
はじめて売上予測をしてみた e-commerce

1.はじめに
Python面白そうだな〜と軽い気持ちで
本を買ったけど、さっぱり分からず・・・
Aidemyで6ヵ月勉強させていただきました!
普段Excelでデータ集計し資料を作成するお仕事をしてまして、機械学習を学び業務の効率化や新しい視点で分析できたらと考えていたので
KaggleのE-commerceDATAで売上予測をすることにしました。
2.使用環境
Windows10,google colaboratory、Python3.8
3.データのダウンロードと読込
kaggleからDATAをダウンロードしてGoogleドライブに保存します。
【kaggle】 https://www.kaggle.com/datasets/carrie1/ecommerce-data
Google ドライブにファイルをアップロードする為に
google colaboratoryを開きdriveのマウントを取ります。
読込んだデータの内容を確認する為、先頭5行を表示させます。
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
from pandas import datetime
import numpy as np
#データの読込
data=pd.read_csv('/content/drive/MyDrive/Colab Notebooks/data.csv',encoding="ISO-8859-1")
data.head()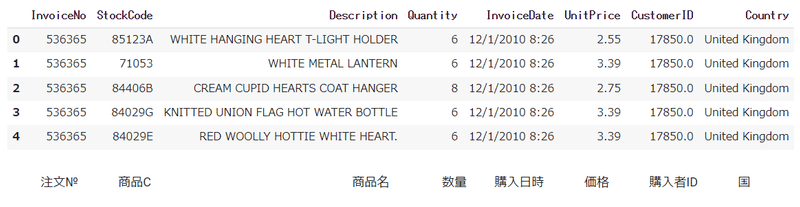
4.前処理開始
ダウンロードしたデータには欠損、ノイズ、エラー値など含まれる可能性が大いにあります。そのまま機械学習に使用すると学習の精度が下がったり、エラーが出てしまうなどの問題が生じる為、前処理が必要となります。
各columnのデータ型の確認
# 各columnのデータ型を表示
print(f'{data.dtypes} \n')
InvoiceDateがobjectになっているのでdatetime型に変換する
#データ型変換 data["InvoiceDate"] = pd.to_datetime(data["InvoiceDate"])
#変換されたか確認
print(data["InvoiceDate"].dtypes)
print(type(data["InvoiceDate"][0]))
注文の間隔を確認する為に日時と経過時間を見てみます。
data["dif_min"] = data["InvoiceDate"].diff().dt.total_seconds() / 60
data["dif_min"] = data["dif_min"].fillna(0)
print(data["dif_min"].head(10))
data["cum_min"] = data["dif_min"].cumsum()
print(data[["InvoiceDate", "cum_min"]].head())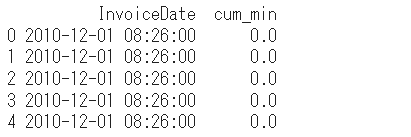
データ全体を把握する為に統計量を確認します。
#統計量確認
data.describe()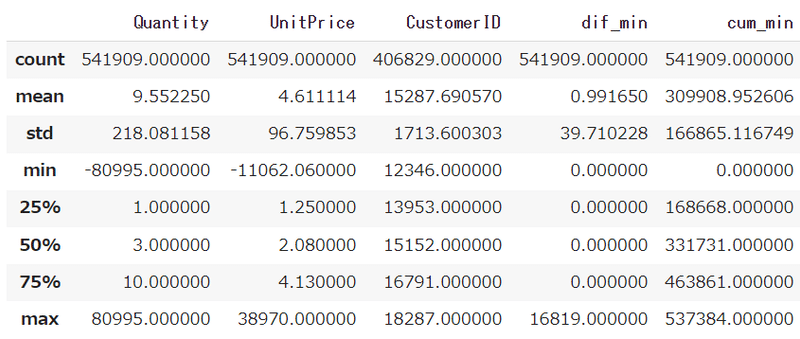
どの列に欠損値が含まれているのか確認します。
#欠損値の確認
data.isnull().any()
続いて、欠損数も確認します。
#欠損件数算出
data.isnull().sum()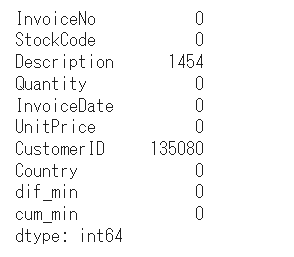
相関関係を目視する為にヒートマップでも確認してみます。
import seaborn
#ヒートマップ
seaborn.heatmap(data.isnull())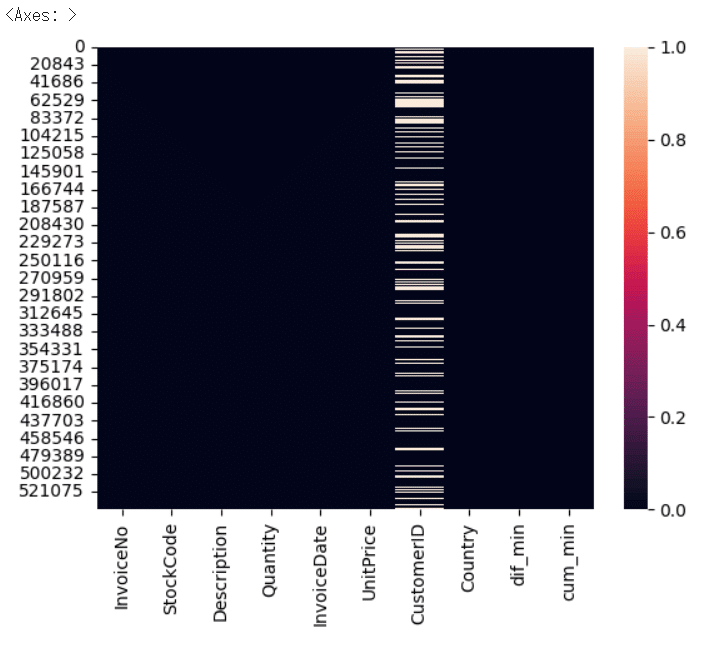
日にち毎に収益を確認したいので、
Revenueの列を追加します。
時間表示は今回は使用しないので非表示にします。
Descriptionの欠損している行を抽出します。
#Revenueを追加
data["Revenue"] = data.Quantity * data.UnitPrice
# InvoiceDateを日付のみの表示に変換
data["InvoiceDate"] = pd.to_datetime(data["InvoiceDate"]).dt.strftime("%Y-%m-%d")
#Description確認
data[data.Description.isnull()].head()
#CustomerIDが欠損しているRevenue確認
data.loc[data.CustomerID.isnull(), ['Revenue']].describe()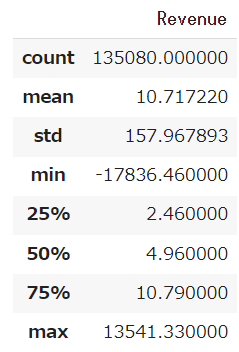
CustomerIDとDescriptionのデータの無い行を削除し、欠損値が無いかを再度確認します。
data = data.loc[(data.CustomerID.isnull()==False) & (data.Description.isnull()==False)].copy()
data.isnull().sum().sum()国別の収益を比較してみます。(上位10位まで)
#Countryの収益を比較
data = data.groupby('Country', as_index=False).sum()
data_top10 = data.nlargest(10, 'Revenue')
data_top10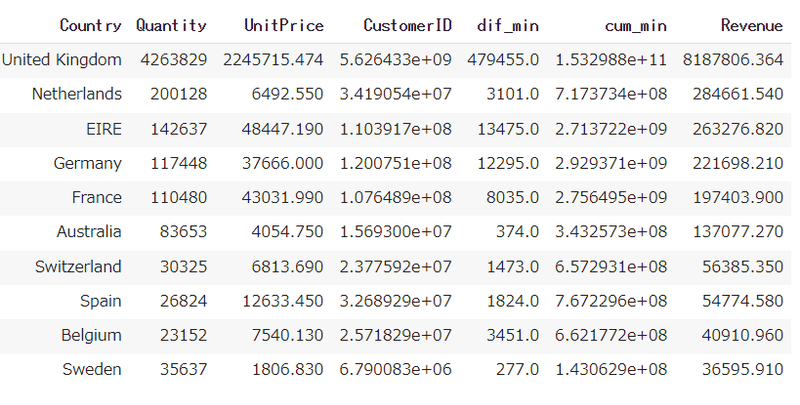
日にち単位で収益を確認します。
data= data.groupby('InvoiceDate',as_index=False).sum()
data.head()
折れ線グラフで収益の推移を抽出し
目視で確認できるようにします。
xlabel = data['InvoiceDate'].to_list()
ylabel = data['Revenue'].to_list()
plt.figure(figsize=(20, 8))
plt.plot(xlabel,ylabel)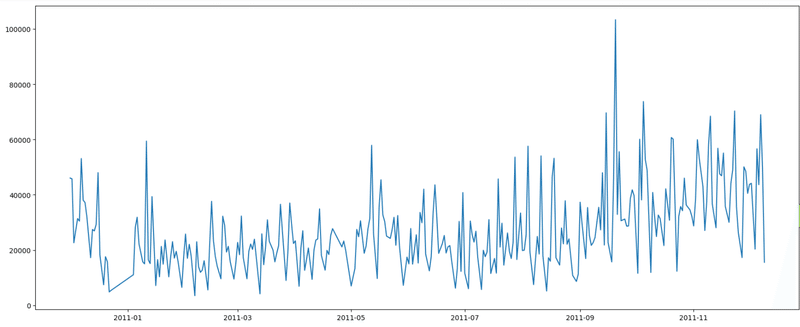
大体、35日から40日周期で収益が動いている印象を受けたので40日周期で自己相関グラフを作成してみます。
import matplotlib.pyplot as plt
import statsmodels.api as sm
#自己相関をグラフで確認する fig = plt.figure(figsize=(12, 8))
ax1 = fig.add_subplot(211)
sm.graphics.tsa.plot_acf(data['Revenue'], lags=40, ax=ax1)
#編自己相関
ax2 = fig.add_subplot(212)
sm.graphics.tsa.plot_pacf(data['Revenue'], lags=40, ax=ax2, method='ywmle')
plt.show()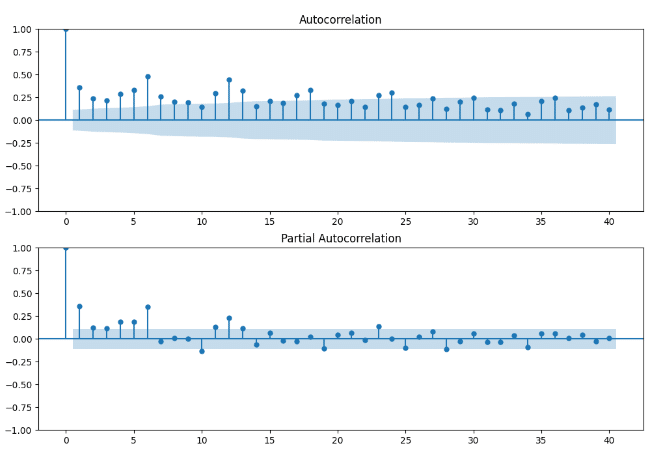
5.テクニカル分析を用いて収益の予測をする
目的変数を追加する
#InvoiceDateをインデックスにする data = data.set_index(["InvoiceDate"])
#カラム情報を1行上にずらしたデータフレームを作成
data_shift = data.shift(-1)
data_shift
data_shiftを用いて、翌日の収益と本日の収益を引き算し、その結果を'delta_Revenue'というカラムを追加しdataに入力
#翌日の収益と本日の収益の差分を追加
data['delta_Revenue'] = data_shift['Revenue'] - data['Revenue']
data
目的変数UPを追加する。
#目的変数Upを追加する (翌日の終値が上がる場合1、それ以外は0とする)、'delta_Close'カラムの削除
data['Up'] = 0
data['Up'][data['delta_Revenue'] > 0] = 1
data = data.drop('delta_Revenue', axis=1)
data
特徴量を追加します。
(今日のRevenue - 前日のRevenue) ÷ 前日のRevenue
# Revenueの前日比の追加
data_shift = data.shift(1)
data['Revenue_ratio'] = (data['Revenue'] - data_shift['Revenue']) / data_shift['Revenue']
data!pip install tensorflow学習データと検証データに分けます。
# 学習データを2010-12-01〜2011-09-30の期間としdata_trainに入力する
data_train = data['2010-12-01' : '2011-09-30']
data_train
# 検証データを2011-10-01以降としてとしてdf_valに入力する
data_val = data['2011-10-01' : ]
data_val.head()
学習データを説明変数と目的変数に分ける。
# 学習データを説明変数(X_train)と目的変数(y_train)に分ける
X_train = data_train[['Quantity', 'UnitPrice', 'CustomerID', 'dif_min', 'cum_min', 'Revenue']]
y_train = data_train['Up']
# 学習データの説明変数と目的変数を確認
print(X_train)
print(y_train)
検証データを説明変数と目的変数に分ける
# 検証データを説明変数(X_val)と目的変数(y_val)に分ける
X_val = data_val[['Quantity', 'UnitPrice', 'CustomerID', 'dif_min', 'cum_min', 'Revenue']]
y_val = data_val['Up']
# 検証データの説明変数と目的変数を確認
print(X_val)
print(y_val)
6.グラフの作成
# 学習データと検証データのRevenueの折れ線グラフ作成
X_train['Revenue'].plot(kind='line')
X_val['Revenue'].plot(kind='line')
# グラフの凡例を設定
plt.legend(['X_train', 'X_val'])
# グラフの表示
plt.show()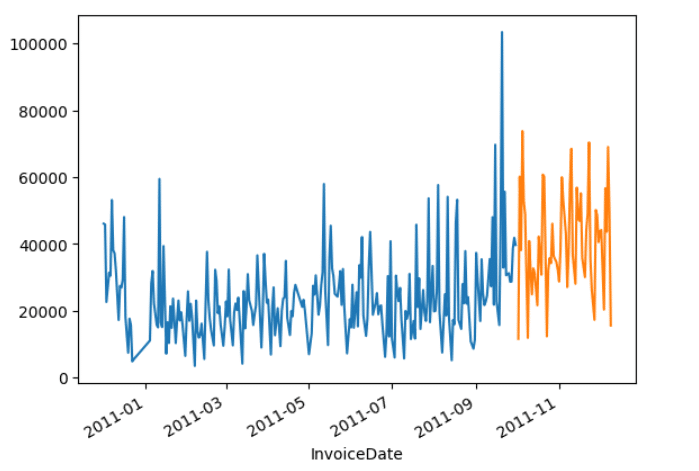
株価予測を見習って収益の予測をしてみました。
時期によって、バラつきがかなりあるので
一番購入者の多いイギリスの購入者に絞り、国特有のビックセールやブラックフライデーなどのデータと照らし合わせるともっと面白い結果が出せるかもしれないなと思いました。
今度は株価予測もしてみようと思います。
この記事が気に入ったらサポートをしてみませんか?