#15 分類コードをインデックスにする

前回の投稿では、産業連関表をデータフレーム形式で読み込むことに挑戦したのですが、
本当は、分類コード(文字列)をインデックスにしたいんですよね。どうやればいいんだろう…
というところで、時間切れを迎えてしまっていました。
今回は、この続きから始めていきます。
列をインデックスにする
こちらのサイトを参考にしました。
列をインデックスにするための構文。dataframe.set_index(Column_name,inplace = True)
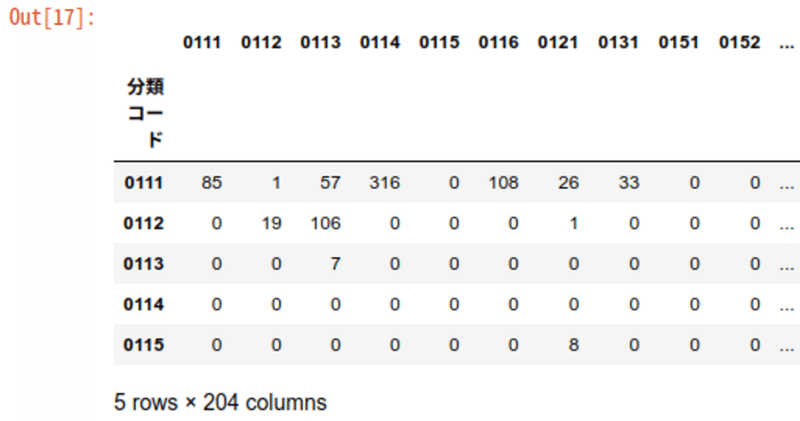
df_iotable.set_index('分類コード', inplace=True)
df_iotable.head()
う〜ん。
本当は、列名のそれぞれが分類コードなので、列名の一つ上の階層にも、「分類コード」という階層を追加したほうがいいのかな?とも考えています。
でも、そうすると、インデックス名と重複するしなあ。
行インデックスの一つ上の階層を「分類コード(行)」、列インデックスの一つ上の階層を「分類コード(列)」とする方がいいのかな?
いろいろ迷うところはありますが、ひとまずこのまま次に進んでいくことにします。
おっと。
その前に、df_price_per_tonの方も、列「分類コード」をインデックスに設定しておくことにします。
df_price_per_ton.set_index('分類コード', inplace=True)
df_price_per_ton.head()
続いては、物質フローの推計になります。
物質フロー変換の算出式
マガジン『トシヤの個人研究日誌』の記事#6〜#12で推計を行った、各産業の重量単価【初期値】をもとに、産業連関表に記載されている金額フローを物質フローに変換し、産業廃棄物発生量を推計していきます。
算出式は、以下のようになります。

Uxについては、記事#6で触れています。
Ux = Mx / Tx (2.1)
Ux : x産業の重量単価[円/t]
Mx : x産業の総生産額[円]
Tx : x産業の総生産量[t]
Wxの算出式を、Pythonの関数として定義することが必要かなと考えました。
今日はこの辺で。
サポート、本当にありがとうございます。サポートしていただいた金額は、知的サイドハッスルとして取り組んでいる、個人研究の費用に充てさせていただきますね♪