密度準拠型クラスタリングのこころ

Introduction
このノートでは、多変量解析や機械学習の手法「クラスタリング」の具体的な仕組みに興味がある方々に、その具体例として密度準拠型クラスタリングのこころと具体的な計算アルゴリズムの例:DBSCANを紹介します。
1. 密度準拠型クラスタリングのこころ
データを散布図で可視化したとき、そこにクラスターがあると認識するのはどういうときでしょうか。様々な回答が想定できるところですが、例えば次のような回答は納得がいくものではないかと思います。
クラスターの外部よりも内部のほうがデータポイントの密度が高いようなクラスタリングが出来るとき、そこにはクラスターがあると認識できる。
このように各データポイント周辺の密度に注目してクラスターを決定しようという考え方を密度準拠型クラスタリングといいます。
2. DBSCANによるクラスターの計算
密度準拠型クラスタリングの具体的な計算アルゴリズムを見てみましょう。今回は代表例として、DBSCANを紹介します。他にもMean-ShiftやOPTICSなどがありますが、またの機会に解説します。
2.1 DBSCANの計算アルゴリズムの考え方
DBSCANは、データからクラスターのコア点を探し、コア点から到達可能な点をまとめて一つのクラスターを構成します。また、どのコア点からも到達可能でない点は、どのクラスターにも所属させずノイズと表現することにします。
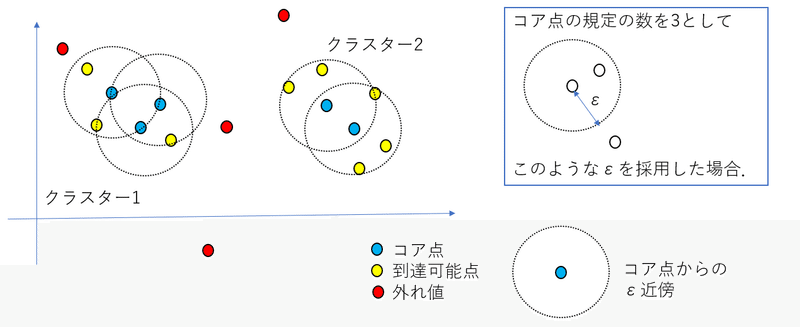
2.1.1 クラスターのコア点
DBSCANには2つのハイパーパラメータがあり、いずれもコア点を決めるために準備されます。コア点の定義とともに2つのハイパーパラメータとその意味を紹介しましょう。
《DBSCANのハイパーパラメータとコア点の定義》
・ハイパーパラメータ:ε, minPts
あるデータポイントPの距離ε以内に他のデータポイントがminPts以上存在するとき、点Pをあるクラスターのコア点であると定義します。
2.1.2 直接到達可能と到達可能
コア点Pから距離ε以内に収まっている点のことを「コア点Pから直接到達可能な点」といいます。また、直接到達可能な関係にあるコア点どうしをすべて結んだネットワークNを考えてください。コア点PがネットワークNに所属するとき、Nに属するコア点の直接到達可能点を「コア点Pの到達可能点」といいます。
2.1.3 クラスター
コア点Pから到達可能なすべての点を一つにまとめて、これを「コア点Pが所属するクラスター」といいます。なお、どのクラスターにも所属しないデータポイントが生じることがあります。このようなデータポイントは「ノイズ」と呼ばれます。
2.2 DBSCANのRを用いた計算
R言語では、dbscanライブラリのdbscan関数を用いて、DBSCANによるクラスターの計算を行うことが出来ます。
# 必要なライブラリのロード
library(dplyr)
library(ggplot2)
library(dbscan)2.2.1 今回のデータセット:moonsデータセット
今回はdbscanライブラリのmoonsデータセットDBSCANでクラスタリングしてみましょう。
# moonsデータセットの準備と可視化
data("moons") # moonsデータセットをロード
data <- tbl_df(moons) # moonsデータセットをtbl_df型に変換する。
ggplot(data = data, mapping = aes(x = X, y = Y)) + geom_point() # 散布図
2.2.2 DBSCANの計算
dbscan関数の使い方は以下の通りです。
《dbscan関数の引数》
・x : データポイント(data.frame型で与える)
・eps : コア点から直接到達可能な半径ε
・minPts : コア点とみなす際の直接到達可能な点の個数の条件
# DBSCANによるクラスターの計算
res <- dbscan(x = data, eps = 0.3, minPts = 3)
res
このような計算結果が出てくると思います。0はノイズ、1-4はクラスターの番号です。今回の場合、4つのクラスターが得られ、3個のデータポイントはノイズとしてどのクラスターにも所属しないと計算したことになります。
2.2.3 計算結果の可視化
各データポイントがどのクラスターに所属するかは、res$clusterで確認することが出来ます。各データポイントが所属するクラスターを散布図で可視化することで確認してみましょう。
# 結果を散布図に可視化する。
data_dbscan <- data %>% mutate(cluster = res$cluster) # dataにクラスターの結果を追加
data_dbscan$cluster <- factor(data_dbscan$cluster) # cluster列をfactor型に変換
ggplot(data = data_dbscan, mapping = aes(x = X, y = Y, colour = cluster)) +
geom_point() # 散布図に可視化
3. 密度準拠型クラスタリングの利点
密度準拠型クラスタリングの利点は次の2点です。
・散布図上で球状でないようなクラスターでも抽出しやすい。
・クラスター数は計算の過程で決まる。
これらはいずれも、例えばk-means法に比べると際立って異なる点です。特にk-means法は球状でないクラスターの抽出が苦手でした。
# k-means法によるmoonsデータセットのクラスタリング
res <- kmeans(x = data, centers = 4, iter.max = 100)
data_kmeans <- data %>% mutate(cluster = res$cluster)
data_kmeans$cluster <- factor(data_kmeans$cluster)
ggplot(data = data_kmeans, mapping = aes(x = X, y = Y, colour = cluster)) +
geom_point()
一方でDBSCANは以下のような欠点を持ちます。
・時間計算量や空間計算量が高い。
・ハイパーパラメータの調整が難しい。(データの理解次第。)
4. おわりに
このノートはピースオブケイク社さんで開かれている多変量解析の勉強会の資料として作成したものです。参加者のみなさまにお礼を申し上げます。
サポートをいただいた場合、新たに記事を書く際に勉強する書籍や筆記用具などを買うお金に使おうと思いますm(_ _)m