カーブフィッティングのパラメータ精度推定〜光と闇 (Matlab vs Mathematica vs Python)

Matlabのフィッティングで遭遇した不可思議
データを扱う仕事をする者や理工系の学生ですと、誤差付きデータにモデル関数をフィッティングして、モデルパラメータを推定するというシチュエーションには、一度ならず遭遇しますよね。
そんなとき大学などにいるとMatlabがサイトライセンスされているし、関数ひとつでフィッティングできるから、やっぱり使いたくなりますよね。
ところが、Matlabによるフィッティングで不可解な結果に遭遇し、混乱してしまいました。測定誤差の大きさを変えても推定されるパラメータの精度(もしくはuncertainty)に変化がなかったのです。例を挙げて見てみます。
Matlabによるカーブフィッティングの例
カーブフィッティングと言いつつ線形フィッティングをするので、ガッカリかも知れませんが、後ほど解析式と比較するためですのでご辛抱ください。とりあえず6点の2次元データxdata, ydataとyの測定誤差yerrの3つ組のデータセットを考えます。
%% Preparation
clear
xdata = [1 2 3 4 5 6];
ydata = [1 2 3 4 4 2];
yerr = [1 1 3 3 1 1];
%% Model fitting
pguess = [0,1];
modelfun = @(b,x) b(1)+b(2).*x;
mdl = fitnlm(xdata, ydata, modelfun,pguess,'Weights',1./yerr.^2)fitnlm関数はStatistics and Machine Learning Toolboxに含まれていて、ポピュラーじゃないかも知れませんが、多分他のフィッティング関数でも本質的なところは変わらないと思います。
%% Model Data Extraction
coef=mdl.Coefficients.Estimate;
b1=coef(1);
b2=coef(2);
coefSE=mdl.Coefficients.SE;
db1=coefSE(1);
db2=coefSE(2);
%% Best Fit Model
xp=[0:0.1:7];
yp=b1+b2*xp;
%% Plot Together
figure(1)
clf
orient landscape
errorbar(xdata,ydata,yerr,'b.','MarkerSize',20);
hold on
plot(xp,yp,'r-')
grid on
ylim([-1,8])フィッティングの結果です
mdl =
Nonlinear regression model:
y ~ b1 + b2*x
Estimated Coefficients:
Estimate SE tStat pValue
________ _______ ______ _______
b1 1.1757 0.891 1.3196 0.25744
b2 0.32573 0.22076 1.4755 0.21411
Number of observations: 6, Error degrees of freedom: 4
Root Mean Squared Error: 0.912
R-Squared: 0.352, Adjusted R-Squared 0.191ここで大事なのはデータをy=b1+b2*xという線形関数でフィットしたとき、b1、b2についてはStandard Error付きで
b1 = 1.1757 +/- 0.891
b2 = 0.32573 +/- 0.22076
であるという事です。フィッテイング結果をプロットで見ると(ここではb1,b2のerrorは可視化されないですが)
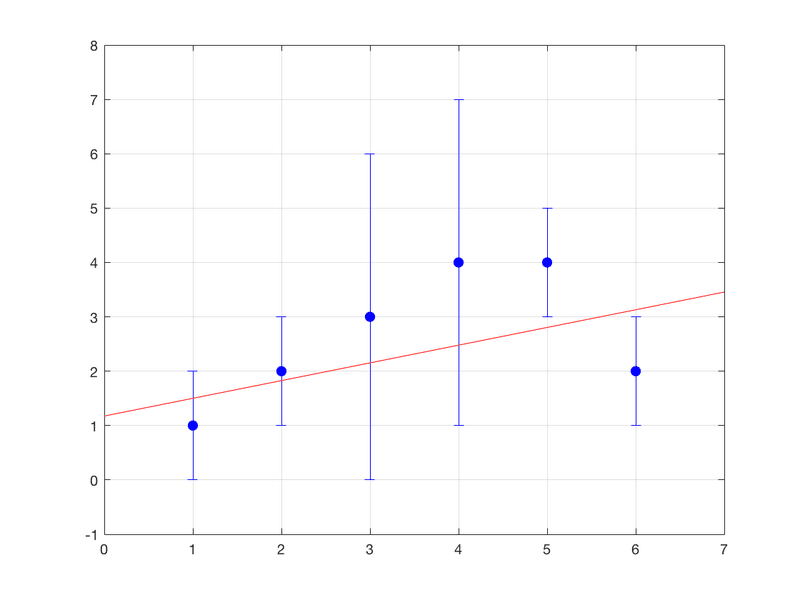
まあフィッティング自体は問題ないですね。
ところで、yerrが100倍だったとすると、それに比例してb1やb2の推定が悪くなると予想されるわけです。では続けて次のコードを走らせてみると
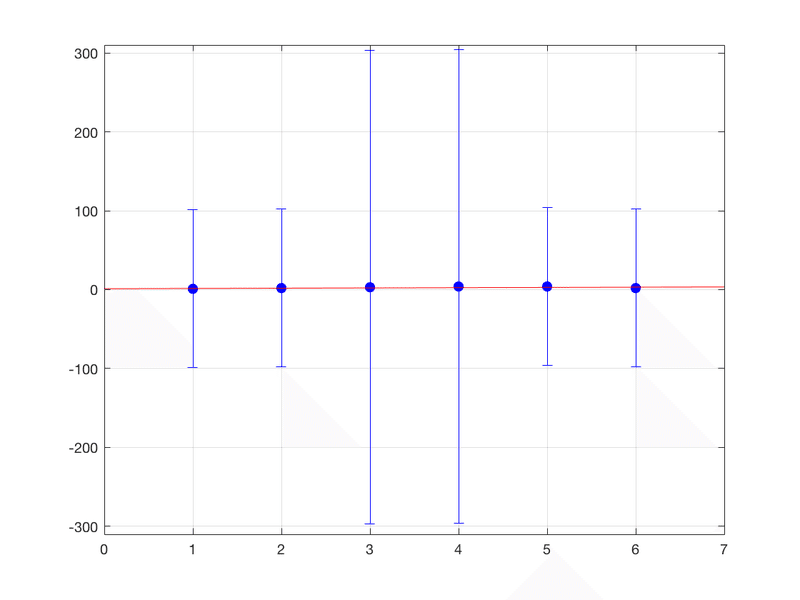
誤差がメチャクチャでかいので、フィットデータの傾きなんてほとんどsignificanceが無くなってしまうほどです。フィッティングの結果出力はと言うと
mdl2 =
Nonlinear regression model:
y ~ b1 + b2*x
Estimated Coefficients:
Estimate SE tStat pValue
________ _______ ______ _______
b1 1.1757 0.891 1.3196 0.25744
b2 0.32573 0.22076 1.4755 0.21411
Number of observations: 6, Error degrees of freedom: 4
Root Mean Squared Error: 0.00912
R-Squared: 0.352, Adjusted R-Squared 0.191
F-statistic vs. constant model: 2.18, p-value = 0.214b1 = 1.1757 +/- 0.891
b2 = 0.32573 +/- 0.22076
はっ!?なぜ?ホワーイ?誤差が大きくなっているのに、パラメータの誤差に反映されない、これは重大な問題ではないか?
Mathematicaではどうなのか
ではMathematicaではどうなのか。
(* Data *)
data = {{1, 1}, {2, 2}, {3, 3}, {4, 4}, {5, 4}, {6, 2}}
sdvY = {1., 1., 3., 3., 1., 1.};
dataX = Transpose[data][[1]];
dataY = Transpose[data][[2]];
(* Mathematica No Option *)
fitObj = NonlinearModelFit[data, a + b x , {a, b}, x, Weights -> 1/sdvY^2]結果はこうなりました
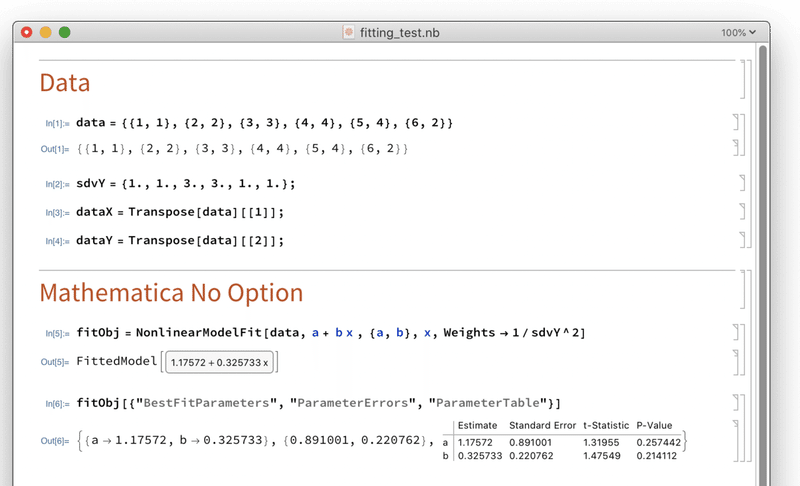
b1 = 1.17572 +/- 0.891001
b2 = 0.325733 +/- 0.220762
Matlabと同じ答えになります。そしてMathematicaのヘルプには次のような記述があります。
データの誤差が分かっている場合
VarianceEstimatorFunction -> (1 &)
というオプションを使うといいよ
ははぁ!つまりですね、オプションをつけないと、モデルとデータの食い違い(残差: residual)から算出したχ2(カイ二乗)が1になるように、データの誤差をスケールしてしまう。これは物理屋にとってはヤバイ改竄ですね。データの誤差が測定などから既知の場合は上記のオプション使うといいよ、と言う意味です。

b1 = 1.17572 +/- 0.977284
b2 = 0.325733 +/- 0.24214
誤差が変わりましたね。誤差を100倍にしてやると、

b1 = 1.17572 +/- 97.7284
b2 = 0.325733 +/- 24.214
おお、ちゃんとパラメータの誤差も100倍になりました!
Bevingtonにあたる
では、ここはいっちょ解析式に当たって白黒つけようじゃないですか。
Data Reduction and Error Analysis for the Physical Sciences
Bevington, Philip R.; Robinson, D. Keithの第6章で扱っている線形フィッティングの解析式を利用します。
データxi, yi, yの測定誤差σiに対し、y=a+b xでフィッティングをしたとき。
a, bのパラメータ推定値は以下のようになり(Δは補助的に使う行列式)、その誤差はσa、σbで表されます。(最後にσbがσaに誤植になっていますけど)

これをMathematicaで書きます。
sY = Apply[Plus, dataY/sdvY^2];
sX = Apply[Plus, dataX/sdvY^2];
sXY = Apply[Plus, dataX dataY/sdvY^2];
sX2 = Apply[Plus, dataX^2/sdvY^2];
s = Apply[Plus, 1/sdvY^2];
delta = Det[{{s, sX}, {sX, sX2}}];
esta = Det[{{sY, sX}, {sXY, sX2}}]/delta
estb = Det[{{s, sY}, {sX, sXY}}]/delta
sa = Sqrt[sX2/delta]
sb = Sqrt[s/delta]
b1 = 1.17572 +/- 0.977284
b2 = 0.325733 +/- 0.24214
おお、ちゃんとMathematicaでVarianceEstimatorFunctionを無効にするオプションをつけて実行したときと一致しました!
Pythonはどうなんや
こうなったらPythonでもやってみます。コードは以下の通りです。
import numpy as np
from scipy.optimize import curve_fit
def f( x, a, b):
return a + b*x
xdata = (1, 2, 3, 4, 5, 6)
ydata = (1, 2, 3, 4, 4, 2)
yvals_err = (1, 1, 3, 3, 1, 1)
popt, pcov = curve_fit(f,xdata,ydata,sigma=yvals_err)
print("default")
print("popt = ", popt)
print("perr = ", np.sqrt((pcov[0,0],pcov[1,1])))
popt, pcov = curve_fit(f,xdata,ydata,sigma=yvals_err,absolute_sigma=True)
print("with absolute_sigma")
print("popt = ", popt)
print("perr = ", np.sqrt((pcov[0,0],pcov[1,1])))実行結果
default
popt = [1.17572433 0.3257329 ]
perr = [0.89100123 0.22076223]
with absolute_sigma
popt = [1.17572433 0.3257329 ]
perr = [0.97728356 0.2421403 ]PythonもMathematicaと同じ結果になりました!つまり、scipyのcurve_fitにabsolute_sigma=Trueオプションをつける事でスケーリングを回避できます。
結論
・Matlabのfittingルーチンはフィッティング後のχ2が1になるように「データの誤差」をスケールしてしまう。これはもしデータの誤差が正規分布に従うのであれば、χ2は1になるはずであるというナイーブなロジックに基づいている手法である。測定データに命をかけている物理屋にとっては非常に危険である!
・Mathematicaもデフォルトでは同じことをするので危険。だが、NonlinerModelFitにVarianceEstimatorFunction -> (1 &)のオプションをつけることで、この勝手なスケーリングを回避する事が出来る。
・Pythonもデフォルトでは誤差のスケーリングがおこなわれる。ただし、absolute_sigma=Trueオプションをつける事で回避可能。
教訓:大きなソフトウェアやライブラリを利用すると、複雑なデータ解析も関数一発でやってしてくれるので非常に便利です。しかし、その中で何が起こっているか、きちんと確認しないと、足下をすくわれる事があります。必ず簡単な例で動作をチェックしたほうがいいです。
この記事が気に入ったらサポートをしてみませんか?