Stable Diffusionのimg2imgを「アメトーーク 絵心ない芸人」の絵に使う

Stable Diffusionのv1.5 betaが2022/9/6にDream Studioで先行して試せるようになりました。いままで使ってきたプロンプトやシード値で画像生成してみましたが、またシード値を探しなおす必要があるくらいに変わっていました。Google Colaboratorやパソコンでも使えるようになると良いのですが、v1.5の続報はまた明日とTwitterに書いてありました。
Stable Diffusion 1.5 beta now available to try via API and #DreamStudio, let me know what you think.
— Emad (@EMostaque) September 6, 2022
Much more tomorrow…https://t.co/eosxNTuOvL
◇ 画像とプロンプトで新たな画像を生成する
いままでStable Diffusionで文字から画像を作成する方法(以下txt2img)のみ使っていましたが、良くできた画像をベースに変化を与えたいと思い、パソコンの環境で画像から画像を生成する方法(以下img2img)をできるよう設定しました。
これを利用することで画像と新たなプロンプトを与えて新しい画像を生成することができます。

そこで今回はimg2imgを実行できる環境をパソコンに作成し、アメトーークの「絵心ない芸人」のイラストをベースに画像生成したいと思います。
◇ パソコンにimg2imgの環境を作成する
(1) Gitのインストール
パソコンやGoogle ColaboratoryでStable Diffusionを使うときに必要なPythonライブラリーで「diffusers」というものがありました。pipでインストールできるdiffusersはimg2imgが含まれていないため、gitからクローンしてくる必要があります。この設定を行う上でWindowsパソコンではGitをインストールする必要があります。
インストール時にいくつかウィンドウが表示されますが、「Adjusting your PATH environment」を「Use Git from the Windows Command Prompt」を選択します。これでコマンドプロンプトからgitコマンドを実行できます。
(2) img2img用ライブラリーのインストール
コマンドプロンプトからimg2img用のライブラリを導入します。
git clone https://github.com/huggingface/diffusers.git
pip install git+https://github.com/huggingface/diffusers.git上のpipコマンドが成功していればPythonでimg2img用のimport命令が実行できます。
from diffusers import StableDiffusionImg2ImgPipelineまた入力する画像を読み込む際にPIL(Python Imaging Library)を使いますのでコマンドプロンプトからpillowを導入します。
pip install pillowtxt2imgに対するimg2imgを画像を生成するPythonコードの相違は以下の5点です。
「from PIL import Image」を追加
「from diffusers import StableDiffusionPipeline」から「from diffusers import StableDiffusionImg2ImgPipeline」に変更
「StableDiffusionPipeline.from_pretrained」から「StableDiffusionImg2ImgPipeline.from_pretrained」に変更
新たなパラメーターとして入力する画像ファイルパス「init_image」を追加
新たなパラメーターとして入力した画像に対して入力したプロンプトをどれだけ反映させるかをしめす「Strength」を追加。Strengthは0.0~1.0で表され、値が大きいほど入力したプロンプトの影響を受ける
◇ txt2img / img2imgのPythonコード
(1) img2imgのコード
from PIL import Image
import random
import math
import torch
from torch import autocast
from diffusers import StableDiffusionImg2ImgPipelin
ACCESS_TOKEN="発行したアクセストークンを入力します"
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=ACCESS_TOKEN
).to("cuda")
prompt = "ここに画像生成したいキーワードを英語で入力します"
init_image = Image.open("入力画像ファイルパスを入力します").convert("RGB")
init_image = init_image.resize((512, 512))
strength = math.floor((random.uniform(0.25, 0.75))*100)/100
scale = math.floor((random.uniform(7.5, 8.5))*100)/100
steps = random.randrange(50, 60, 1)
seed = random.randrange(0, 4294967295, 1)
generator = torch.Generator("cuda").manual_seed(seed)
with autocast("cuda"):
image = pipe(
prompt=prompt,
init_image=init_image,
strength=strength,
guidance_scale=scale,
num_inference_steps=steps,
generator=generator
)["sample"][0]
image.save("image.png")(2) txt2imgのコード
import random
import math
import torch
from torch import autocast
from diffusers import StableDiffusionPipeline
ACCESS_TOKEN="発行したアクセストークンを入力します"
pipe = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=ACCESS_TOKEN
).to("cuda")
prompt = "ここに画像生成したいキーワードを英語で入力します"
scale = math.floor((random.uniform(7.5, 8.5))*100)/100
steps = random.randrange(50, 60, 1)
seed = random.randrange(0, 4294967295, 1)
generator = torch.Generator("cuda").manual_seed(seed)
with autocast("cuda"):
image = pipe(
prompt=prompt,
guidance_scale=scale,
num_inference_steps=steps,
generator=generator
)["sample"][0]
image.save("image.png")(3) txt2imgで生成した画像をimg2imgするコード
from PIL import Image
import random
import math
import datetime
import torch
from torch import autocast
from diffusers import StableDiffusionPipeline
from diffusers import StableDiffusionImg2ImgPipeline
class StableDiffusion:
def __init__(self, access_token, prompt, init_image,
strength, scale, steps, seeds):
self.access_token = access_token
self.prompt = prompt
self.init_image = init_image
self.strength = strength
self.scale = scale
self.steps = steps
self.seeds = seeds
def generate_txt2img(self):
generator = torch.Generator("cuda").manual_seed(self.seeds)
pipe = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=self.access_token
).to("cuda")
with autocast("cuda"):
image = pipe(
prompt=self.prompt,
init_image=None,
strength=None,
guidance_scale=self.scale,
num_inference_steps=self.steps,
generator=generator
)["sample"][0]
return image
def generate_img2img(self):
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=self.access_token
).to("cuda")
with autocast("cuda"):
image = pipe(
prompt=self.prompt,
init_image=self.init_image,
strength=self.strength,
guidance_scale=self.scale,
num_inference_steps=self.steps,
generator=None
)["sample"][0]
return image
def save_imgfile(image):
# ファイル作成時間を求める
t_delta = datetime.timedelta(hours=9)
JST = datetime.timezone(t_delta, 'JST')
now = datetime.datetime.now(JST)
pict_name = f"{now.strftime('%Y%m%d%H%M')}_{scale}_{steps}_{seeds}_{strength}.png"
image.save(pict_name)
return(pict_name)
access_token ="発行したアクセストークンを入力します"
# txt2img
prompt = "ここに画像生成したいキーワードを英語で入力します"
init_image = ''
strength = 'na'
scale = math.floor((random.uniform(7.5, 8.5))*100)/100
steps = random.randrange(50, 60, 1)
seeds = random.randrange(0, 4294967295, 1)
sd_txt2img = StableDiffusion(access_token, prompt, init_image, strength, scale, steps, seeds)
file_txt2img = sd_txt2img.generate_txt2img()
pict_name = save_imgfile(file_txt2img)
# img2img
prompt = "txt2imgで生成した画像に追加するキーワードを英語で入力します"
init_image = Image.open(pict_name).convert("RGB")
init_image = init_image.resize((512, 512))
strength = math.floor((random.uniform(0.25, 0.75))*100)/100
scale = math.floor((random.uniform(7.5, 8.5))*100)/100
steps = random.randrange(50, 60, 1)
seeds = ''
sd_img2img = StableDiffusion(access_token, prompt, init_image, strength, scale, steps, seeds)
file_img2img = sd_img2img.generate_img2img()
save_imgfile(file_img2img)◇「アメトーーク 絵心ない芸人」でimg2imgする
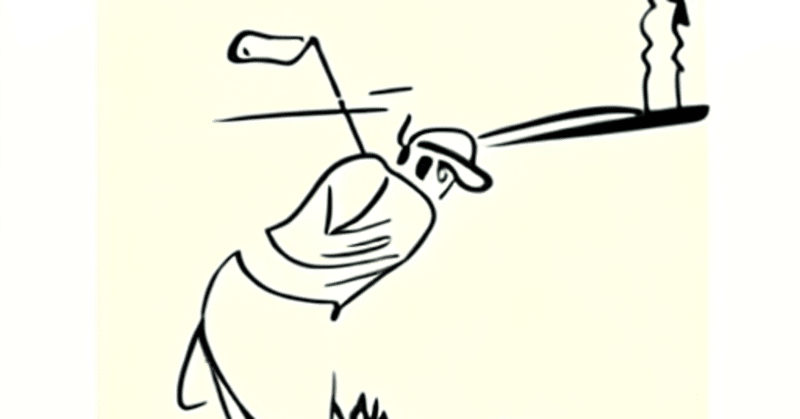
「アメトーーク」のスペシャルで良く採用される企画に登場した絵をStable Diffusionのimg2imgに与え、番組内のお題を含んだプロンプトで実行しました。使用したPython コードは(1)img2imgです。
(1) 陣内智則の「石川 遼選手のナイスショット」

これに以下のプロンプトを入れてimg2imgすると以下の画像が出てきました。
"A great photograph of the most amazing golf hole in the world and golfer, nice shot by pro golfer ryo Ishikawa, incredible light, cliffs by the sea, perfect green fairway, human perspective, ambient light, 50mm, golf digest, top 100, fog"

(2) 前田健太の「歌舞伎のポーズ」

これに"A great photograph of kabuki painted actor in japan"というプロンプトで生成し、生成された画像をさらに入力しました。Lexicaにはあまり歌舞伎に関する良いプロンプトがなかったです。


お題と作品から、ここまでの画像を生成できることが驚きです。
この記事が気に入ったらサポートをしてみませんか?