
Raspberry Pi + Juliusで、音声認識→カレンダー登録QR用コード生成をやってみる 後編

作成編です。
何やかんやあって約一か月経ってしまいました。
* 使用ライブラリや遊んだ記録などは前編に記載しています(こちら)
ライブラリのインストール方法などは割愛します。
処理の流れ
1. RaspberryPi(マイク)に発声
2. モジュールモードで起動したJuliusで音声をテキスト化→TCPで送信
3. Node-REDで情報を受け、必要な情報が揃っていればiCalender形式にし、ローカルにファイルを生成、完了後にpythonをキック
4. pythonスクリプト内で、Node-REDフローで生成したファイルを元にqrコードの画像を生成し、電子ペーパーに表示
5. スマホなどで読み取るとイベント登録ができる
JuliusとNodeREDを連携させる
Juliusは細かい設定いじるとキリがなくなるのでデフォルトでいきます。
Juliusをモジュールモードで実行させます。
* -moduleでモジュールモードで駆動します
> julius -C main.jconf -C am-gmm.jconf -moduleNode-REDのTCPノードを使用し、ポートを指定してTCP接続をかけます。
* Juliusのデフォルトポートは10500番
接続できました。
読み取ったテキストをNode-REDで受ける処理
Juliusのログは以下のようなxmlで発行されます。
<STARTPROC/>
<INPUT STATUS="LISTEN" TIME="994675053"/>
<INPUT STATUS="STARTREC" TIME="994675055"/>
<STARTRECOG/>
<INPUT STATUS="ENDREC" TIME="994675059"/>
<GMM RESULT="adult" CMSCORE="1.000000"/>
<ENDRECOG/>
<INPUTPARAM FRAMES="382" MSEC="3820"/>
<RECOGOUT>
<SHYPO RANK="1" SCORE="-6888.637695" GRAM="0">
<WHYPO WORD="silB" CLASSID="39" PHONE="silB" CM="1.000"/>
<WHYPO WORD="上着" CLASSID="0" PHONE="u w a g i" CM="1.000"/>
<WHYPO WORD="を" CLASSID="35" PHONE="o" CM="1.000"/>
<WHYPO WORD="白" CLASSID="2" PHONE="sh i r o" CM="0.988"/>
<WHYPO WORD="に" CLASSID="37" PHONE="n i" CM="1.000"/>
<WHYPO WORD="して" CLASSID="27" PHONE="sh i t e" CM="1.000"/>
<WHYPO WORD="下さい" CLASSID="28" PHONE="k u d a s a i" CM="1.000"/>
<WHYPO WORD="silE" CLASSID="40" PHONE="silE" CM="1.000"/>
</SHYPO>
</RECOGOUT>
.仕様をみると、認識が成功した場合の音声テキストデータは<RECOGOUT>〜</RECOGOUT>の間にあることがわかります。
データを一行ずつ読み取るようにし、上記区間を結合させて吐き出すような処理にします。
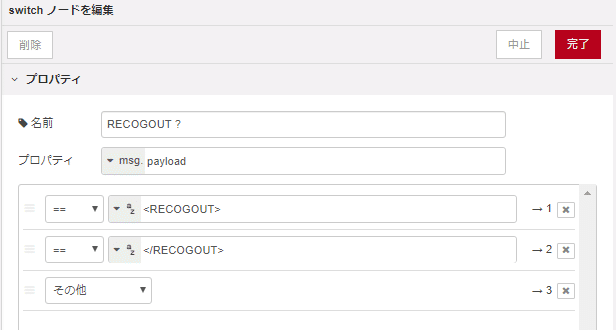
こんな感じになりました。
判定処理
今回の仕様は以下で作ります。
- 「イベント(キーワード)」〜最初の数字(n桁)までをイベント名とする
- 最初の数字と二番目の数字は開始日とする
- 三番目と四番目の数字は開始時間とする
- 五番目の数字は期間(×1h)とする
- 日付は月日、時間は分まで必要、年・秒は不要(簡単な正規化処理は設ける)
- ○時から→○時00分から
- ○時半から→○時30分から
- 期間は1h単位、分単位での指定は不可(処理は可能だがユーザが想定した動作にならない)
- 以下の場合は処理を停止する
- 音声認識が失敗した場合
- 「イベント」というキーワードが含まれていない場合
- 数字が5回を超過して登場した場合
- 使用不可文字
- イベント名への数字(漢数字含む)
- 記号
処理できる音声データ例
・イベント会議5月5日14時から1時間
→処理結果
イベント名 :会議
開始日時 :5/5 14:00
終了日時 :5/5 15:00
・イベント同窓会12月22日19時半から2時間
→処理結果
イベント名 :同窓会
開始日時 :12/22 19:30
終了日時 :12/22 21:30
処理せずに終了する音声データ例
・会議5月5日14時から1時間(ウェイクワード欠損)
・イベント会議5日の10時から1時間(月の欠損)
・イベント会議室1で会議5月5日14時から1時間(数字登場数超過)
処理できるが想定と異なる動作をするデータ例
・イベント会議5日14時30分から1時間30分(月の欠損+期間の指定違反によるフォーマット崩れ)
→処理結果
イベント名 :会議
開始日時 :5/14 30:01 (5/15 6:01)
終了日時 :5/14 60:01 (5/17 12:01)
この辺りはこだわらず割り切っていきます。
本気で作るならJuliusの辞書から、、、ですね。
最終処理
取得情報はiCal形式にし、ラズパイのローカルディレクトリにテキストファイルとして保存。
雑にくっつけます。
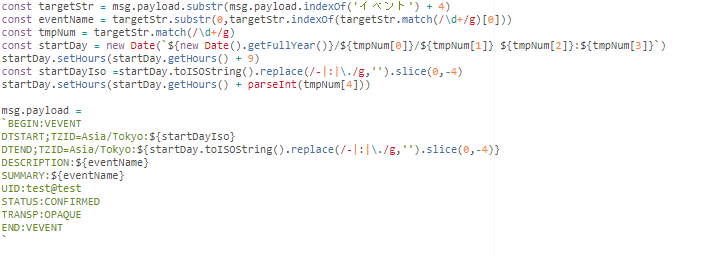
最後にPythonをキックするノードを置いて完成です。
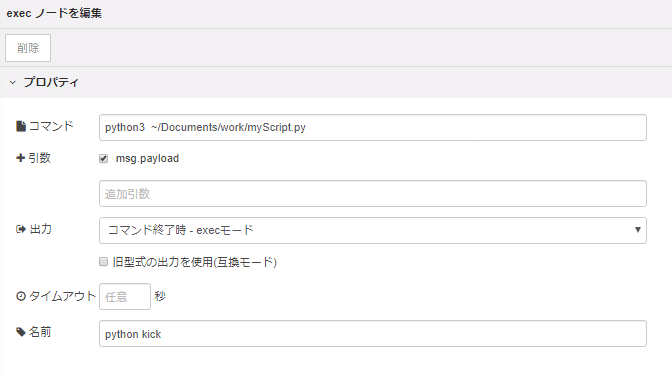
動かすとこんな感じになります

表示した結果。見切れてます・・・。
もっと大きいディスプレイが必要。。。
↓こんなのが生成されます。ねんのため。

これで何が嬉しいか
予定共有者の連絡先情報がわからなくても予定を共有できるところ…?
ただ強制力もないし、人数把握もできないので実用性には乏しい、、、
不特定多数に対してのイベント集客とかはできるかも…?
何かに活用できる?
音声→視覚情報の提供はスマートディスプレイなどで実用化されていますが、1画面で視覚的に認識できる情報には限界がありますし、そこからの動作・行動範囲が限定されます。
不自由さを感じない自由度であるとして、ユーザの動作を狭めること自体はまあ良しとしても行動範囲の限定はUX的にどうなんでしょう。
* インプット端末をスマホにしてスマホへの提供、もありますが、入り口のインタフェースは広い方がいいですよねーーー。
そこで、音声認識→複合情報を提供できるようなものにし、
選択肢の幅を広げていくのは有りなのではないでしょうか。
音声→音声返答だと情報が耳に入るまで結構時間かかるんですよね…。
おわりに
と、いうわけで音声認識とQRコードでいろいろと遊んでみました。
QRコード、できること多すぎるので、暇を見つけてもう少し触ってみたいです。
自分のスマホで読み取って色々なことできるのって、なんかわくわくしますよね。
こういうの体験化っていうんでしょうか。。。
音声認識も辞書作ってしっかり作ってみたいです。
時間があればNTTコムのCOTOHA APIも触ってみたいんですよね。
今回で一旦音声やらQRコード系は終わりにしておきます。
次回は最近買った3Dプリンタで何か作るやつやりたい。
それでは。
散財します。