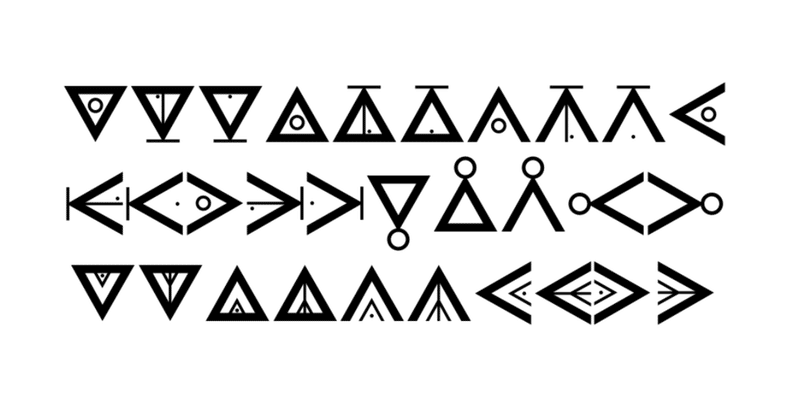
IsiBheqe Sohlamvu/Ditema tsa Dinoko

パラメーションという言葉を聞いたことがあるだろうか? パラメータとシミュレーションを接続した造語で、xR技術が高度化していく中、高度にリアル化した空間内では現実空間では物理的にも倫理的にも不可能な実験が可能になる……云々などという戯れ言を聞いたので、へ〜それは面白いと思って、siri に検索させようとしたんだがどうもパラメーションという言葉が上手く発音できないというか、うまく呂律がまわらない。なんだか、そうやってグダグダやってるうちに、Siriが「このあいだも、そうやっているうちにもういいってなってしばらくかまってもらってくれなかったので……」とか文句を言い出して「もう、いいですよ」プツッってなるので、おい、ちょっとまて、Siri、あっ勝手に切りやがった、ヘイSiri! そんなのまでプログラムしてるのかよ、おい、こらっ……そんなの、あるか、おい! え〜〜〜! ってビックリして飛び起きたら……夢だったっていうことがあって……え? どこからって? いや、もう、最初のパラメーションの件から全部なんだけど…………念のため、パラメーションやParamationで検索したけど、やってんだかやってないんだかわからないシアトルの会社のホームページが出てくるだけ。勿論パラメーションにパラメーションの意味は無い。というか、そういう意味での概念、造語もないようなので、なんか文字通り本当に狐につままれた気分……何やってるんだろう俺。
と、まぁ相変わらずのPRE-STORY PROLOGUE FOR "CONTEXT"だが、とはいっても、前回の件で自分の病気がある程度自覚できたような気がするので……治る治らないは別として……そういうところに自覚的になるのは……まぁ、大事なんだろうな……コレは。
で早速本題。前回のIsiBheqe Sohlamvu/Ditema tsa Dinokoの続き。この、放って置くとグリフの数が10万を遙かに超えて増殖していってしまいかねないという極悪な素性文字を、ある程度使える量の文字量に整理してしまおうというお話。もちろん文字数10万というのは控えめな方の数値なので、この文字で表現可能な子音クラスタの可能性の桁をあげるだけであっという間に100万字を突破する。その可能性に意味があるかどうかということは別としてだけれど、もちろん世の中にはグルジア語のように……え? いま、グルジアっていっちゃいけないの? カルトヴェリ? カルトリ語? ジョージア語まぁ、なんでもいいけど、そのジョルジア語のように6つも8つも子音の並ぶ言葉もあるらしいから……まぁ、それもともかく、まずは、おさらいから。
素性文字としての部品は大別して以下の4種類になる。まず最初に文字のコンテナとなる母音のパーツ。ここへ子音等の素性文字を放り込んで音節文字を形成する。

次に、聞こえ度の低い主音のパーツ、このうちrとlはコンテナと組合せて音素としても使用される。日本語では気にする必要はない。
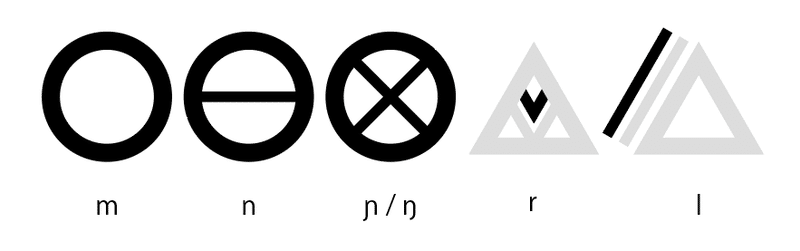
続いて、コンテナの中に入る声調等を指示する記号と鼻音等の指示。
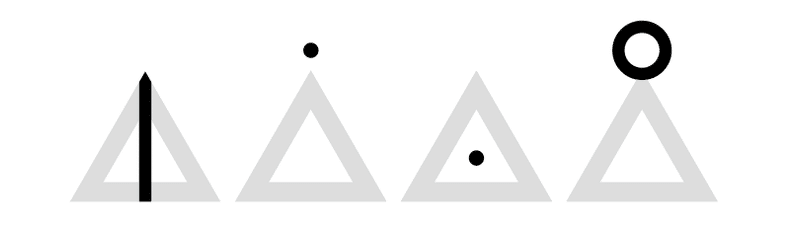
一番右の鼻音の丸の中は以下の通りになる。
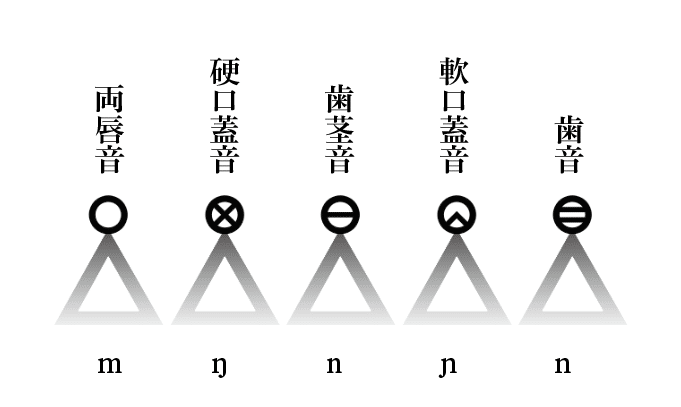
最後にその他の子音。これらの記号はコンテナに組み合わせて使用される。以下の表参照。
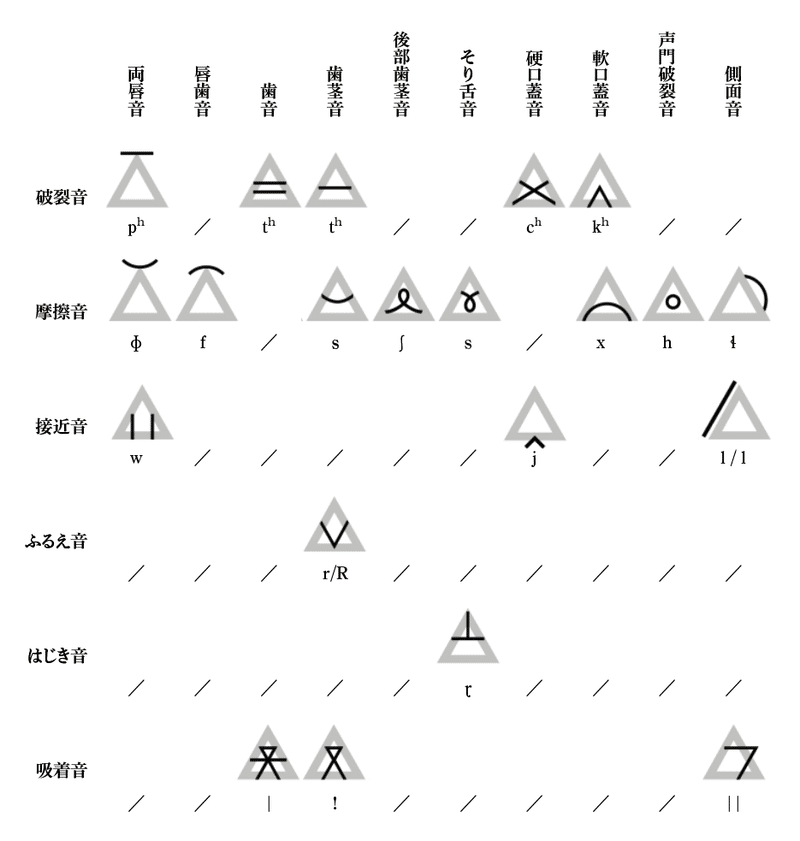
ちなみに文字の下のIPA表記は、わかればいいやで付けてあるので正確ではない。歯音のnやt、そり舌sの下に、「こちょっ」としたり「にょろっ」としたりする物がついていたりする必要があるのだけど……まぁ、そこら辺はいいよね?
で、これらを結合して音節文字にする。音節とは、まぁ、言うまでも無いけど母音を中心とした音のまとまりで、組み合わせ方は基本、母音のみ。子音からはいっての母音終。母音からの子音終。子音+母音+子音。これにこの文字、Ditema tsa Dinokoのグリフは、声調、鼻音の有無をかけ合わせて完成する。ただし、この文字の特徴としてコンテナを母音としているため子音+母音(CV)と母音+子音(VC)の区別が付かないうえに子音結合……複数の子音が連続して子音群を構成する……がおきた場合に関しても、その組み合わせ順はあいまいなままになるのだが……文字の設計に言語学者も関与しているそうなので、音素配列論的にはその順番は自明になるので問題にならない……特に南アフリカ言語では……などと判断されたのだろう……多分。
と、いうわけで、さて、これを使ってDitema tsa Dinoko音節文字のグリフを作っていくわけだが、まぁ、冒頭の話ではないが最初からプログラムでもされていない限りAIにすねて仕事をやめる機能は無いので、こんなものの順列組合せは、AIに任せておけば、人間様の仕事は出力されたものを見ながら、「あ〜、そこ、もうちょっと右……いやぁ〜左かなぁ、あ、右のストロークちょい下げで……あ〜あと、そこのステムはもうちょっと細く、カウンタースペースは左の文字と見た目で揃えて……」とか言ってればOK。毎回気分次第で適当なことしかいわない超低速のデバイスにもAIが根気よく相手をしてくれる。まぁ、とはいっても現時点でそこまで進んだAIが民生用に普及しているわけではないので、残念ながらいまのところは……いつかそうなることも想定しつつ、手作業する必要がある。
まず、コード的には、何を何処に当てるかという問題があるが、現時点ではこの文字はコード化されてはいないので、どの組み合わせを作ればいいのかということがわからない……というところまでが前回のお話の要点。今回はその続きから。

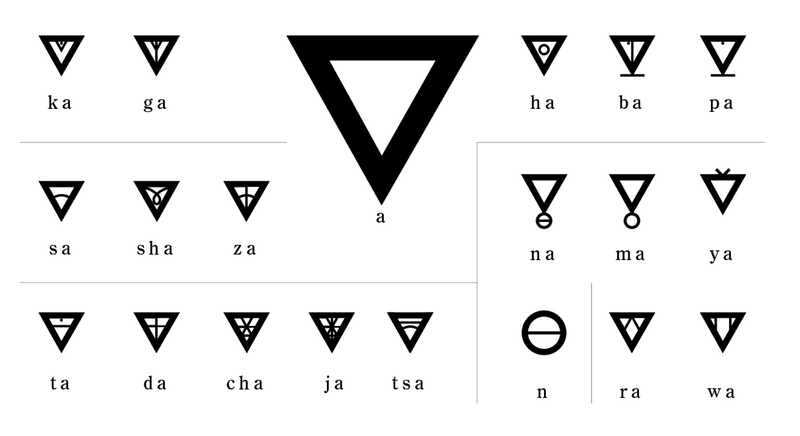
まったくコードを想定しないで、文字だけ作るという方法も無くはないのだが、どうせ音節文字になるのであれば一番身近な音節文字、カタカナの所に突っ込んでおけば、後で何かに使えるだろうという判断も働く。幸い今年はアフリカ開発における東京国際会議、通称アフリカ開発会議(TICAD)の年なので8月に横浜で……って、え? 神奈川じゃん? そこはいいの? まぁ、いいや、うん、それで、なんとなく、なんか用事が出来るかもしれないから……って、え? 押し売り過ぎる? こりゃ失礼。
まぁ、そういうわけで、上の図のように、これを日本語の音節文字に対応する位置で適当に埋めていく、一応ヘボン式をベースにしているのだが……勿論このあたり個人的好みもあるし、実はローマ字表記の問題的な話を始めるとまた長くなる上、あさっての方向に会話がねじ曲がるので、このあたりもホントに超適当。なので上の例が必ずしも正解というわけではない。Ditema tsa Dinoko音節文字はちゃんとやれば日本語の音節文字では不可能な端と橋と箸のかき分けも可能になるのだが……それをする場合の実装上の問題を含めどう解決するかの良いアイデアが浮かばなかったので、そういうところも合わせて実際チャンとはしてはいない。また長母音や捨て仮名をどう考えるかも悩ましい。それだけあっても意味ないし、捨て仮名は直前の母音によって音が変わるのと、そうやって作ったCVCをハングルのように一文字にする発想が日本文字に殆ど無い……まれにツゥ、チェ、トゥをツ゚セ゚ト゚などにするという表記方法も、あるにはあるのだが、これを小学校の義務教育で習った記憶が無いので「ト゚」が「トゥ」の音になるよという人の数が期待できないのと、日本語で頻出するCVCの全ての音がUnicodeになっているわけでもないので……表音文字としては単独では実に使いづらい。小仮名をつくらず合字で対応するのがよさそうではあるのだが……等々とか、そういう問題がいっぱいあるんだよホント。余所のところの文字で自分のところの文字を置き換えようとすればどうやったって無理は発生する。まぁ、ともかく、細かいところを気にしなければこんな感じ。こうすると音のイメージと形がなんとなく揃って見えるような気もするんだけど……まぁ、どうだろう? このあたりも促音の合字も追加して最終的には後でちゃんとしておきたいところ。
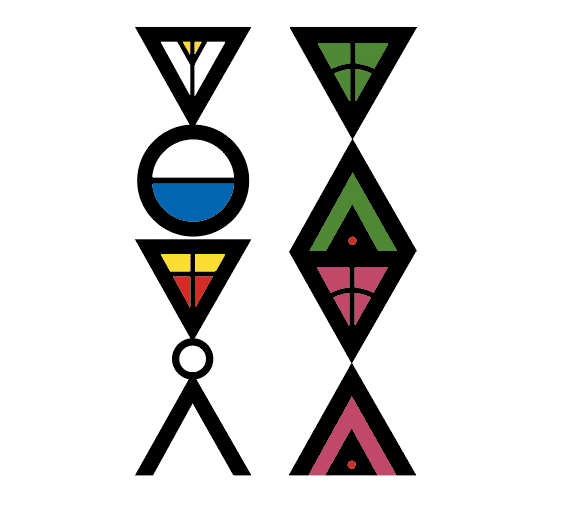
ただまあ、とりあえず現状でも、これで普通にカタカナが通るので、イラレでアウトラインにして、こんな機動戦士な感じのテキストに加工するのは簡単。読める? まぁ、イメージでもわかるか……Aの母音でまとめた図版は以下参照。あとはコンテナの向きだけなので、まぁいいよね?
ということで、この文字、素性文字らしく、可読性は低いので論文書くのには向かないかも知れないけど、読みに慣れてくると図形が単純な分、加工をジャンジャン施しても骨格がぶれないので識別性は高い。単語をクラスタ化することが可能……というか、多分、もともとそういう方向でつくられているので、何百年かするとクラスタ化した概念のまとまりを漢字のように一つのグリフに変化させていくとかっていうことも想定して設計されているのかも……そうなると可読性もあがるしね……まぁ、わからないけど……それで、前回の途中でこのあたりを妄想含みで、いろいろとネタにしようかというアイデアを思いついたんだけれど……色々長くなるのでコレもまぁ、またそのうち。細々積み残しはあるのだけれど、Ditema tsa Dinokoの件は一旦終了です。次回はまた別の話ということで……
この記事が気に入ったらサポートをしてみませんか?