【最新動向】Diffusionモデルが抱える課題とその解決策について(論文解説)

この論文は、最近の画像生成AIと動画生成AIの進歩に焦点を当てています。特に、拡散モデル(Diffusion Models)に基づく画像生成について詳しく説明しています。拡散モデルは、画像を段階的にノイズ化し、その後逆のプロセスを通じてクリアな画像を生成するというユニークなアプローチを採用しています。
文献情報
論文:Diffusion Based Image Generation Models: Issues and Their Solutions
著者:Tianyi Zhang、Zheng Wang、Jing Huang、Mohiuddin Muhammad Tasnim、Wei Shi
出版:arxiv,2023年8月25日
背景
この論文では、画像生成における拡散モデルの最新動向を検討しています。拡散モデルは、画像を徐々に劣化させることで、その逆プロセスとしての画像生成を実現します。このアプローチは、特に言語モデルと連携して、高品質な画像を生成する能力を持っています。しかし、これらのモデルは、複数のオブジェクトの正確な表現、珍しいまたは新しい概念の生成、生成された画像の品質改善という3つの主要な課題に直面しています。
課題

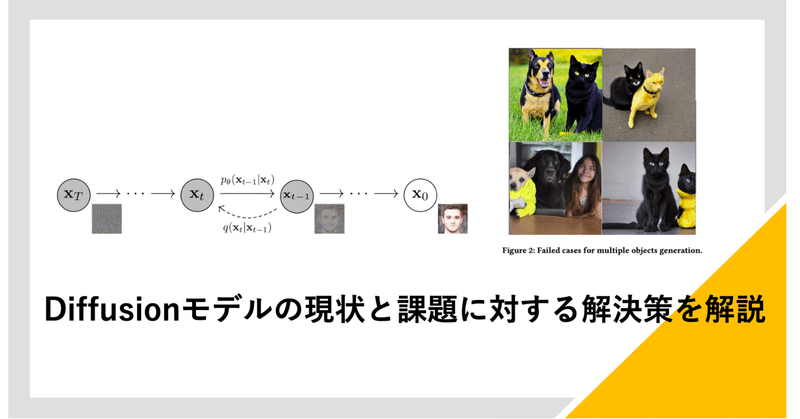
複数オブジェクトの生成: 現在のモデルは、複数のオブジェクトが含まれる画像を正確に描写することに苦労しています。特に、オブジェクトの属性や位置情報の捉え方に課題があります。
珍しいまたは未確認オブジェクトの生成: モデルとデータセットのサイズに依存すると、珍しいまたは新しく出現する概念を生成するのが難しいという問題があります。これは、トレーニング中にこれらの例に遭遇していないためです。
生成された画像の品質向上: 既存の研究は印象的なサンプルを示していますが、これらは多くの生成された画像から選ばれたものであり、広範なプロンプトの修正後に達成されることが多いです。実際的で詳細な画像を一貫して効率的に生成することは依然として困難です。
これらの課題に対する解決策として、さまざまな技術やアプローチが提案されています。これらには、テキストエンコーダの改善、専門家の混合、人間の好みに合わせた指示チューニング、サンプリング品質の向上、プロンプトの書き換えなどが含まれます。これらの技術は、拡散モデルの能力をさらに前進させ、画像生成タスクにおいて高品質な画像を生み出すための道を開いています。
論文のメインアイデア
この論文「Diffusion Based Image Generation Models」は、拡散モデルに基づく画像生成技術についての包括的な調査を提供しています。主な焦点は、現在の画像生成モデルが直面している問題と、これらの問題に対する様々な解決策を探ることにあります。
解決策と技術
これらの課題に対処するために、様々な技術や方法論が提案されています。これには、テキストエンコーダの改善、専門家の混合、人間の好みに合わせた指示チューニング、サンプリング品質の向上、自己注意ガイダンス、プロンプトの書き換えなどが含まれます。
テキストエンコーダの改善
画像生成モデルにおけるテキストエンコーダの性能向上は、画像の品質とリアリズムを高める鍵となります。様々なテキストエンコーダのサイズや種類が試されています。
モデルの混合
異なるステージの画像生成プロセスにおいて、異なるモデルを適用することで、画像の品質を向上させることができます。
指示チューニングと人間の好み
画像生成プロセスを人間の好みや品質基準に合わせて最適化するための方法として、指示チューニングが用いられています。
サンプリング品質の向上
サンプリングプロセスを改善することにより、より高品質な画像生成を実現することが可能です。
自己注意ガイダンス
自己注意メカニズムを利用して、生成プロセスをガイドし、より詳細な画像を生成する技術が研究されています。
プロンプトの書き換え
より詳細なプロンプトを使用することで、生成される画像の品質を向上させることができます。

実験結果のまとめ
多オブジェクト生成の改善
実験では、複数のオブジェクトを含む画像の生成が改善されました。これは、レイアウト情報(例えば、バウンディングボックスやセグメンテーションマップ)をモデルに組み込むことによって達成されました。
珍しいオブジェクトや未確認オブジェクトの生成
珍しいオブジェクトやこれまで訓練データに含まれなかった新しいコンセプトの生成にも進展が見られました。これは、検索エンジンを利用した方法や、特定の画像から生成するという新しいアプローチによるものです。
生成画像の質の向上
テキストエンコーダーの改善や、さまざまな専門家モデル(MOE)の利用、人間の好みに合わせた指示チューニングなど、様々な技術を駆使して、生成される画像の品質が向上しました。
細部までの再現性
セルフアテンションガイダンスやプロンプトの改善などにより、細部まで詳細に再現された高品質な画像の生成が可能になりました。
実用性の向上
これらの進展により、画像生成モデルは実際のアプリケーションでの使用においても、より高い品質と実用性を備えるようになりました。
今後の展望
画像生成AI、特に拡散モデルに基づく技術は、近年大きな進歩を遂げています。しかし、完璧な画像生成にはまだいくつかの課題があり、これらの課題の解決が今後の研究の主要な方向性となるでしょう。主な焦点は次のようになります。
位置情報の生成: 現在のモデルは、オブジェクトの正確な位置情報を生成することに苦労しています。これを改善するための研究が必要です。
コンセプトカスタマイゼーション: ユーザーが指定した特定のテーマや対象に基づいて画像を生成する能力を向上させる必要があります。
推論時間の短縮: GANと比較して、拡散モデルは推論時間が長い傾向にあります。これを短縮するための研究が求められています。
品質向上: 現在のモデルでは、フォトリアリスティックな画像を生成することが困難です。よりリアルで詳細な画像を生成するための方法の開発が必要です。
倫理的問題の考慮: 生成される内容が差別的、有害、または違法でないようにするためのガイドラインや安全策の開発が重要です。
注意点
拡散モデルに基づく画像生成技術はまだ発展途上であり、以下の点に注意する必要があります。
データセットの偏り: トレーニングデータに偏りがある場合、生成される画像にも偏りが生じる可能性があります。
品質のばらつき: 現在の技術では、一貫した高品質な画像を生成することが困難です。
倫理的問題: 特に人物画像の生成において、プライバシーや肖像権の問題に配慮する必要があります。
コストと時間: 高品質な画像生成モデルのトレーニングには多くの計算リソースと時間が必要です。
まとめ
画像生成AI、特に拡散モデルに基づく技術は、大きな可能性を秘めていますが、多くの課題も存在します。これらの課題に対処し、技術をさらに発展させることで、よりリアルで多様な画像生成が可能になるでしょう。今後も技術の進歩に注目し、倫理的な観点からの使用を念頭に置くことが重要です。
最後まで読んでいただきありがとうございました。
本記事がわかりやすい・良いなと思ったら、ぜひいいねとフォローしていただけると励みになります!
今後も画像・動画生成AIの最新研究について、論文解説していくのでお見逃しなく!
この記事が気に入ったらサポートをしてみませんか?