
音声インターフェース、話者がひとりって誰が決めた? - 音声UX攻略記 -

どうも、VoiceApp Lab(ボイスアップラボ) のコバヤシです。みなさん、AlexaやGoogle Home、活用していますか?ぼくはといえば、アレクサが突然笑い出すと聞き、今か今かと待っているのですが、どうやらウチのEchoはそれほど陽気やヤツではないようです。ざんねん。
会話していてどっちがラク?
例えば、あなたが誰かと話をしているとして、どっちがラクですか?

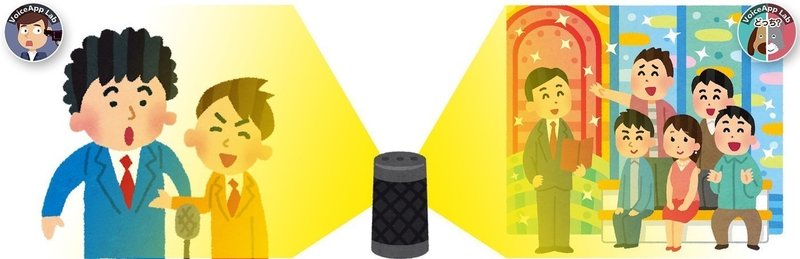
Aは、二人で会話しています。Bは三人です。同じような関係の友人や同僚と話しているとしましょう。
個人的な感覚かもしれませんが、どちらかといえば、Bのシチュエーションの方がラクな気がしませんか?Aのようにサシで話し続けるのって、ちょっとしんどくないですか?
恋人や親友ならAでも楽しいでしょうが、そうでないのであれば、Bの方が精神的な負担が低いと思います。Aではあなたは常に会話の当事者です。キャッチボールは二人で続けるしかありません。でもBなら、二人の会話を聞いて「うんうん、そだねー」とカーリング娘風に相槌をうてばよい時間帯がきっとあるはずです。
音声アシスタントは常にサシでの勝負になる
AlexaやGoogle Homeなど、音声アシスタントのUIってほぼAのイメージです。ユーザーはいつでもアシスタントとタイマン状態。ワタシとアナタ、それ以外の登場人物はいません。でも「音声による会話表現」と広くとらえるならば、話者を二人に限定する必要はないですし、Bのようなシチュエーションも無視できないと思うんです。
ラジオを思い浮かべてみてください。パーソナリティが1人の番組があるとします。このとき、パーソナリティーとリスナーしかいないからAだと思いますか?
でも実際に人気があるラジオ番組って、パーソナリティは現場のスタッフと自然に会話したりしてませんか?スタッフにちょっかい出したり、または出されたり、そのやりとりにこそ、そのパーソナリティの人間性が感じられて嬉しくなったりしませんか?それはまさにBのシチュエーションです。
リスナーは、一生懸命自分に話しかけられているのも嬉しいけど、パーソナリティとスタッフとの会話を聞くのもまた楽しいはずです。むしろそちらの方が、スタジオの空気感が伝わって、場を共有できる感覚が生まれるのではないでしょうか。
現在音声アシスタントのUXで語られることの多くは、「ユーザーがスピーカーに話かけたら、その意図を正確に把握し、正しく処理することがよろしい」というものです。ここにはユーザーとアシスタントしか登場しません。
ですがそれではどうしてもやりとりが窮屈になる、という印象をぼくは持っていました。なのでぼくが作ったいくつかのアプリでは、Bを採用しています。つまり、登場人物を複数だすことで、ユーザーの責任範囲をせばめ、ストーリーに気軽に入り込んでもらうように工夫しています。
話者が複数登場するスピーカーアプリの可能性
まず簡単なロシアンルーレットゲームを作ろうと思いました。でも普通に作ってしまうと、
アシスタント「番号を選んでください」
ユーザー「3番」
アシスタント「バーン、アタリです!」
ユーザー「・・・」
というやりとりになります。なんだかシュールすぎると思いませんか?二人しかいないとやりとりが端的すぎて、自然な面白みがなかなか出ません。そこで登場人物を増やし、アシスタントと会話させることで場を作ることにしました。それが「ヨシオくん 危機一髪!」というゲームです。起動すると、ユーザーそっちのけでアシスタントとヨシオくんの会話が始まります。
アシスタント「今からヨシオくんにはロシアンルーレットに挑戦してもらいます」
ヨシオ「そんなん聞いてへんで。死んでまうやろ!…お前がやれや!」
アシスタント「少々お待ちください(バキッ、ボコッ)」
ヨシオ「あいたー、やらせていただきますっ!」
と、まるで漫才のように二人の会話は進みます。ユーザーは会話に耳をそばだてているうちに事件に巻き込まれます。そしていつの間にか「ヨシオくんの命を救うキーマン」となり、ゲームの世界に投入されることになるのです。
また、別の作品「どっちでショー」では、「カレーに入れるなら福神漬け?らっきょう?」というアンケート形式のコンテンツをTVのクイズ番組風に仕上げました。男性アナウンサーと番組アシスタント(まさにアシスタント)という2人を登場させることで、ユーザーを自然に解答者席に座らせる作戦にしたのです。
どちらのコンテンツも、ユーザーは受け身のままで負担なくルールを学び、世界観に没入していくことができます。この演出の効果かはわかりませんが、上記の2アプリはリリース後、トータルで4万回以上遊んでもらうことができました。
日本特有の感じ方が影響している?
スピーカーを1人のアシスタントと見立てサシで会話するよりも、複数人に会話をさせて責任を分散したほうが気が楽だ、という感覚は、もしかするととても日本人的な発想かもしれません。
アメリカの文化人類学者であるエドワード・T・ホールが提唱した概念で、「低コンテキスト」と「高コンテキスト」という概念があります。
高コンテキストなコミュニケーションでは、言葉そのものよりも身振り手振りや表情、その場の雰囲気の中に文脈があるため、言葉を多様しなくてもお互いに理解することができます。逆に低コンテキストなコミニュケーションでは、共有する文脈が少ないため、はっきりとした言葉で意味を伝達する必要があります。
アメリカをはじめ、民族の多様化が進んでいる英語圏の国々は、低コンテキスト文化と言われます。お互いの立場が違うからこそ、言いたいことは具体的にはっきり言わないと理解しえない、という前提のもとのコミニュケーションがあります。
とすればAlexaやGoogle Homeのあのスタイルが、アメリカで生まれたのはしっくりきます。低コンテキストを前提とすれば、人には必ず「やりたいこと」があり、それを実現するためにデバイスを活用するのだ、という発想になるのは当然だからです。
それに対して日本人は、高コンテキスト文化です。単一民族である我々は、お互いのバックグラウンドが共通しているという前提をもとにコミニュケーションを行います。そのため、相手が前提を理解できていれば良いのですが、そうでない相手には、何を言えばいいか、わからなくなったりします。
aiboやRobiなど、日本発のロボットがが愛らしい外見を持っているのは、ユーザーとの距離を縮めることを第一ミッションとしているからでしょう。デバイスが「アイツ」なのか「この子」なのか、それが決まらなければ、投げかける言葉が決まらないということがわかっているからです。
なので日本では、AlaxaやGoogle Homeのようなデバイスを前に言葉に窮してしまうユーザーは多いと思います。スマートスピーカーと、もっと文脈を温めながら、ゆるゆるっとコミニュケーションできる方法はないものかって思うんです。うん、ここまで書いて、それを再認識できました。
それっていったいどんなコンテンツ?
それっていったいどんなコンテンツなのでしょうか?正直まだわかりません。
スマホのアプリであれば、どの国でも同じUIで「ある程度は」同じような反応を取れたと思いますが、音声となると文化的な差がどんどん出てくる気がします。少なくとも、アメリカやドイツの低コンテキストのコンテンツがそのまま日本で流通するとは思えません。(リモコン的なものは別ですが)
ということは裏を返せば、
・高コンテキストの日本ならではの表現
が生まれてくる「伸びしろ」が山ほどあるとも言えます。それがワールドワイドに通用するかどうかはわかりませんが、日本人にとって心地よく、楽しい、まだ見ぬジャンルがありそうだと予感していて、それはそれでワクワクしております。
最後に高コンテキストな拙作を一つご紹介させてください。

「ボイスカンフー」といいまして、音声なのに格闘ゲームです。Google Assistantのディレクトリでは唯一「アクションゲーム」にカテゴライズされています。ちなみに話者は三人登場し、それぞれ役割分担しながらストーリを進めます。RPG要素や対戦要素もあったりします。Alexaでも遊べますので、興味ありましたらどうぞ!
それにしても音声UIは奥が深いです。ツールが言葉のみに限られているぶん、大きな発想の転換を求められますが、ユーザーにハマればこれほど面白いジャンルはなかろうと思います。
ユーザー最適化に走る前に、とりあえず多様な表現方法を見つけ、あがいていくことが、きっと今の音声インターフェースには求められているのではないかと思います。
そいではまた。どんどん。
この記事が気に入ったらサポートをしてみませんか?