは早かった。7月は各地で1994年や2001年に匹敵するような猛暑となった。7月20日には東京都心で39.5℃、翌21日には山梨県甲府市で40.4℃など観測史上1位の最高気温を記録した。1994年や2010年とは異なり、8月は平年並みか、やや涼しい地域が多かった。しかし、9月に入って再び高温に転じた。梅雨期も高温で経過したため真夏日の日数が非常に多く熊本市が105日、京都市と大阪市で94日、東京都心で70日となり観測記録を更新した。(中略)この猛暑の要因は太平洋高気圧が例年より北に偏って張り出したため、日本列島が高気圧の圏内になったものとされている。その他にも都市部ではヒートアイランド現象も要因のひとつに挙げられる。この年は、台風の上陸数が10個に達し、観測史上最も多いことも特徴として挙げられる。
という記述があるので、今年と似ていたりするのかなと思いますね。
ちなみ2004年くらいに小学生だった今の20−24くらいの人に、オレたちの頃はクーラーなしでやっていたっていわれても文句いけないかも笑 というのは冗談で、熱中症は怖いのでクーラー使用と水分補給はしっかりとしないといけませんね。
ちなみに東京の7月の平均気温、平均湿度、平均風速で機械学習もさせてみて、MDSとISOでプロットさせてみたのですが、

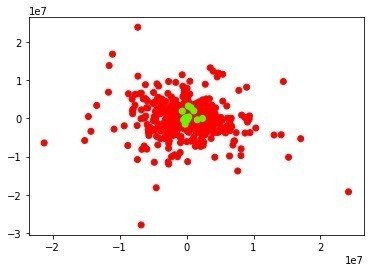
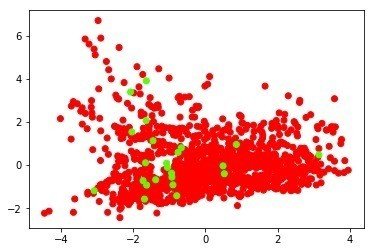
いまひとつうまく分かれてくれませんでした(緑が2018年、その他の年が赤)。なかなか今年が特別な年というのは難しいですね。。
ここからはRでやってしまったので恐縮ですが、
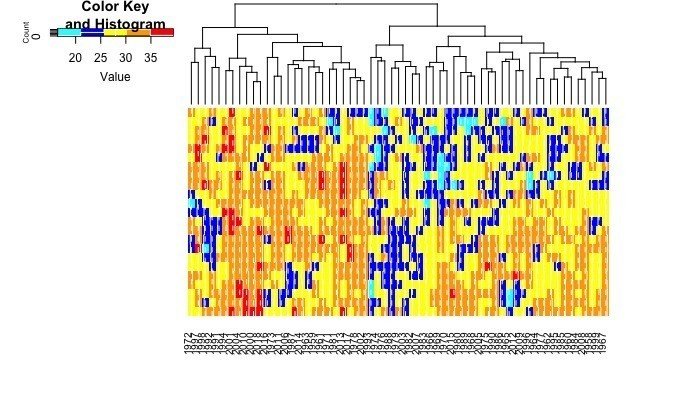
heatmap書かせて、Hierarchical cluseteringすると、90年代以降の年が暑い7月のグループに含まれることがおおく、なかでも最も暑いと考えられるグループが、2001,2004,2010,2000,2018年であるようですね。
やっぱり今年は暑いんだろうな。。やれやれ。
ということで昨日ちょこちょこやっていました。
気象庁から気候データのCSVファイルが手軽に落とせるので、Aidemyで学んだことの復習には気候データを使ってみるのも面白いです。近々python使いまくると思うので、今回はpandasとmatplotlibのちょうどいい復習になりました!
この記事が気に入ったらサポートをしてみませんか?