
最初からリッチなデータ基盤に手を出して失敗しないために【データ利活用の道具箱#7】

データ利活用を進めるにあたり、避けては通れないのがデータ基盤です。
データ基盤とはデータを収集・管理・分析するためのシステム群のことです(イメージとしては後述の目次の「一般的なデータ基盤」を参照)。
そんなデータ基盤ですが、いざ作ろうとするといろいろな悩みがあります。
あれもしたい、これもしたい、で気づけば大規模のデータ基盤になってコスト試算してみるととんでもない額になり投資の承認が下りない
ただ漠然としたイメージしかなく、何を作ってどう進めていいかわからない
データ基盤はできたものの、作りっぱなしで新しいことに踏み出せない
本記事では、このような悩みを解決するために、「最小限の環境」をキーワードにデータ利活用の進め方やデータ基盤構築の第一歩を紹介します。あわせて、実際のデータ利活用シーンを想定しながら、具体的な構築プロセスの例もあわせて紹介します。
最初からリッチなデータ基盤を作ってしまうと何が起きるのか?
ある企業の例を紹介します。この企業では、初期構想時から「何でもできる、どんな要望にも応えられるデータ基盤」を目指し、巨大なデータレイク・DWHを構築しました。データも複数のバッチで連携するようなデータ基盤を構築していました。
こうしてデータ基盤が巨大になると、機能を追加する場合の影響範囲が大きくなり、影響調査や改修にかかる時間やコストが大きくなってしまっています。
そのため、事業側が求める納期や予算に対応することができず、現場ニーズに対応できないデータ基盤となった結果、利用されなくなっていきます。
こういった事象は様々な企業で見られ、データ基盤の構築・活用が進まない代表例と言えます。
この例では、データ基盤の構築には成功していますが、「何でもできる、どんな要望にも応えられるデータ基盤」を最初から目指した結果、基盤構築が途中で頓挫するケースも少なくありません。
活用が進まないデータ基盤にしないために
例示した企業に対して、改めてデータ基盤の構築を提案してみます。
一番重要なことは、着実に成果を出すための最小限の環境からスタートすることです。
最初から高い目標を掲げず、小さな目標から一歩ずつ成果を積み重ねていくデータ利活用(データを活用した仮説検証・実証)を行っていくことが大切です。
そしてデータ基盤についても、まずは小さな目標を達成するための最小機能を最小限の労力で構築・運用できるものが求められます。
例えば「データの可視化もできていないのにAIを使って分析・予測を行えるようにする」といった、大きな成果を最初から目指してしまうとデータ基盤構築に着手することすら困難になってしまいます。
まずは、どんなに小さくても現場での困りごとを解決し、要望をかなえることを優先することから始めます。
そうして、小さな成果を積み重ねることで、データ利活用の活動とデータ基盤が必要であること、重要であることを事業部門や役員など、社内中に知ってもらうことができ、次のデータ利活用のサイクルを回しやすくなります。
目標設定⇒仮説設定⇒構築⇒検証のサイクルをまわし、クイックに成果を出す活動を継続することで、最終的にはより大きな成果につながる、データ分析や予測といったことにも着手することができるようになります。
着実に成果を出すための最小限の環境を作る
サイクルを回し始めるためには、前述の通り、最小機能を最小限の労力で構築・運用できるデータ基盤が求められます。重要なことは、なるべくコストをかけないことです。
ここではその環境を「最小限の環境」と定義しています。
小さな成果を出すために大きなデータ基盤を作ってしまうと、成果に見合わない大きなコストが発生してしまいます。これは費用対効果の面で適切ではありません。活動の承認が会社として下りなくなり、サイクルを回していくことができなくなってしまいます。
また、データ利活用において仮説通りの結果とならないこともあります。その時でも、最小限の環境であれば、クイックに次の仮説実証へ進むことができ、検証のサイクルを回し続けることができます。
ここで、「一般的なデータ基盤」の構成を見てみましょう。
一般的なデータ基盤

こういったアーキテクチャはデータ利活用の初期段階の環境としては過剰であることが多いです。
最初の段階においては、コネクタやサービスレイヤーを利用するような、大量データや大勢の利用者が求められるケースは少ないためです。
仮説検証を繰り返し実施していく中で発生する必要な機能や、ユーザからの要望を実現するために必要な機能をその都度追加していく、という考え方が大切です。
データ基盤を進化させる3ステップ
例示した企業に対して私が提案するのであれば、以下のようなステップ・構成案を考えます。
ステップ1:まずはデータ可視化!

データソースから直接、手作業で、データ利活用レイヤーにデータを持ってきて、スナップショット的に可視化・分析を行う構成です。
例えば、一部の社員だけを対象にして、小さく始める場合に適した構成でしょう。
週一回や月一回といった低頻度のデータ更新なのであれば、この構成のように手作業で運用する、というのも一つの手です。シンプルに素早く導入できるので、運用してみて効果を確認し、次のサイクルにつなげていく第一歩としても有効です。
また、常に決まったフォーマットで可視化を行うのであれば、BIツールではなく表計算ツールでも十分実現可能です。そういった可視化も十分にデータ利活用と言えるでしょう。
データ利活用において、この構成が本当の最小限の構成です。
ステップ2:データ分析もやってみたい!

表計算ツールでもある程度の分析は可能ですが、大量なデータを利用、複雑な数理手法・数理モデルを利用する分析には、BIツールや統計分析に特化したツールが必要になります。
それでもアーキテクチャとしては大きく変わるところはなく、データ利活用レイヤーに機能が増えるだけです。
こういった場合でも、ステップ1と同様に利用する社員は特定のユーザだけに限られるでしょう。
ステップ3:もっといろいろやりたい!
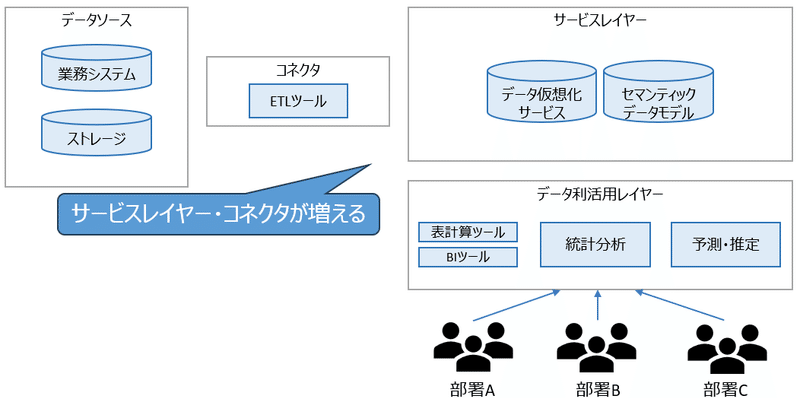
高度なデータ分析(予測・推定、など)まで行おうとすると、データソースから直接データを取り込むやり方だとうまくいかないことがあります。そのため、コネクタやサービスレイヤーで事前にデータが加工できるようにする必要が出てきます。
また、ステップ1や2でできることを複数の部署に展開したり、データソースをもっと増やしたり、精度向上のためにデータの加工をしたりする際には、コネクタやサービスレイヤーが効果を発揮するようになります。
最終的には「一般的なデータ基盤」のような構成になってきます。
おわりに
最初からリッチなデータ基盤を作ろうとしてしまうとどんな失敗をしてしまうのか、そして、その失敗を回避するための大切な考え方とデータ基盤構成例をご紹介しました。
データ利活用は、データ基盤を作ってハイおしまい、というものではありません。何度も「目標⇒仮説⇒実装⇒検証」のサイクルを回しながら、プロセスや規模など、少しずつ成長していきます。それに合わせてデータ基盤への要求も増えていくので、基盤に求められる機能も少しずつ成長していくはずです。
だからこそ、一度で作りきろうとはせずに、実現できそうな小さな目標を達成し続けていくという意識が大切です。
「現場で使える!コンサル道具箱」は、その名の通りすぐに現場で使えるコンテンツを無料でご提供している note です。あなたの欲しい道具が探せばあるかも?ぜひ他の記事もご覧ください!
Appendix:用語説明
コネクタ:
データソースからサービスレイヤー、データ利活用レイヤーへデータを連携する際に活用されるもの。複数のデータソースがある場合のデータ連携を容易にしたり、データの連携の際にデータの加工を行ったりする場合に活用する。
データ利活用の最初の段階では、対象のデータソースの数も少なく、データの加工要否もデータソースの実態を知る、可視化ができてない限りは不明確であるため、最初の段階においては不要なケースが多い。
サービスレイヤー:
データ利活用レイヤーにてデータを可視化・分析する際に、利用者にわかりやすい形でデータを保持しておくレイヤー。複数のデータソースのデータを参照する場合、データソース間の行き来が頻繁に発生、それぞれのデータソースで同じデータだが表現が異なり利用者によって解釈が変わる、といった弊害が出る。それを吸収するのがサービスレイヤーである。
複数のデータソースや複数の利用者が対象にならない最初の段階においては不要なケースが多い。
データ仮想化サービス:
複数のデータソースを仮想化し、抽出・統合などの作業を容易にするもの。
セマンティックデータモデル:
データ指標の乱立による認識齟齬などを無くし、複数の利用者が同じ認識をできるようにするための仕組み。
例えば、Aシステムでは「収入」、Bシステムでは「売上」という名前でそれぞれ管理しているが、どちらのシステムでも「売上(商品を売って得た利益)」を指している、といった揺らぎを吸収する仕組み。