個人ローンサービス利用分析

このブログはAidemy Premiumのカリキュラムの一環で、受講修了条件を満たすために公開しています
1、はじめに
研究の目的や背景
業務上から特定のキャンペーンに対するユーザーの反応を予測する必要があるため、類似案件に取り組みたいと考え本件に取り組んだ。
ユーザーの反応と顧客属性の間にある関係を分析したうえで、予測モデルを作成することを目標としている。分析の概要
Kaggleより個人ローンに関するデータを取得した。
データには顧客の人口統計情報 (年齢、収入など)、顧客と銀行の関係 (住宅ローン、証券口座など)、個人ローンに対する顧客の反応が含まれている。
データ内容を分析の上、ロジスティック回帰モデル、決定木モデルを作成した。分析環境
Google Colaboratory
2、データ概要
使用したデータセットの説明
Kaggleに掲載されている「Personal Loan| Logistic Regression& Decision Tree」よりデータを取得した。各変数の定義と意味
ID:顧客ID
Age:年齢
Experience:勤続年数
Income:年収 ($000)
ZIP Code:郵便番号
Family:家族人数
CCAvg:クレジットカード月間平均支出額 ($000)
Education:教育レベル(1:学部生、2:卒業生、3:アドバンス/プロフェッショナル)
Mortgage:住宅ローン額($000)
Securities Account:証券口座有無
CD Account:定期預金口座有無
Online:インターネットバンキングサービス
CreditCard:他銀行クレジットカード有無
Personal Loan:個人ローン有無 ※目的変数
3、データ前処理
データ取り込み
ダウンロードしたデータをCSVファイル保存、Google Colaboratoryに読み込み。
読み込んだデータは訓練データとテストデータに分けるためフラグ付与する。
from google.colab import drive
import pandas as pd
from sklearn.model_selection import train_test_split
# Googleドライブをマウント
drive.mount('/content/drive')
# CSVファイルの読み込み
data = pd.read_csv('/content/drive/MyDrive/02_Aidemy/Bank_Personal_Loan_Modelling.csv')
train_data, test_data = train_test_split(data, test_size=0.2, random_state=42)
# 訓練データとテストデータを結合しall_dfを作成 (1.2.5)
all_df = pd.concat([train_data,test_data],axis=0).reset_index(drop=True)
# 訓練データとテストデータを判定するためのカラムを作成 (1.2.5)
all_df['Test_Flag'] = 0
all_df.loc[train_data.shape[0]: , 'Test_Flag'] = 1
all_df.head()
データ内容の確認
DataFrameの行数、列数、特徴量名、欠損値を確認する。
5,000行×15列のDataFrameで、各特徴量の中に欠損値は存在しないことがわかった。
#get the size of dataframe
print ("Rows : " , all_df.shape[0]) #get number of rows/observations
print ("Columns : " , all_df.shape[1]) #get number of columns
print ("#"*40,"\n","Features : \n\n", all_df.columns.tolist()) #get name of columns/features
print ("#"*40,"\nMissing values :\n\n", all_df.isnull().sum().sort_values(ascending=False))
統計量確認
DataFrameの統計量を確認する。
Experience:勤続年数の最小値がマイナス値になっているため調査が必要である。
# 数値データの統計量を表示
display(train_data.describe())
display(test_data.describe())
データ整理
「Family、Education、Personal Loan、Securities Account、CD Account、Online、CreditCard」はカテゴリカル変数のため、数値型からカテゴリ型に変換する。
# int64からカテゴリ型に変換
columns_to_convert = ['Family', 'Education', 'Personal Loan', 'Securities Account', 'CD Account', 'Online', 'CreditCard']
all_df[columns_to_convert] = all_df[columns_to_convert].astype('category')
print(all_df.dtypes)
Experienceがマイナス値をとる場合のAgeの統計量を調査した。
29歳〜23歳の間に値があり、52行存在することがわかった。
1%ほどの影響のため絶対値に変換して対応する。
#Experience がマイナス値の統計量を調査
all_df[all_df['Experience']<0]['Age'].describe()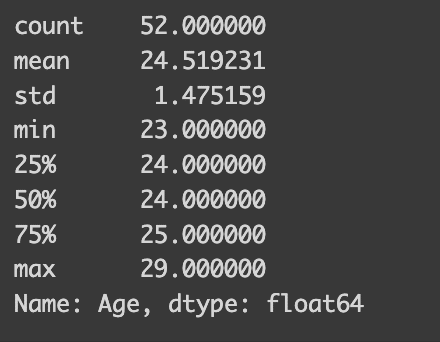
# 勤続年数のマイナス値を調整
all_df["Experience"] = abs(all_df["Experience"])4、データ分布調査
数値変数のヒストグラム作成
数値変数「Age、Experience、Income、CCAvg、Mortgage」のヒストグラムをそれぞれ作成してデータ分布を確認する。
import matplotlib.pyplot as plt
import seaborn as sns
# ヒストグラムをプロットする数値変数のリストを指定
numeric_columns = ['Age', 'Experience', 'Income', 'CCAvg', 'Mortgage']
# サブプロットの設定
plt.figure(figsize=(12, 8))
for i, column in enumerate(numeric_columns, 1):
plt.subplot(2, 3, i)
sns.histplot(all_df[column], bins=20, color='skyblue')
plt.title(f'{column}')
# 件数ラベルと構成比ラベルの追加
total = len(all_df[column])
for patch in plt.gca().patches:
count_label = int(patch.get_height())
percentage = count_label / total * 100
plt.text(patch.get_x() + patch.get_width() / 2, patch.get_height(),
f'{percentage:.1f}%', ha='center', va='baseline')
# 中央値と平均値の線を追加
median_value = all_df[column].median()
mean_value = all_df[column].mean()
plt.axvline(median_value, color='red', linestyle='dashed', linewidth=2, label='Median')
plt.axvline(mean_value, color='green', linestyle='dashed', linewidth=2, label='Mean')
# グラフに凡例を追加
plt.legend()
plt.tight_layout()
plt.show()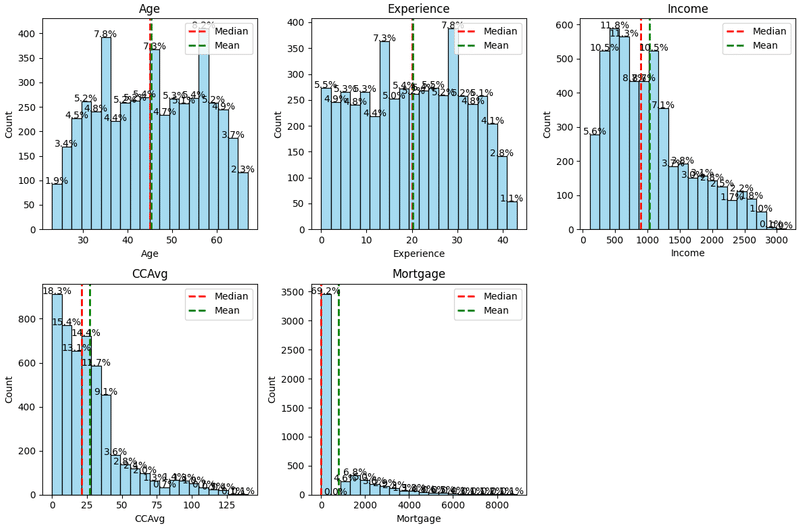
Age、Experienceは中央値と平均値は同じくらいの値になっている。
Income、CCAvg、Mortgageは低い値にデータが偏っていることを確認。
特にMortgageは「0」にデータが大きく偏っている。
カテゴリカル変数のヒストグラム作成
カテゴリカル変数「Family、Education、Personal Loan、Securities Account、CD Account、Online、CreditCard」のヒストグラムをそれぞれ作成してデータ分布を確認する。
import matplotlib.pyplot as plt
import seaborn as sns
# カテゴリカル変数のリストを指定
categorical_columns = ['Family', 'Education', 'Personal Loan', 'Securities Account', 'CD Account', 'Online', 'CreditCard']
# サブプロットの設定
plt.figure(figsize=(12, 8))
for i, column in enumerate(categorical_columns, 1):
plt.subplot(3, 3, i) # サブプロットの数を増やすか、適宜調整してください
sns.countplot(x=all_df[column], data=all_df, palette='pastel')
plt.title(f'{column}')
# 件数ラベルと構成比ラベルの追加
total = len(all_df[column])
for container in plt.gca().containers:
for patch in container.patches:
count_label = int(patch.get_height())
percentage = count_label / total * 100
plt.text(patch.get_x() + patch.get_width() / 2, patch.get_height(),
f'{percentage:.1f}%', ha='center', va='baseline')
plt.tight_layout()
plt.show()

数値変数をカテゴリカル変数に変換してヒストグラム作成
数値変数「Age、Experience、Income、CCAvg、Mortgage」をカテゴリカル変数に変換する。
そのうえでヒストグラムをそれぞれ作成してデータ分布を確認する。
# ビンの数
num_bins = 5
# 各数値変数のビンの範囲を計算
for column in ['Age', 'Experience', 'Income', 'CCAvg', 'Mortgage']:
# ビンの範囲を計算
bin_range = pd.cut(all_df[column], bins=num_bins, labels=False)
# ビンの範囲をカテゴリカル変数に変換
all_df[f'{column}bin'] = bin_range
# カテゴリカル変数のリストを指定
categorical_columns = ['Agebin' , 'Experiencebin', 'Incomebin', 'CCAvgbin', 'Mortgagebin']
# ビンの範囲をカテゴリ名として作成
bin_labels = []
for column in ['Age', 'Experience', 'Income', 'CCAvg', 'Mortgage']:
bin_min = all_df[column].min()
bin_max = all_df[column].max()
bin_width = (bin_max - bin_min) / num_bins
bin_ranges = [f'{int(bin_min + i * bin_width)}-{int(bin_min + (i+1) * bin_width)}' for i in range(num_bins)]
bin_labels.append(bin_ranges)
# サブプロットの設定
plt.figure(figsize=(12, 8))
for i, column in enumerate(categorical_columns, 1):
plt.subplot(3, 3, i) # サブプロットの数を増やすか、適宜調整してください
sns.countplot(x=all_df[column], data=all_df, palette='pastel', order=range(num_bins))
plt.title(f'{column}')
# 件数ラベルと構成比ラベルの追加
total = len(all_df[column])
for container in plt.gca().containers:
for patch in container.patches:
count_label = int(patch.get_height())
percentage = count_label / total * 100
plt.text(patch.get_x() + patch.get_width() / 2, patch.get_height(),
f'{percentage:.1f}%', ha='center', va='baseline')
# ビンの範囲をラベルとして追加
plt.xticks(ticks=range(num_bins), labels=bin_labels[i-1], rotation=45)
plt.tight_layout()
plt.show()
5、相関関係調査
数値変数の相関関係を調査
数値変数「Age、Experience、Income、CCAvg、Mortgage」同士の相関関係を求める。
#数値変数の相関関係を調査
sns.heatmap(
train_data[['Age','Experience','Income','CCAvg','Mortgage']].corr(),
vmax=1,vmin=-1,annot=True
)
correlation_matrix = train_data.corr()
print(correlation_matrix)

AgeとExperienceの間に強い正の相関がある。
Experienceは絶対値処理していることから、モデル作成時に特徴量から
除外してよいと考える。
IncomeとCCAvgの間に強い相関がある。
収入が高いほどクレジットカード支出額が多くなる傾向が見られる。
Mortgageと強い相関のある変数はない。
6、目的変数との関係調査
数値変数との関係調査
Personal Loanの値ごとに数値変数「Age、Experience、Income、CCAvg、Mortgage」の分布を確認する。
# Personal Loan 列が 0 の場合のデータ
loan_0 = all_df[all_df['Personal Loan'] == 0]
# Personal Loan 列が 1 の場合のデータ
loan_1 = all_df[all_df['Personal Loan'] == 1]
# 各変数ごとに分布をグラフ化
numeric_columns = ['Age', 'Experience', 'Income', 'CCAvg', 'Mortgage']
plt.figure(figsize=(15, 10))
for i, column in enumerate(numeric_columns, 1):
plt.subplot(2, 3, i)
sns.distplot( loan_0[column], color = 'skyblue')
sns.distplot( loan_1[column], color = 'darkorange')
Age、Experienceは分布の差異はあまりない。
Personal Loanが「0」の場合、Incomeは低く、Personal Loanが「1」の場
合、Incomeは高い傾向。
Personal Loanが「0」の場合、CCAvgは低く、Personal Loanが「1」の場
合、CCAvgは比較的高い傾向。
カテゴリカル変数との関係調査
Personal Loanの値ごとにカテゴリカル変数「Family、Education、Personal Loan、Securities Account、CD Account、Online、CreditCard」の分布を確認する。
import seaborn as sns
import matplotlib.pyplot as plt
# Personal Loanが0と1のデータを分ける
loan_0_data = all_df[all_df['Personal Loan'] == 0]
loan_1_data = all_df[all_df['Personal Loan'] == 1]
# カテゴリカル変数のリスト
category_columns = ['Family', 'Education', 'Securities Account', 'CD Account', 'Online', 'CreditCard']
# カテゴリカル変数ごとにPersonal Loanごとの分布をプロットする関数
def plot_categorical_distribution_for_loan(data_0, data_1, category_columns):
fig, axes = plt.subplots(len(category_columns), 2, figsize=(15, 15))
for i, column in enumerate(category_columns):
sns.countplot(data=data_0, x=column, ax=axes[i, 0], color='skyblue')
axes[i, 0].set_title(f'{column} (Personal Loan=0)')
axes[i, 0].set_xlabel('')
axes[i, 0].set_ylabel('Count')
total_0 = len(data_0)
for p in axes[i, 0].patches:
height = p.get_height()
axes[i, 0].annotate(f'{height / total_0:.2%}', (p.get_x() + p.get_width() / 2., height), ha='center', va='bottom')
sns.countplot(data=data_1, x=column, ax=axes[i, 1], color='orange')
axes[i, 1].set_title(f'{column} (Personal Loan=1)')
axes[i, 1].set_xlabel('')
axes[i, 1].set_ylabel('Count')
total_1 = len(data_1)
for p in axes[i, 1].patches:
height = p.get_height()
axes[i, 1].annotate(f'{height / total_1:.2%}', (p.get_x() + p.get_width() / 2., height), ha='center', va='bottom')
plt.tight_layout()
plt.show()
# グラフの描画
plot_categorical_distribution_for_loan(loan_0_data, loan_1_data, category_columns)


Personal Loanが「1」の場合、Familyが多くなる傾向。
Personal Loanが「1」の場合、Education:教育レベルが高くなる傾向。
Seculities AccountはPersonal Loanの値で分布は大きく変わらない。
Personal Loanが「1」の場合、CD Account:定期預金口座を持っている
傾向。
OnlineはPersonal Loanの値で分布は大きく変わらない。
CrejitCardはPersonal Loanの値で分布は大きく変わらない。
7、モデル作成・評価
カテゴリカル変数の変換
カテゴリカル変数「Agebin、Incomebin、CCAvgbin、Mortgagebin、Family、Education、CD Account」をOne-Hot_Encodingで変換する。
# カテゴリカル変数をOne-Hot_Encodingで変換
all_df_fin = pd.get_dummies(all_df, columns= ['Agebin', 'Incomebin', 'CCAvgbin', 'Mortgagebin', 'Family', 'Education', 'CD Account'])
print(all_df_fin.columns)データ処理
前処理したデータを訓練データとテストデータに分割する。
Personal Loanを目的変数に設定する。
投入する特徴量は「Agebin、Incomebin、CCAvgbin、Mortgagebin、Family、Education、CD Account」に設定する。
学習に使用しない特徴量を訓練データから削除する。
訓練データをテストデータと検証データに分割する。
from sklearn.model_selection import train_test_split
# 前処理を施したall_dfを訓練データとテストデータに分割
train = all_df_fin[all_df_fin['Test_Flag']==0]
test = all_df_fin[all_df_fin['Test_Flag']==1].reset_index(drop=True)
# 訓練データのPersonal Loanをtargetにする
target = train['Personal Loan']
# 今回学習に用いないカラムを削除
drop_col = ['ID', 'Age', 'Experience', 'Income', 'ZIP Code', 'CCAvg', 'Mortgage',
'Personal Loan', 'Securities Account', 'Online', 'CreditCard',
'Experiencebin', ]
train = train.drop(drop_col, axis=1)
test = test.drop(drop_col, axis=1)
# test_size=0.2とすることで訓練データの2割を検証データにしている
X_train ,X_val ,y_train ,y_val = train_test_split(
train, target,
test_size=0.2, shuffle=True,random_state=0
)ロジスティック回帰モデル作成・評価
ロジスティック回帰モデルを作成する。
作成したモデルの正解率、適合率、再現率、F1スコアをそれぞれ算出する。
#ロジスティック回帰
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score
# モデルを定義し学習
model = LogisticRegression()
model.fit(X_train, y_train)
# 訓練データに対しての予測を行い、正答率を算出
y_pred = model.predict(X_train)
# 正解率を計算
accuracy = accuracy_score(y_train, y_pred)
print("Accuracy:", accuracy)
# 適合率を計算
precision = precision_score(y_train, y_pred)
print("Precision:", precision)
# 再現率を計算
recall = recall_score(y_train, y_pred)
print("Recall:", recall)
# F1スコアを計算
f1 = f1_score(y_train, y_pred)
print("F1-Score:", f1)
正答率 (Accuracy):正しく分類された割合は0.96
F1スコア (F1-score): 適合率と再現率の調和平均は0.77
混同行列を作成
混同行列を作成し、モデルの予測結果とクラスラベルとの間の関係を可視化する。
from sklearn.metrics import confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
# 混同行列を計算
cm = confusion_matrix(y_train, y_pred)
# 可視化
sns.heatmap(cm, annot=True, fmt='g', cmap='Blues', cbar=False)
plt.xlabel('Predicted')
plt.ylabel('True')
plt.show()
混同行列の算出結果は以下の通りとなった。
真陽性:210(6.6%)
偽陽性:35(1.1%)
偽陰性:91(2.8%)
真陰性:2864(89.5%)
偽陽性と偽陰性は全体の4%ほどとモデル精度は高いと評価する。
各特徴量の貢献度
特徴量の重要度を視覚化するために、各特徴量の係数を棒グラフで表示する。
import matplotlib.pyplot as plt
# モデルの係数を取得
coefficients = model.coef_[0]
# 各特徴量の名前と係数を格納するリストを作成
feature_names = train.columns
# 棒グラフを作成
plt.figure(figsize=(10, 6))
plt.barh(feature_names, coefficients)
plt.xlabel('Coefficient')
plt.ylabel('Feature')
plt.title('Feature Importance')
plt.show()

Income、Education、CD Account、CCAvg、Familyの順に重要な特徴量で
あったと言える。
「6、目的変数との関係調査」でIncome、CCAvg、Family、Education、
CD Accountが目的変数Personal Loanと関係しているという分析と一致し
ている。
各特徴量の重要度、各係数の符号から以下の特徴を持つユーザーが個人ロ
ーンサービスの需要を持つと推測される。
・収入が中程度から高い(Incomebin_2、Incomebin_3、Incomebin_4)
高い収入を持つユーザーは、金融商品やサービスを利用しやすく、個人ロ
ーンサービスを利用しやすい。
・家族の規模が中程度から大きい(Family_3およびFamily_4):
大きな家族を持つユーザーは、金融ニーズが多様であり、個人ロ
ーンサービスを利用しやすい。
・教育レベルが高い(Education_2およびEducation_3)
高い教育レベルを持つユーザーは、金融取引や投資に関する知識が豊富で
あり、銀行サービスや投資商品を積極的に利用する可能性が高い。
預金口座(CD Account)を持っている(CD Account_1):
預金口座を持つユーザーは、貯蓄や投資に関心があり、他の金融商品やサ
ービスも利用しやすい。
8、まとめ・今後の発展
まとめ
個人ローンサービスの利用状況データを用いて、サービスの利用に関する分析を行いました。その結果、収入、家族構成、教育レベル、預金口座の有無などの情報がサービスの利用に影響を与えていることが明らかになりました。さらに、これらの要因を考慮したモデルを作成し、そのモデルが一定の精度を持つことを確認しました。
この調査により、個人ローンサービスの利用には収入や家族構成などの要因が関連しており、これらの要因を正確に把握することで、将来のサービス利用の予測が可能であることが示唆されます。
今後の発展
今回の分析レポートでは、ロジスティック回帰を利用したモデルの構築に焦点を当てました。しかし、今後の発展に向けて、決定木やニューラルネットワークなどの異なる手法を用いたモデルの作成を検討しています。これにより、より高い精度のモデルが構築できる可能性があります。
また、通常のビジネスで使用されるデータは非常に多様であり、さまざまな種類のデータが存在します。そのため、今後の課題として、ビジネス理解や分析の深さをさらに向上させる必要があると考えています。これにより、より洞察に富んだ意思決定が可能になり、ビジネスの成果をさらに向上させることが期待されます。
この記事が気に入ったらサポートをしてみませんか?