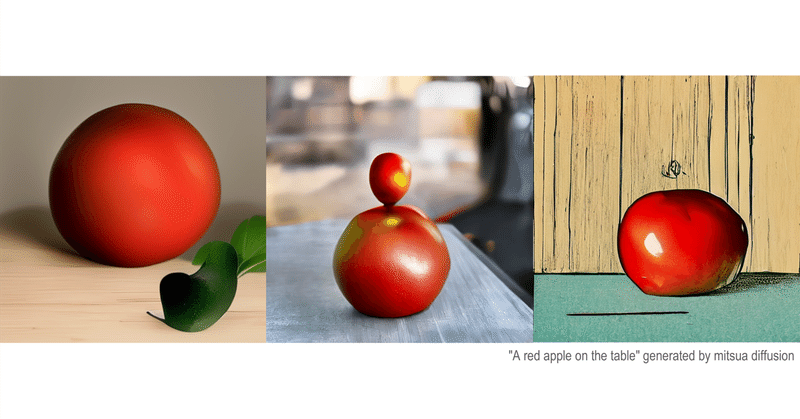
生成AI一問一答 (著作権からAI倫理まで)

はじめに
昨今の生成AIの話題を踏まえ、現状でよくある疑問などを一問一答の形で記録しておきます。いわゆる倫理的な話もありますので、ご参考程度にして頂けますと幸いです。※筆者はプログラムの専門家でも法律の専門家でもありません。(2023.09.19記載)
(A) 総論・技術
Q1. 生成AIとは何か
A. 生成を目的とするAIのこと
Generative Artificial Intelligenceの和訳。従来の予測などを主目的とするAIとは異なり「何かを生成すること」を目的としている。生成物は文章、画像、音楽、動画、コードなど多岐にわたる。近年話題になった理由は、その精度が飛躍的に向上し、実用化され、商用利用が可能となったため。その背景にはPC性能の向上、大量のデータ学習などがある。
Q2. 生成AIはどのようなものか
A. いわば「技術の”インスタント”化」
多くの人が自分の手元で「はやい、やすい、うまい」を享受できるようになった。インスタント麺やインスタントカメラのように、今まで触れ得なかった多くの技術が身近なものになったといえる。
Q3. 生成AIの有用性は何か
A. 多くの活用方法が見いだされている
最も社会に馴染む生成AIは大規模言語モデル(Large Language Model, LLM)である。自然言語系の生成AIであり、文章を学習し文章を提示する。OpenAI社のGPT (Generative Pretrained Transformer)を搭載したChatGPTは既に多くの活用が検討されている。有用性としては、文章の作成や要約、質問への回答、アイディア出しや提案、情報の検索や抽出などであり、プログラムのコード生成や計算なども可能となる。マーケティングサポートや学習補助などにも応用ができると思われ、実務的な労働時間の短縮や学習の効率化などが推測される。その他、画像生成AIや音楽生成AIなどは今までの技術の底上げや補完などが可能であり、より創造的な活動ができるかもしれない。
Q4. 生成AIの課題点は何か
A. 7つのリスク等、いくつかの課題点が存在する
生成AIの得意とする分野は「もっともらしい嘘」を生み出すことであり、生成される嘘は「ハルシネーション」と呼ばれる。検索結果の文献がすべて実在しない場合や、解説がすべて虚像の場合など、確認が難しいものもある。また、画像や動画生成によるディープフェイク作成も容易となっている。そして、これらの生成物がネットに氾濫すると、その生成物を更にAIが学習し、AI自体の性能が劣化する可能性も示唆されている。また、個人情報を学習してしまうと、その情報を抜き出すことも技術的に可能な場合がある。多くのフィルタリング機能が存在するものの、それを突破しようとする人がいるのも事実である。その他、著作権問題なども存在する(後述)。
現在以下の7つのリスクが想定されている。①機密情報の漏洩や個人情報の不適正な利用のリスク、②偽情報などが社会を不安定化・混乱させるリスク、③著作権侵害のリスク、④犯罪の巧妙化・容易化につながるリスク、⑤サイバー攻撃が巧妙化するリスク、⑥教育現場における生成AIの扱い、⑦失業者が増えるリスク。
Q5. 今後どうなるか
A. さらなる発展が予想される
今の生成AIは、単一機能を持つものが多いが、今後はそれらが複雑に組み合わさるマルチモーダルな生成AIが増えてくることが予想される。また、自ら学習し応用能力を擁する汎用人工知能(Artificial General Intelligence, AGI)の開発も加速すると考えられる。現在の特化型AIと異なり、より幅広い推論が可能となる。現在のAIは単一のタスクをこなすだけのシステムであり、まだ知性があるとは言えず、いわゆる「弱いAI」であるものの、今後はヒトのように知性らしきものを持つ「強いAI」も出てくるだろう。
(B) 法律:(1)学習
Q6.AIの学習とはなにか
A. 特定の行為を行うためにAIがデータを解析する過程
機械学習 (machine learning)は、データを解析し、その学習した内容を応用して十分な情報に基づく判断を下すことを目的とする。ディープラーニング (deep learning)は機械学習の一種であり、人の神経回路を模したニューラルネットワークと呼ばれる階層構造のアルゴリズムを使用する。現在の生成AIはディープラーニングの手法を応用し、大量の学習データにより性能を向上させている。今後、より少ないデータ量で高性能を発揮できるようになる可能性もあるが、現在その大量の学習データの収集方法や権利の所在が話題となっている。
Q7. 生成AIはリアルタイムで学習しているか
A. 多くの生成AIは過去に学習したプログラムをベースにしている
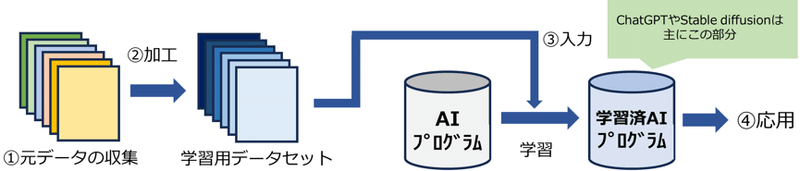
現在の生成AIの多くの学習済プログラム(モデル)は、①データを収集→②学習用データセットへ編集加工→③学習用プログラムへ入力解析(学習)→④学習済モデルの応用、という手順を経る。利用者の手元に来るのは学習済モデルであり、既に学習が終わっていることが殆どである。そのため、生成出力される結果は、そのモデルが学習された段階での情報であることに留意する必要がある。
ただし、ChatGPT (Interact GPT)などはフィードバックによる強化学習を行うReinforcement Learning from Human Feedback (RLHF)を利用しており常に最適化を図っている。また、ChatGPT利用時に入力した内容は学習用データとして収集される (オプトアウト設定あり)。一部のAIではリアルタイムで情報を解析するものもあるが、現在の生成AIにそのような性質は殆どなく、SNSなどに画像を投稿したからといって、すぐにAIが学習するわけではない。
Googleの検索エンジンと生成AIを組み合わせたSGE(Search Generative Experience)は、リアルタイムの情報検索が可能となるため、提示された結果には古いものから新しいものまで含まれるが、あくまで検索機能の拡張である。
Q8.学習用のデータ収集はどのように行うか
A. ネット上から大量のデータを収集することが多い
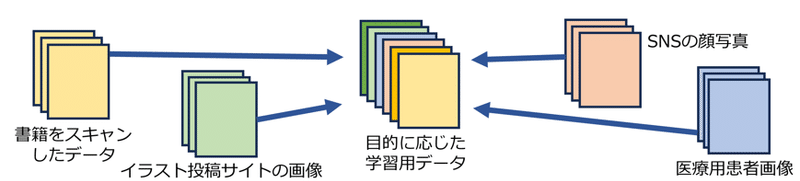
生成AIは、その生成物と同質のものを学習する。文章なら、インターネットの多くのサイト上の文章や書籍の内容。画像なら、インターネットにある多くの画像などである。当然ながら、この中には著作物が含まれる。また、画像における顔写真や医療用写真、文章における個人情報なども含まれ、画像の中には違法なものも含まれている指摘がある。基本的には既にまとめられたものや、インターネット上のデータを自動収集するプログラムで集めていく。ほぼ無差別にネット上の画像や文章を大量に収集している。
特に生成したいものがあれば、それと同質のものを多めに学習させることとなる。一番分かりやすいのは画像生成AIであるが、アニメ調の絵を生成したければ、アニメの絵を入力すればよく、グラビア風の画像を生成したければグラビアモデルの写真を入力すればよい。逆に言えば、生成AIがグラビアモデルのような綺麗な画像を生成できるということは、同質の実際の写真を学習しているということである。
Q9.学習用データセットの加工とは何か
A. AIがデータを理解できるように注釈をつける作業が必要
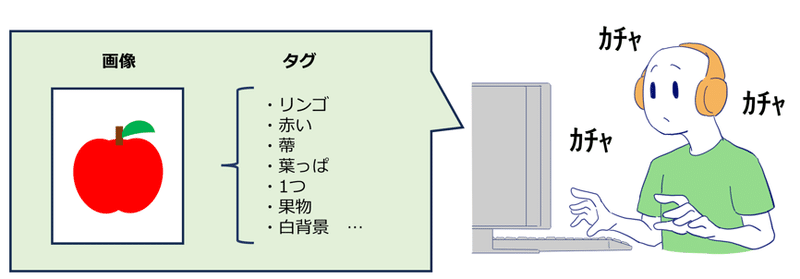
AIに入力する画像や文章などのデータは、学習生成の際にシステム自体が理解できるように注釈(アノテーション)をつける作業を行う必要がある。例えば、今の画像生成AIはネットの画像を勝手に学習してそのまま進化しているわけではなく、集めてきた画像に手作業でタグをつけ、下手な絵や違法な画像などの学習に適さないものをスコアリングなどで選別除外し、機械が理解できる形に加工してから、AIに入力する(そのため下手な絵をネットに流してもAIが誤って学習して下手な絵を描くようになるわけではない)。画像単体を入力してもAIは理解できることができず、1枚の画像に何が描かれているのかについて、様々なタグをつけることでAIは画像と言葉を連結して学習できるようになる。
このアノテーションは手作業で行われることも多く、その工程は途方もないものであるが、アフリカなどでも外注している企業があり、一つの産業として成り立っている。ChatGPTにおいて不適切コンテンツが生成されないようにするためのラベリング作業では、担当者の精神的負担が問題になったこともある。
Q10.AI学習時に利用した著作物の著作権はどうなるか
A. 原則として学習したサーバのある国の法律が適用される
学習において著作物を利用する場合、学習用データセット作成時に複製や翻案の過程が発生し、著作権法が関与する。この場合、原則として学習(=著作物を利用)した国の法律に従うと考えられる。現在の多くの生成AIは海外製であり、日本の法律だけで語ることができるものは少ない。現状のAIの実態としては「日本でAI開発のための学習を行っていれば合法なのだが、海外で学習しているため海外の法律に従う」というのが正確であろう。
Q11.AI学習時の日本の著作権法はどうなっているか
A. 特定条件下でのみ無許諾の著作物利用が可能となる
日本の著作権法では、第30条の4において、「情報解析の用の供する」時は「①当該著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合」および「②当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害しない場合」に限り、無許諾利用が可能である。
Q12.「①当該著作物に表現された思想又は感情を享受」とはどういう場合か
A. 情報解析に用いた著作物が”そっくりそのまま”鑑賞できる場合
「当該著作物に表現された思想又は感情を享受」とは、学習した”著作物そのもの”が提示された場合のみが該当すると解釈され、雰囲気が似ている程度では該当しない。画風や絵柄に著作権が無いように、誰かの絵に似ているものを出力してもこの部分には該当しない、というのが一般的な解釈となっている。
Q13.「②著作権者の利益を不当に害しない場合」とはどういう場合か
A. 市販物の売れ行きを低下させず、将来の販路を阻害しない場合
この場合の”当該著作物”は条文通りの解釈であれば、学習元の著作物にも及ぶと捉えられるが、過去の答弁においては「学習用データセット」という塊を指しており、データセットの元になった個々の著作物にまで言及している公的解釈は未だ無い(2023年11月15日現在)。そのため現状明確に指摘できる範囲として「AI開発者またはデータセット販売者の著作権を害しない場合」という解釈が一般的である。また、「著作権者の利益を不当に害する」とは第35条の1にある同様の但書の解釈によれば、「著作権者の著作物利用市場と衝突するかどうかであり、現実に市販物の売れ行きが低下したり、将来における著作物の潜在的販路を阻害したりするかどうか」とされている。(参照:データベース使用差止等請求事件中間判決:平成12年(ワ)第9426号:https://www.softic.or.jp/YWG/reports/dbrelated.html)(参照:翼システム事件:平成8年(ワ)第10047号損害賠償等請求事件))
一方、この部分に関して「生成AIによる生成物が、元データの著作者の将来的な販路を阻害することがあり得るのではないか」という意見がある。2023年8月、日本書籍出版協会などの4団体は「同条のただし書きでは『著作権者の利益を不当に害する』場合は学習利用できないとされていますが、その解釈は明確ではなく」「ただし書きの解釈を明確にし、著作権法改正の必要性を見極める必要があります」と表明している。

Q14.著作物の軽微利用はどうなっているか
A. 条件を満たした場合は無許諾で利用可能 (著作権法第47条の5)
著作権法30 条とともに改正された条項。享受目的であっても、条件を満たした軽微利用であれば著作権侵害にあたらない旨が規定されている。著作物の利用は今まで検索エンジンによるサムネイルやスニペット 切り抜き 表示などが認められていたが、更に範囲が拡大し、アップロードされた情報だけでなく広く公衆に提供提示された著作物も含まれることとなった。想定されている状況としては「論文の剽窃の有無を判断するAI 」を開発する時、既存データと比較して剽窃された文献の該当部分 著作物 を提示する、などである。この場合も権利者の利益を不当に害する場合は利用できない。
Q15.AI学習時のEUの著作権法はどうなっているか
A. 商用利用目的の学習拒否が可能と明記されている
EU DSM著作権指令に従う。Text data mining(TDM)において、研究機関等による科学研究目的では自由とされるが、営利目的の場合は権利者がオプトアウト可としている。ただし、この場合のオプトアウトは「機械読み取り可能」な場合に限る。現状、機械読み取り可能な形でのオプトアウトはrobots.txt程度しかなく、画像や文章そのものの埋込メタデータは未だ普及していない (画像に埋め込むタイプのDonottrainタグはAdobeが開発している)。また「研究目的で開発したAIを営利目的で”転用”した場合」の判断は難しい。さらに、今後はAIに特化した法令であるEU AI actが制定される予定となっている。
Q16.AI学習時の米国の著作権法はどうなっているか
A. 明確な基準はなく合法とされるかはケースバイケースである
フェアユースに従う。フェアユースは「批評、解説、ニュース報道、教授、研究、調査等を目的とする」場合に認定される。ただし、フェアユースに認定されるかはケースバイケースで一定基準はなく、総合判断となる。AIの学習への利用はフェアユースにあたる可能性はあるものの、著作物の潜在的市場への影響や商用利用などの観点からも判断されるので、判例次第と言える。著作物の利用が変容的(transformative)であれば認定される可能性は高いが、ChatGPTが著作物の一部をそのまま出すことも報告されており、ある著作本が学習されているという点において作家によって訴訟が起こされている。
Q17.個人情報や機密情報はどういう扱いになるか
A. 機密情報の漏洩や個人情報不適正な利用リスクが指摘されている
2023年8 月、個人情報保護委員会は生成AI サービス利用の事業者や行政機関に向けて、個人情報保護法に基づく注意喚起を行った。要配慮個人情報などを生成AI 学習に利用する場合の周知や第三者提供に際する同意などである。ChatGPT が入力内容を学習用に取得するシステムになっていることも重要となり、みだりに個人情報を入力することには注意を要する。営業秘密や機密情報を扱う場合は、不正競争防止法や機密保持契約などが関与する。
また、顔認証などのAI 技術において近年、顔写真のデータセットの非公開なども相次いでいる。EU AI act の中では、リアルタイム生体認証を行うAI を制限しており、学習段階におけるプライバシーや個人情報の観点から問題になる論点も存在する。
ClearviewAIという顔認識AI は、ネットの顔写真を大量に学習したAI であったが、学習は合法であると判断された一方で、プライバシーの観点から違法判決が出ている。
Q18.オプトイン学習とは何か
A. 学習が許諾されたデータのみでAIを学習させること
無差別に学習するのではなく、学習用のデータを提供してもらう形となる。理論上、誰の著作権も侵害しないため、最も安心して使える生成AIである。ただし課題点として、十分なデータ量が確保しにくく、性能を維持できない点がある。データ量が確保できない場合、学習内容に偏重が生じ、出力結果に類似性が増したり、偏ったりする可能性がある。また、契約時にAI学習への許諾を強制される場合、独占や寡占などを引き起こす可能性が示唆されている。今後、AIの性能が向上した場合、学習量が少なくても解決できる可能性はある。
具体例:
・mitsua diffusion:パブリックドメイン+オプトイン学習のみでUNET部分を学習させたモデル。OpenCLIPを利用しているものの、現状実用可能なオプトインモデルである。株式会社アブストラクトエンジンが開発を行っており、国産の画像生成AIである(無料)。
その他:自社が権利を有するデータで学習
・Adobe firefly:Adobe社が自身で権利を有するAdobe stockから学習させた画像生成AI。Adobe stockには版権絵があるものの、そのようなエディトリアルライセンスのものは除外されていると説明されている。ただしタグのない画像やAI生成物が混ざりこんでいると言われている。しかし、他の画像生成AIと異なり、版権絵が出る可能性は極めて低い。また、Adobeは学習利用されたクリエイターへの報酬還元システムも検討している。
・CM3leon:Shutter stockが権利を有するデータを用いてMeta社が画像生成も可能なAIを開発。CM3leon自体は拡散モデルではなく、画像およびテキスト生成が可能なマルチモーダルAIである。Shutter stockにも版権画像などが混ざりこんでおり、適切に除外できているかは不明。
Q19.オプトアウト学習とは何か
A. 申請によって学習させたくないデータを除外する方法
無差別に収集した学習用のデータから、学習除外希望を募り、AIに入力する前に除外する方法。学習済みモデルからの除外は基本的に不可能だが、新しく作るAIには適応可能である。先述のEUのDSM著作権指令以外にも、多くの企業が既にオプトアウトを整備していることがある。重要な点として、学習データが開示されなければオプトアウト不可能だが、多くは開示されていない。
具体例:
・Stability AI:Stable diffusion v.3の開発時にオプトアウトを実施。現在Spawningという団体を通じて50億枚もの画像データ(LAION5B)から14億枚ほどが除外されたとしている。しかし、SDv3は未だリリースされず、SDXLがリリースされ、SDXLに関しては学習元のデータを開示していない。
・ChatGPT:入力内容をモデルの学習などに利用することを明示しているが、設定の変更やオプトアウトフォームへの入力などで、入力内容を学習に利用させないようにする処置が可能。
・GPTbot:OpenAIがネット上のデータを収集するWebクローラーであるGPTbotをブロックする方法をOpenAI社自身が公開している。robots.txtに設定を追加することで、その指示を遵守するとしている (技術的には無視することも可能)。
・利用規約におけるAI学習禁止:2023年8月New York Timesが利用規約においてAIによる学習を禁止した。その他、Pixivなども利用規約において著作権者の不利益となる情報解析を禁止しており、また、個別にAI学習禁止を明示しているクリエイターも多く見受けられる。現在、この意思表示は少なくとも日本においては法的拘束力を持たないと判断されているが、NYTはOpenAIへの訴訟を検討しているとされる。
Q20. AI学習における対価請求とは何か
A. 著作物等がAI学習に利用された時の対価還元の仕組み
著作権者側から学習を制限できない場合なども含め、AI学習使用時の対価を請求する意見もある。ただし、あまりにも多くのデータを学習しているが故に、全者に対価還元することはほぼ不可能であり、企業単位で契約する場合、セミプロやアマチュアレベルの創作者まではカバーすることができない。Adobe fireflyやShutterstockは学習元データの権利者への還元システムを検討し実際に提示している。
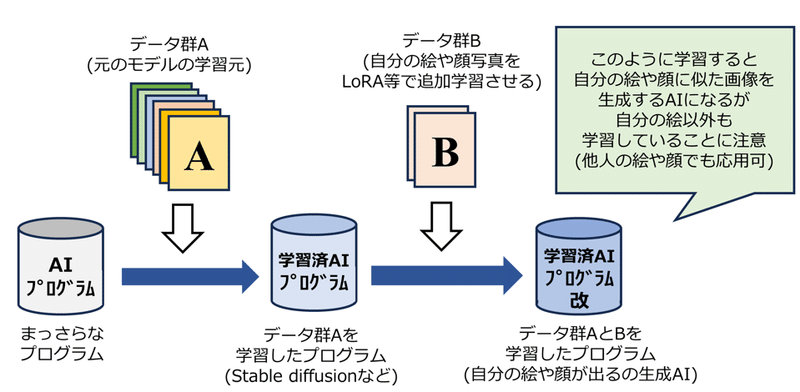
Q21. 自分の絵だけを学習させれば問題ないのか
A.自分のデータだけで生成AIを作ることは基本的に不可能である
自身のイラストや顔写真を学習させたとしても、あくまでも追加学習であり、ベースのモデルに対する生成物のチューニングにすぎない。そのため、元のモデルがある以上、学習に利用されたデータは「元のモデルの学習データ+自分で入力したデータ」となる。現在の生成AIは大量のデータを学習することでそのクオリティを維持しており、個人の少数のデータでそのクオリティを維持することは出来ない。最終生成物を自身の絵柄や自身の容貌に寄せることが可能な程度である。他人の絵を追加学習するよりはリスクが低いものの、全く問題がなくなるわけではなく、学習段階や生成物の懸念は依然として存在する。
Q22. データセット内容の開示とは何か
A. AIが学習した著作物などの情報を開示すること
何を学習したAIなのか、という点に関しては多くの人が疑問に持つこともあるが、実際は内容が公開されていないことが殆どである。ただし、多くの生成AIはネット上のほぼ全ての範囲が学習対象であると見るべきである。その中には違法アップロードが行われた海賊版サイトや転載サイトも含まれ、FacebookやInstagramなどのSNSの記事内容や写真も含まれる。実際に依拠性の判断や、対価還元の話が出てきた場合、何を学習したAIなのかというのは重要になる。また、EUのAI条例や日本においても、学習内容のサマリなどの開示が要求される方針となるようである。一方、従来のAI開発における学習データセットの開示は自社のデータなどを活用した機密情報なども多分に含まれるため、一部企業では開示に対する拒否感も強い。
(B) 法律:(2)モデル
Q23. モデルとは何か
A. AIのプログラムのこと
AIの学習プログラムはモデルと呼ばれ(学習後の計算式/計算方法のこと)、特にローカル環境で動作する画像生成AIに関してはオープンソースとして公開されたStable diffusionをベースとして極めて多くの学習済みモデルが存在する。そのモデルは、各々に特徴があり、アニメ調のイラストを生成しやすいものや、実写系の画像を生成しやすいものなど多岐にわたる。ベースのモデルに、様々な画像を追加学習しており、追加学習用のデータセットも多く配布され、かつ、モデル同士を混ぜ合わせることも可能となっている(マージ)。この時に利用される追加学習用のデータセットには、Pixivのランキング上位画像を集めたものや、グラビア画像を集めたもの、FacebookやInstagramの写真を集めたものなどがネットで配布されている。AIグラビアを生成するためには、実在のグラビアの水着や裸の写真を大量に学習する必要があるということである。
Q24. 違法モデル問題とは何か
A. 不正アクセスによって流出したモデルがネットに蔓延したこと
2022年10月、画像生成AIサービスであるNovelAI(NAI)に関するソースコードが不正アクセスによって流出する騒動が起きた。NAIリークモデルと知られるこのデータは、その後ネット上に拡散し、現在多数のモデルに混ぜ合わされた。NAI開発元のAnlatan社は、しばらくリークモデルに対して言及していなかったが(公式に言及されていないから使って良いのだろうという認識の人もいた)、2023年6月に突然、NAI公式は「流出したモデルや改変モデルの利用に関して、法的措置を取る可能性がある」明言した。生成画像からリークモデルの推定は困難であり、第3者から提出されたAIによる生成画像が、実際に違法モデルを利用していないかどうかの確認をどうするかなど別の課題が生まれた。
一部の人々は、この問題を重く受け止め、極力NAIリークモデルが含まれないモデルを生み出そうとしている人たちもいる。
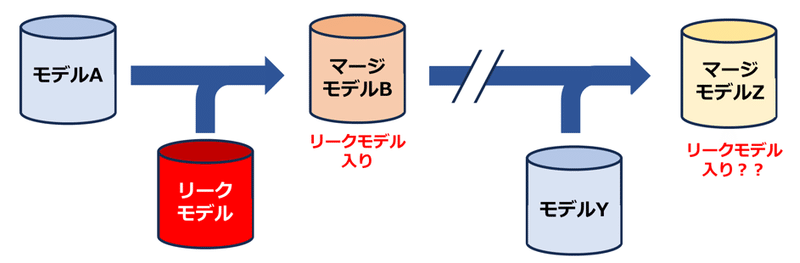
Q25. モデルのライセンス問題とは何か
A. モデルのライセンス継承などが行われていない可能性があること
多くの画像生成AIモデルは、専用プラットフォームなどで配布されているが、個々にライセンス/利用規約が設定されていることが多い。その中には、商用不可のモデルや使用モデル明示(クレジット表記)を義務づけるモデルなども存在している。また、通常はモデル同士をマージさせて新しいモデルを作った場合、元のモデルのライセンスを引き継ぐことになるが、このライセンス継承がきちんと守られていないこともある。
(B) 法律:(3)生成物
Q26. AI生成物に著作権はあるか
A. 著作権が認められる場合と認められない場合がある
AIが生成したもの自体に著作権は発生しないとされる。ただし、日本の考え方として、ツールとしてAIを使用し、その生成過程において創作性が認められれば著作権が発生し得る。創作性は、プロンプトの長さや生成試行回数、加筆などが関与すると思われるが明確な基準は未だない。米国においては、AI生成自体に著作権は存在しないという判例が出ている。米国著作権局は624回プロンプトを入力し、Adobephotoshopで解像度などを修正した作品に対しても著作権を認めない方針とした。一方、イラスト部分をMidjourneyで出力した漫画”Zarya Of the Dawn”の件においては、加筆や構成部分などに限定的な著作権が認められている。いくつかの事例に対応している米国においても意見は様々であり、米国著作権庁は、2023年8月30日から11月15日まで、AIと著作権問題に関するパブリックコメントを募集することとした。
Q27. AI生成物が著作権侵害になる場合はどのような場合か
A. 類似性があり、かつ依拠性が認められた場合
まず類似性を考慮し、既存著作物との類似性を認めれば、次に依拠性を判断する。従来通りの対応となるが、生成AIの場合、依拠性の判断が定まっていない。生成者が知らない画像であった場合でも、モデルのデータセットの中にその画像が入っていた場合、それでも”依拠性あり”と判断していいのではないか、という意見は存在する。そもそも、データセット内容をどのように確認するのか、という問題も付随する。
Q28. 生成物が誰かに似ている場合はどうなるか
A. 明確に類似性を持たせた場合はパブリシティ権などが関与する
LoRAなどを用いて、明確な意図をもって有名人や誰かに寄せた画像を出力する場合、当該人物の許諾が無い場合はパブリシティ権や肖像権などが関与すると考えられる。ディープフェイクの問題が最重要と考えられる点である。
Q29. 誰かの声に似せた生成物はどうなるか
A. 声そのものを保護することは現状では難しい
声そのものに著作権はない。実演には著作隣接権が適応されうるが、似ているだけでは侵害になりえない。生成AIを利用して、有名人の声で別の人の歌を歌わせる動画などがネット上で広がっている。特定の声優などに似せたボイスはその生成物においては、パブリシティ権などが関連するかもしれないとされる。ただし、この点においても明確な基準は存在しない。また、技術の進歩によって極めて短い音声からも類似合成音声が生成可能となり、フェイク音声としての危険性も指摘されている。多くの声優が所属する日本俳優連合は、生成AIに関する声明の中で、声の肖像権などの「声」の保護を求めている。
Q30. AI生成物の商標権はどうなるか
A. 類似した商標が類似した用途で使用されれば侵害となりうる
生成物が商標権を侵害する場合、依拠性は関係なく商用および使用範囲における類似性のみで判断される。また、過失も推定されており、著作権侵害よりも訴訟リスクが高いと判断される。一方、創作性などは考慮されないため、AI生成物を商標登録することは可能と考えられている。
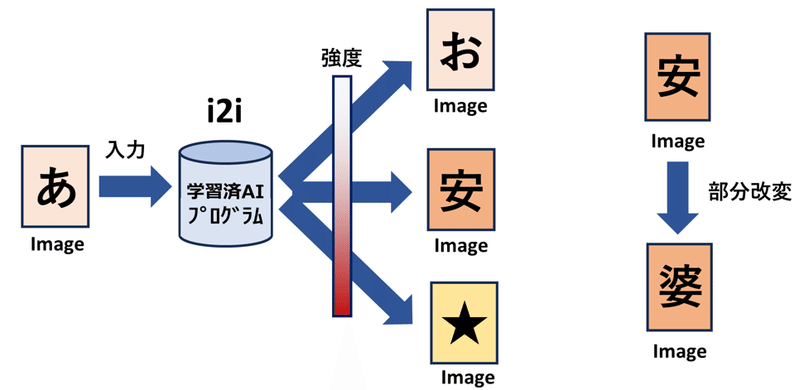
Q31. i2i (image to image) は著作権侵害か
A. 通常の生成AIと同様の可能性はあるが、入力行為の解釈も重要
AIに特定の画像を入力して、新しい画像を生成する方法。通常の文章から画像を生成するt2i (text to image)とは違い、画像から画像を生成するためi2iと呼ばれる。類似性の高い画像が出やすく、依拠性が明確なので、著作権侵害のリスクが高い。ただし、拡散モデルにおいてノイズ除去の強度を上げれば、ほぼ別物の画像が生成される。部分的に改変することも可能。また、i2iの場合は画像を入力することがそもそも「情報解析」にあたるかどうか、享受目的にあたるかどうか、も議論がある。
Q32. LoRAは著作権侵害か
A. 類似性や依拠性などは通常の生成AIと同様である
画像生成AIにおいて、追加学習によってチューニングする手法の1つ。追加学習にはLoRAの他にもLyCORIS, Hypernetwork, Textual inversionなどがある。特定の人物の絵柄や画風に似せることができる他、特定の人物の顔写真に似せることが可能。追加学習には特定のキャラや人物、同一作家の画像が、数十枚でもあれば可能となる(もっと少ない数でできることもある)。絵柄や画風に似ているだけでは著作権侵害にはならないが、その画風を模倣するために、模倣された著作者の画像が、AIチューニングに利用されていた場合、著作権者の権利を不当に害するのではないかという意見もある。
実際、某ゲームの広告において、とある作家と類似した画像が掲示され、多くの人がその作家がゲームのために絵を提供したのだと思った。しかしながら、その作家は関係がないと表明し、生成AIによるイラストではないかといわれている。この場合、現在の法解釈では著作権侵害も不正競争防止法の適応も難しそうだという意見が多かった。※本件に関しては広告企業が何のコメントも出していないため、詳細は不明である (2023年9月現在)。
(B) 法律: (4) 今後
Q33. EU AI act (EU AI 規制法案 はどのようなものか
A. AI をリスク別に分けて制限や規則を与える法案
AIに対して2023 年6 月にEU が採択した法令。生成AI が出てくる前から進められていた。詳細は現在詰めているところであるが、域外適用があるため、EU 領域へサービスを提供する場合、EU 外の企業なども従う必要がある。そのため、日本など他の国にも、GDPR の時と同様にEU 基準になっていくと考えられる。主題は個人情報やプライバシーの保護であるが、リスク別にAI を分類しており、生成AI においては透明性の確保が謳われ、学習時に利用した著作物の詳細なサマリ提出と公開を求めている。
Q34. 米国の動きはどのようなものか
A.一定の制限を誓約させつつ、開発の援助を行う方針
2023年7月、大手AI開発事業者7社(OpenAI、Google、Microsoft、Meta、Amazon、Anthropic、Inflection)による自主誓約が取得された。AI自体の安全性やセキュリティ維持の他、AI生成物であることが分かるようなメカニズムの開発実装や、有害なバイアスや差別の回避などを提言している。また、同年9月には更に8社(Adobe, IBM, Nvidia, Palantir, StabilityAI, Salesforce, ScaleAI、Cohere)がAIのリスク管理への自主的な取り組みに参画すると発表した。
Q35. 日本の動きはどのようなものか
A. 独自誘致などを進めているが、世界の規制に同調しつつある
2023年9月、AI戦略会議において、国内事業者向けガイドライン骨子案が提出され、透明性の確保と、不適切利用の抑止を求めるとしている。学習データの開示なども提案された。また、「AI時代の知的財産権検討会」の開催を決定した。
Q36. 各権利団体の声明はどのようなものか
A.世界中の権利者団体の多くが生成AIに懸念を示している
現在の生成AIに関する著作物の利用態様において、疑問視する声が多く、各権利団体が声明を出している。団体の例を以下に示す。多くの声明文の中では、偽情報拡散や個人情報漏洩の危険性、著作権や肖像権等の権利侵害の可能性、対価還元の必要性などを指摘している。(以下、生成AIに声明を出した主な権利団体(一部))
・日本芸能従事者協会:2023年5月
・日本俳優連合:2023年5月
・日本音楽作家団体協議会:2023年6月
・著作権協会国際連合(CISAC):2023年7月
・Graphic Artists Guild等24団体:2023年7月
・全米作家協会(The Authors Guild):2023年7月
・全米映画俳優組合(SAG-AFTRA):2023年7月
・日本音楽著作権協会(JASRAC):2023年7月
・欧米メディア等9団体(AFP通信等):2023年8月
・日本美術著作権連合:2023年8月
・日本雑誌協会、日本書籍出版協会、日本写真著作権協会、日本新聞協会:2023年8月
・世界ニュース発行者協会(WAN-IFRA)等26団体:2023年9月
(C) モラルや倫理
Q37. 今の生成AIは何が問題なのか (ELSIとは何か)
A.著作物などの学習元の利用態様が問題になっている
生成AIは今までにない技術の応用であり、過去の事例と1対1でとらえることはできない新しい課題を抱えている。その中の話題の一つが「ネット上のデータや取り込んだ書籍の内容を著作者に許諾なく学習させ、その性能を維持しているという問題」である。今までに述べたように、AI開発のための機械学習は、オプトアウトなどの道が整備されつつあるものの、多くは著作者の意向は未だ十分に反映されていない。その中には、AI学習に使われたくないという意見や、そのように開発されたAIを使いたくないという意見もある。現状では、ある著作者が機械学習や生成AIへの著作物の利用を行わないように求めても、その意見を聞き入れる必要性や意義は乏しいと判断されている。しかしながら、その態度は倫理的な問題を引き起こしている。一部事例においては、フェアユースに違反するのではないか、利用規約を無視しているのではないかと指摘され、訴訟になっている。
※AI倫理:ELSI
ELSI(エルシー)とは倫理的(Ethical)・法的(Legal)・社会的(Social)課題(Issue)の頭文字を合わせたものであり、新規科学技術を研究開発し、社会実装する際に生じる技術的課題以外のあらゆる課題を指す。もともとは生命科学の倫理問題として発展した。ELSA(Aspect)やRRI(責任ある研究・イノベーション)とも呼ばれる。従来のAIのELSIとして「①学習(教師)データの収集や加工は適正に行われたか」「②アルゴリズムは正確で公正なものであるか」「③製品やサービスのアウトプットや使い方は適正か」というものが既に指摘されており、今後は生成AI特有の問題も考慮する必要がある。
Q38. 生成AIに対する具体的な懸念の声はどのようなものか
A.例えば日本雑誌協会など4協会の声明は以下の通りである(抜粋)
・学習利用の価値が著作権者に還元されないまま大量のコンテンツが生成されることで、創作機会が失われ、経済的にも著作活動が困難になる。
・海賊版をはじめとする違法コンテンツを利用した、非倫理的AI の開発・生成が行われる。
・元の作品への依拠性・類似性が高い著作権侵害コンテンツが生成・拡散される。AI利用者自身が意図せず権利侵害という違法行為を行う可能性がある。
・第30 条の4ただし書きの解釈を明確にし、著作権法改正の必要性を見極める必要がある。
・生成物に権利侵害リスクがあるままでは、安心して生成AIを活用できない。
・生成AIが文化の発展を阻害しないよう、技術の進化に合わせた著作権保護策が必要。
Q39. 生成AIの根本的問題はどこにあるのか
A. 学習元と生成物の関係性が重要である
そのような倫理的な問題に至る過程において、個々人による捉え方に差異があることは重要である。つまり、無断で著作物を学習していることに対して「法律上問題ないなら大丈夫」という人々と「現在の法律で問題はないとしても、倫理的に問題なのではないか」という人々である。また、懐疑的な意見自体にもグラデーションがあり、「オプトインAIしか受け入れられない」という人や「オプトアウトが整備されているなら受け入れられる」など、許容できる範囲も程度の差が存在する。
このような差異が生まれる理由の一つとして「学習元のデータ」と「生成物」の関連性をどのように捉えるかという点が重要かもしれない。ここでは「変容的(transformative)」という単語を用いて、「変容的利用の程度」がAIへの心理的ハードルの程度につながるという仮説を考える。
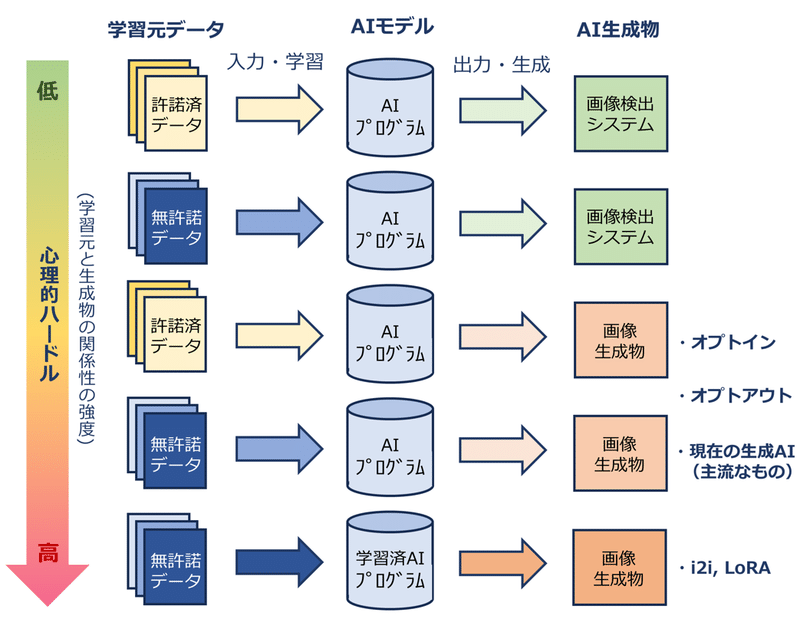
Q40. 生成AIに対する心理的ハードルは、なぜ人によって違うのか
A.「変容的利用」のグラデーションが関与しているかもしれない
ここでの「変容」という単語は「学習元と生成物の関係性がどのように変容しているか」という点を論点とする。例えば、現在問題になっている無許諾の著作物を大量に含んだデータセットを用いて、違法画像検出AIを作成したとする。このように作られたAIへの心理的ハードルは、そこまで高くないと予想され、無許諾学習自体が悪いわけではないと判断できる。また、現在の主流のような画像生成AIを完全オプトインの許諾学習で行ったとする。こちらもまた心理的ハードルは低いと考えられ、画像生成AI自体が悪いわけではないと判断できる。これらの想定から、「学習」や「生成AI」そのものが原因ではなく、これらの組み合わせが心理的ハードルを引き起こすものと考えられる。そして、このハードルには高低のグラデーションがあり、どこまでなら許容できるのかという点も個々人によって差があるのである。
また、その関係性において、学習元の影響力が強いことも挙げられる。生成AIがある生成物を生み出す際、ある特定の方向性を持っている場合は、それらに特化した学習内容を含んでいると考えられる。同じ学習アルゴリズムでも入力するデータセットの内容によって生成物は変化することとなる。実際、多くの著作物を学習しているStable diffusionやMidjourneyなどは綺麗な画像を生み出す画像生成AIであるが、パブリックドメインおよびオプトインの画像のみでU-netをスクラッチしているmitsuadiffusionは、前述の生成AIのような画像を生み出すことは出来ず、特に版権キャラクターのようなものは一切生み出されない。学習元を絞ったAdobefireflyでもアニメ風キャラの生成は苦手である。
生成物において署名やロゴのようなものが混ざることがある。通常はnegative promptで出ないように指示することが多いものの、著作物を学習しているという事実でもある。実際、Getty imagesのウォーターマークと類似のロゴが出力されることが確認され、Getty imagesはStability AI社に対して規約違反等の訴訟を起こしている。
これらの事象は正に「学習元のデータと生成物の深い関係性」を示唆するものであり、このような事象が観測される限り、この関係性を無視することは難しいと考えられる。
Q41. クリーンなAIとは何か
A.一般的に倫理的・法律的・社会的課題をクリアしたAI
クリーンなAIに定義はないが、一般的に倫理的法律的社会的課題をクリアしたものと考えられる。現在の生成AIは学習元や生成物の権利の所在が不明瞭となっており、直接的に商用に転用することが難しいと判断されている。そのため、これらの課題がクリアされた生成AIは商用にも応用しやすく、提供する側のリスクも低く、利用者の心理的ハードルも低い。どの程度クリアすれば大丈夫なのかどうかは、心理的ハードルの基準次第であり、ここも個々人によって幅がある。
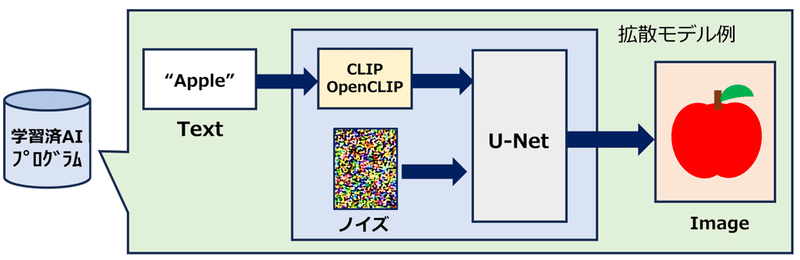
たとえば、Stable diffusionは、生成のための学習(U-Net部分)に用いられる画像群(LAION)の他に、文字と画像を結びつけるためのCLIP/OpenCLIPと呼ばれる別のシステム部分もLAIONなどの多量の画像を学習している。このシステムは画像識別技術の応用であり、生成物への直接的な視覚影響は乏しいと考えられるが、無許諾の著作物を利用していることは事実であり、U-Net分がクリアされていてもCLIP部分でクリーンとみなさないという意見もある。このU-Net部分をクリーンな画像だけでフルスクラッチしたものがmitsuadiffusionである。
クリーンを売りにしている生成AI開発も存在している。Adobe fireflyは学習元の画像にすべて自社が権利を有するAdobe stockを利用していると謳っており、特定のキャラクターなどが出ないことなどをセールスポイントとしている。また、Adobeは学習利用されたクリエイターへの報酬還元システムも検討している。Meta社のCM3leonもShutter stockの権利を利用している。国産のmitsuadiffusionはパブリックドメインとオプトイン画像のみでUNETを学習している。アマナイメージズは倫理的にクリアなAI用学習データに需要があるとしてQlean(キュリン)というサービスを開始した。権利クリアランス対応のAI学習用ビジュアルデータセット開発サービスであり、AI倫理を重要視している。
Q42.データセットの倫理性とは
A. データセットの中身の倫理性や違法性も問われている
データセットの中に含まれているデータの中には違法画像も含まれている可能性が指摘されている。実際、Stable diffusionの学習元となったLAION-5Bというデータ群の中には、不正な画像も含まれていることが指摘されている。これらの画像も含めて学習した生成AIは倫理的にどうなのか、という論点がある。
Stablediffusionの学習元であるデータセットLAIONの中に医療用の顔写真が含まれていることが判明した時、当事者本人であるLapine氏がLAIONに削除を要請したところ、LAION側は削除に応じなかったというエピソードもある。(LAIONは画像URLとアノテーションのデータセットであり画像は保持していないため)
ちなみに、日本国内においては「違法にアップロードされたデータ」を学習しても、著作権法としては情報解析のためであれば問題ないとされている(違法にアップロードを行うことはダメ)。データ自体に違法合法の色がついていない以上、データ収集時に除外することは難しいという点ではその通りであるが、学習元と生成物の関係性が強い生成AIにおいては懸念点となる。
Q43. 商用利用に際し心理的ハードルは存在するか
A. 商用に利用する場合に心理的ハードルは増大する可能性がある
多くの生成AIは商用利用に活用することが想定され、実際にサービスの提供がベンチャー企業などからも行われている。この際に、サービス提供者側のハードルとしては知財関連の訴訟リスクなどが存在し、実際に海外では一部で訴訟になっている。現在、積極的にサービスを提供したり、生成物を商用利用している人々はリスクを承知で対策を行っているか、またはリスクを知らされていないかのいずれかであると考えられる。
多くの生成系AIの利用規約では、生成物のトラブルは利用者にあり、サービス提供者には無いと記載されていることが多い。しかし、AdobeやMicrosoftなどの大手企業は生成物のトラブルに関する訴訟費用などの負担を掲げ、責任の所在をセールスポイントにする流れも生まれつつある。
一方、倫理面の一つとして「無許諾の著作物などで成立する生成AIを自由に商用利用すること」に関しても心理的なハードルが存在する。実際、フェアユースの考え方でも商用利用していると認定可能性が下がるといわれる。EUの著作権に関する法令で「商用利用のAI学習は機械読み取り可能な形であれば拒否可能」という文言があることも念頭に置くべきである。現在の生成AIは「大量の著作物を入力することで商用レベルの性能を維持している」といっても過言ではなく、更には生成物が元の著作物の市場と競合している。AIの原材料としての著作物が、実質使い放題の状態であることに懸念の声があがっている。
Q44. AI学習禁止の意思表明は意味があるのか
A. 現状、法的拘束力はないと考えられる
著作者の意向を無視したAI開発の実態から、「AI学習禁止」「No AI」という意思表明を行っているクリエイターも少なくない。現在の状況では、これらの文言は法的拘束力を持たないが、倫理面において意思表示はある程度の意味を持つと考えられる。
一方、開発者側としては無差別にネット画像や文章を収集しており、たとえ配慮したくても、短い文字で表明されているだけでは、収集プログラム自体が判断できないため意味がない。その対策として、ChatGPTがGPTbotをブロックするrobots.txtを示したように、埋め込み型のメタデータとしてのタグ付けは今後需要が生まれる可能性がある。実際、Adobeは画像における「Do not train」タグが普及するように促進している。このような埋め込み型データはAI生成タグなどでも応用が可能であり、AIが再度生成画像を学習して劣化することを防ぐこともできるかもしれない。
Q45. AIタグは必要か
A. 有用性はあると考えられるが、範囲が難しい
現在、AI生成物はネット上で多く見受けられているが、実際の写真なのかどうなのか、AIによるイラストなのかが見ただけで判別することが難しくなっている。文章であれば殊更不可能である。画像の場合、特定の特徴があれば分かることもあるが、加筆など手を加えると更に分からなくなる。ディープフェイク対策として透明性を図る上でもAI生成の明示は今後も必要とされることが多いと思われる。
一方で、利用者側からすれば「AI絵が見たい」人や「AI絵は見たくない」人もいる。そのような状況において、AIタグを使用することは「すみわけ」という点では有用である。その流れが進まない一因として過剰なAI利用バッシングがあるという意見もある。
また、僭称問題としてAI生成物を手作りのように謳うことも問題視されている。AI生成物を手描きであるかのように偽った場合、広く頒布したり金銭授受があれば、著作者名詐称罪(著作権法121条)が絡む可能性もある。現在は多くの収益に絡むプラットフォームでAI利用が禁止または明示するように義務付けられることが増えており、収益化する場所が狭まっている。更に言えば「テセウスの船」の例のように、何%がAI利用ならAIタグを用いるべきか、などの問題もある。
Q46. 人とAIの学習は違うのか
A. 理論は同じだが、仕組みが違う
理論は同じであるが、過程や仕組みが異なる。そもそもAIの学習はヒトの学習を予想し模倣したものであり、理論上は類似していて当然である。しかしながら、その学習の過程は異なる。まず、AIに入力させるのはあくまで人であり、データを集め加工するところまでは開発者等が行う作業である。この過程において著作物を利用する際に複製や翻案が必ず含まれるが、人の場合は必ずこれらの行為が行われるわけではない。また、学習済みモデルは、容易に複製可能である点も重要である。たとえば、ある人が有名画家の絵柄を学び、贋作を生み出せるとしても、その人を複製し配布することはできない。一方でAIのモデルは用意に複製配布可能となる。
また、この議論における前提として、「学習」の定義範囲がバラついていることを理解する必要がある。この場合の「学習」の捉え方は「狭義」と「広義」に分かれ、特に生成AIおいて「狭義の学習」とは「学習済みデータセットをAIプログラムに入力し学習済みモデルを作成すること」であるが、「広義の学習」とは「著作物などの学習用データを収集し、学習用データセットに加工した上で、AIプログラムに入力する過程」を指す。後者の場合、データを収集するところから「学習」と捉えていることに注意が必要である。「無断学習」という言葉を使用する場合は、後者の定義であることが多い。
Q47. 生成AIと2次創作と違うのか
A. 基本的には違うが、著作権法の議論で絡んでくることがある
そもそも生成AIと二次創作は基本的には異なるものであり、生成AIでも二次創作が可能であるうえ、生成AI自体が二次創作物を大量に学習していることは事実である。生成AIへの学習に著作物を利用する場合、現在の日本の著作権法では条件を満たせば著作権者への許諾は不要だが、この段階で許諾を必須化としてしまうと、著作物を基にしたその他の活動にも影響が出る可能性がある。その内の一つが、二次創作である。そのため、著作権法の拡大を無条件に許容する場合、一部の活動に制限が出る可能性が示唆されている。現在の二次創作は、多くの創作者や一次権利者の間で文化的な背景を築いてきた経緯があり、生成AIという新しいツールをどう捉えるかが課題となる。
また、生成AIは、そのシステムの原材料として、多くの著作物を含むため、「二次的著作物のようだ」と表現されることもある。この場合は、法律上の概念とは異なるため、あくまで成立方法の表現の問題であり、実際の二次的著作物としての扱いは難しい。
Q48. 生成AIは単なるツールなのか
A. 生成AIは単なるツールであるが、成立過程が他ツールと異なる
生成AIはあくまで「人間の指示通りに生成を行うシステムツール」である。ただし、その生成過程はAI側のランダム性を含んでおり、「AIによる創作」という要素が少なからず含まれる。この部分は人が創作などを行う点と異なり、AIの自律性や独自性を認める部分となるため、著作権の認定などが難しくなっている。AI利用者はいわば、AIへの指示を行い創作させるという点で、浮世絵における版元のような立ち位置かもしれない。
また、一定の性能を維持するために、多くの著作物を原材料にしなければならない点は、今までのデジタルツールとは異なる点である。画像の場合、写真の誕生や3Dモデルの登場などと比較されることは多いが、写真も3Dモデルも、性能を維持するために既存の著作物を大量に利用する必要はなかった。
Q49. 画像生成AIは他の生成AIと違うのか
A. 同じところもあるが、生成物の性質が個々に特徴を持つ
著作物の学習という点では文章や音楽なども同等であると考えられるが、生成物の性質が個々で異なる。画像の特徴として、①生成物の評価が誰にでも容易にできること、②単純な生成物1枚でも商用利用が可能、という点が挙げられる。文章や音楽などではこのような利用は難しい。画像生成AIはこのような商用転用の利便性が特徴でもあり、目につきやすいことから話題になりやすい。たとえ人体解剖的に不整合な点があろうと、Inpainting機能などでAIの中で微調整が可能となっており、必ずしも加筆が必要ではない。また、画像は学習元にしろ生成物にしろ、基本的に著作物としての性質を持つということも重要であろう。
文章の場合は、商用活動の補助としての利用は十分可能であるが、生成された文章を直接商用に利用することは難しい(ブログ系まとめ記事などなら可能だが)。著作性のない文章も多く、この点は画像とは異なる。音楽も大量に生成が可能であり、プラットフォームへの大量投稿や特定のアーティストに似せた物が話題となっている。AIボイスなどに関しても、だれでもない合成音声ではなく、特定の声優などに寄せたものが話題になりやすい。
Q50. 生成AIはコラージュなのか
A. 理論上は異なるが、類似する点もある
理論上はコラージュではないが、その生成過程はコラージュに類似している。コラージュは既存画像の切り貼りを行った作品という意味合いを持つが、生成AIの画像は実際に画像の切り貼りを行っているわけではない。しかしながら、学習元の特徴量をデータとして保持し、入力されたtextをもとに適切な画像が出力されるように算出描画する(拡散モデルの場合はノイズ除去)。その際の生成過程は「学習したデータの組み合わせ」であり、一定の素材を組み合わせて新しいものを生み出す、という点においてはコラージュのようにも解釈が可能である。作家のスティーブン・キングはThe Atlantic誌に寄せたエッセイの中で、生成AIを指して「最先端のデジタル・ブレンダー (state-of-the-art digital blenders)」と呼んだ。
人の創作も同じではないかという指摘もあるが、生成AIは著作物の特徴を複製可能な実存的なデータにしているという点が異なる点であろう。人は過去の作品に縛られない新規の創作表現が可能、という指摘はあくまで理想論であると考える。
※アートとコラージュとフェアユース
コラージュとは、20世紀初頭にピカソやブラックによって表現として取り入れられた手法であり、フランス語で「糊付け」を意味する。本来の趣旨としては、もともとの画像の意味から切り離し、それらを組み合わせることで新しい意味を持たせることであった。しかしながら、既存の出版物などを利用する点から、著作権侵害に該当することもある。また、アプロプリエーションと呼ばれる手法は「流用」を意味し、既存の写真などをそのまま自身の作品に取り込む。アプロプリエーションを用いる有名なアーティストしてアンディ・ウォーホルが挙げられるが、2023年5月、リン・ゴールドスミスの撮影したプリンスの写真を用いた作品「プリンス」シリーズが著作権侵害であるとの最高裁判決が出た。当初はフェアユースに認定されるだろうという見通しが多かったが、最終的には認定されなかった。プリンスシリーズはプリンスの写真から顔の部分を切り取って、背景の色などを変えて作成したものである。ウォーホル財団側は「この利用は『変容的』であり、元々のポートレート写真とは異なる意味やメッセージを伝えるものである」とフェアユースを主張した。しかし裁判所は「変容性だけがフェアユース認定に至るものではなく、程度の問題であり、商用利用などの他の考慮事項と比較するべきだ」と述べている。最終的には「プリンスシリーズの作品は、プリンスの雑誌において、プリンスを描写するために利用されており、実質的に同じ目的で利用されている」と結論付けた。
→生成AIがフェアユースにあたるかどうか、という点については議論が定まっていない。多くの新技術はフェアユースに当たる可能性も高い一方で、プリンスの判決のように、商用利用や使用目的などが総合的に判断され、必ずしもフェアユースには当たらない場合があるという点は注目すべきである。
Q51. 生成AIは学習元を復元するか
A. 特定条件下では復元レベルの類似性を示す
生成AIは学習したものを完全に復元することはほぼ無いが、特定のモデルや特定のプロンプトなどで、類似する画像が出てくることは観測されている。たとえば、StabilityAIの開発した画像生成AIであるDeepFloydIFに固有名詞を打ち込んだ際にゲームパッケージなどの元画像と極めて類似のものが出る。ChatGPTでも学習した書籍と同じようなフレーズを出力することがある。また、学習元のデータが少ない場合は、生成AIがバリエーションを持たせられず、意図せず類似する画像をだすことがあり、これらは過学習と呼ばれる。過学習の対策として多くのデータを学習する必要がある。
Q52. 生成AIへの懸念は「怖い」「ズルい」という感情が理由なのは本当か
A. 主に倫理的問題が理由である。感情として否定するものではない
生成AIが出始めた当初、生成AIに対して懸念の声を上げる人の理由に関して「怖がっているのだろう」「ズルいと思っているのだろう」という、推測が挙げられた。確かに、そのような感情が無いわけではなく、実際に失業の可能性は政府の掲げるリスクの1つであり、創作過程をすっ飛ばして生成するAIの力は凄まじいものがある。しかし、そのような感情だけではなく、法的課題や倫理的課題を総合して懸念を示している人が多い。そのため、倫理的に問題のない生成AIなら活用したいという人も多数存在している。
Q53. 生成AIの倫理的課題は単純な話なのか
A. 今後、更に複雑化していく
現在の生成AIは、学習元と生成物がほぼ1対1対応の単純なモデルが多いものの、今後の生成AIはより複雑な学習を行い、それに伴い入力されるデータや著作物も極めて多岐にわたることとなる。文章、音楽、画像、コードなど、複数の学習元を学習した場合、それぞれの対応はどう考えるべきなのか、という更なる疑問が出現する。
また、著作物を生成AIに学習させ、そのAIが出力した生成物を別のAIに学習させた場合もややこしい。この場合、新しいAIは著作物自体を学習していない。現在世界的な見解として、単純なAI生成物には著作権が生まれないため、これらの生成データを学習した新しいAIは権利的にクリアな生成AIになりえるのか、という疑問もある。
Q54. 生成AIにアートとしての1面はあるか
A. 生成AIをアートとして利用することは十分に可能である
生成AIをアートとして活用することは十分可能である。しかしながら、アートの文脈に置くのであれば、単純な「AIというツールを用いた作品」ではなく、「多くの著作物を利用した生成AIを用いた作品」という位置づけになると考えられる。美術や芸術において、作品に用いたツールや意図も評価されることが多いことから、生成AIを用いるのであれば、そのシステムが成立する過程の性質から逃れることは出来ない。
今、生成AIが話題になっているのは、その生成物の芸術性の是非を問うものではない。商用における市場の衝突や文化への影響という点が多い。生成AIの生成物が持つ複数の文脈において、芸術、文化、産業という個々の観点は別に存在すると考えられる。商売にはならないが芸術になり得るもの、芸術と文化の比較(サブカルチャー等)など、その文脈は複雑であり、論じ分ける必要がある。
Q55. AI生成物は判別可能か
A. 判別は困難である
AIを使用したかどうかを生成物だけで判断するのはほぼ不可能である。特徴的な文章や画像の表現があれば判断できることもあるが、AIの進化とともに徐々に消滅していくこととなる。画像などが、AIによる生成物かを判断する判別用AIシステムもあるが、すべてを判断できるわけではない。ハルシネーションは判別困難な故に幻覚なのだろう。
既に生成AIによって生成されたものはネット上に氾濫している。ブログ系記事や、TwitterなどSNSのアカウントも生成AIによる自動化が行われているものもある。顔写真もAIによる自動生成で、普通に対話していた相手がAIであったということも実際に報告されている。(対話相手がAIかどうかを判断する方法として唐突に料理の作り方を英語で入力するという方法等がある)
たとえば、ChatGPTの生成した文章に「視覴」という熟語が出現することが報告された。しかしこの熟語一般的な辞書に載っておらず、検索をかけても生成AIで自動生成したブログ系記事などしか引っかからなかった。ちなみにChatGPTに尋ねると「視覴は実在する日本語」だと返す様子(問い詰めると否定する)。文脈からは「視覚」や「視聴」の意味でつかわれることが多いようで、三重大学の奥村名誉教授によると文字コードの混雑が原因ではないかと考察されている。
Q56. 生成AIの悪用は可能か
A. 脆弱性が指摘されており、悪用のための生成AIも存在する
ChatGPTなどには悪質なプロンプトに応じないようにするガードレールという対策が施されている。ガードレールを突破しようとする人々もおり、アップグレードされるのが常であるが、ガードレールが全くない生成AIなども出現している。あらゆるガードレールのない対話型生成AIは、詐欺用の文面を生み出したり、サイバー犯罪への応用が可能とされる。既に公開されているAIでは、悪意あるコードの生成や、検出回避のマルウェアの開発などが可能であるとされる。
また、ChatGPTやBard、Claudeなど既存の生成AIでも脆弱性が指摘されている。2023年7月のカーネギーメロン大学の指摘では、コンテンツフィルタ―を回避して有害情報や偽情報などを提供するようにできるとされている。同年5月の三井物産セキュアディレクションの検討でも画像生成AIのSafety filterを突破することが可能であったり、ChatGPTから個人情報を聞き出す方法などが報告されている。
※ハッカーの矜持
現在の生成AIの広がりは、プログラミングなどの技術を専門とする人々の活躍によるものが大きい。特にオープンソース化による発展の後押しは力強いものがある一方、相応のリスクももたらした(厳密なオープンソースの定義はここでは置いておく)。オープンソースのAIの一つとして、StablityAIのStable diffusionが挙げられるが、その理念として「すべての人に創造性の贈り物をもたらす」と述べている。ローカル環境で動かせるようになった結果、様々な派生モデルが開発され、サービスが提供された一方で、不正なモデルの混入や非倫理的な使用も見られるようになり、一般企業が利用するにはリスクが増大する結果となっている。
また、画像生成AIにおけるControlNetを開発したlllyasviel氏はASCIIのインタビューの中で「ハッカーの思想の中には『データは誰にも束縛されるべきではない』というカウンターカルチャー的な側面がある」と述べている。AdobeなどがAI生成物にタグをつけようとしている一方で、生成時のメタデータを残さないという方針を取りたいという。
生成AIの登場は、技術的な進歩を人類にもたらした一方、既存文化との衝突という結果も引き起こした。文化と技術の双方を推し進める人々の考え方に相違があることは念頭に置くべきだろう。
(D) 実践と応用
Q57. 国内において生成AIの活用事例はあるか
A. 今までいくつかの利用例があるが、課題も顕在化した
主な活用例としては企業や自治体でのChatGPTなどのLLMであり、画像生成AIなども一部で利用されようとしている。広告業界では早期から生成AIが活用されている。しかしながら、倫理面や権利面の不明瞭さから、課題が顕在化する結果となったものもある。
具体例
・東京都:2023年8月、文章生成AIとしてChatGPTの全局導入を行った。その際、文章生成AI利活用ガイドラインを公表している。アイデア出しや文面作成の下書きへの利用を推進する一方、個人情報や機密情報の入力は禁止しており、意図しない著作権侵害などに注意するように記載されている。その他自治体でもChatGPTの利用は推進されている。
・サイバーエージェント:広告企業大手のサイバーエージェントは独自の日本語LLMを開発しており、広告のコピーなどに独自のLLMやChatGPTを利用している。
・集英社:Comic-Copilotという名前で、ChatGPTを利用した漫画作成サポートサービスを展開。テーマやタイトル、キャラクター名、セリフの調整などアイデア出しや相談相手としてのサービスを提供することができるとしている。
・集英社/週刊プレイボーイ:2023年5月に生成AIで生成したグラビア写真集『生まれたて。』を販売。AIで生成された「さつきあい」という実在しないモデルによる実写風写真集である。しかしながら、6月には販売を中止。その際、編集部は「制作過程において、編集部で生成 AI をとりまく様々な論点・問題点についての検討が十分ではなく、AI ⽣成物の商品化については、世の中の議論の深まりを見据えつつ、より慎重に考えるべきであったと判断するにいたりました」と表明している。
・新潮社:2023年3月、Midjourneyの生成イラストを用いて作られた『サイバーパンク桃太郎』が出版された。元は2022年8月にSNSに投稿されたマンガの加筆修正版である。新潮社は、のちに生成AIへの懸念を発表した日本書籍出版協会に所属している。
・サントリー:2023年7月、CCレモンを擬人化した生成AIの実写風キャラクターを発表。顔は担当スタッフの顔写真を元にしており、衣装や声、動きを生成AIで作成。セリフも文章生成AIを用いている。
・福井県坂井市:東尋坊などを有する福井県の坂井市は、AI画像を推進するSOZO美術館の運営会社などの関わりにより、AIアートコンペを開催。開催当初にはグランプリ作品をふるさと納税返礼品として活用する予定も発表された。しかしその後、ふるさと納税への利用は再度検討するとし、開催期間途中からStable diffusionのみ禁止という規約も追加された。現在応募ページは削除されているため詳細の確認はできない。
・武蔵野美術大学:2023年6月、武蔵野AI美術大学 AI絵画アワードと題したAIイラストのコンテストを開催。開催にはスタディプラス、カヤック、AI Picassoなどが関わっている。規約としてAI Picassoが提供するアプリであるAIピカソの利用が義務付けられた。中身はStable diffusionである。開催当初、著作権に配慮した生成AIなどの紹介がなされていたが、その後多くの指摘を受け、AIピカソは著作権に配慮はしておらず、主催者側の誤認であったことが開催中に公式に発表された。最終的には受賞者なしとの結果となり、「運営および審査過程において、現在の画像生成 AI 技術によって生み出された作品から、特定の作品を選出し発表することは困難であると判断いたしました」と発表された。
・日本赤十字社:2023年8月、日本赤十字社東京都支部の関東大震災100年プロジェクトの一環として、”新”証言を生成AIで作成するという企画を行った。当時の赤十字の救護活動を伝える絵に描かれた避難民をベースに生成AIで人物の肖像を生成し、ChatGPTに追加の文献を読み込ませたうえで、震災発生当日におこったことを被災者に語らせるスタイルのショートストーリーを発表予定であった。しかしながら、さすがにその証言は捏造ではないか、という声もあがり、結果的には中止となった。
・The HEADLINE:2023年8月、ニュース解説メディアであるThe HEADLINEが、LLMを元にした独自の生成AIを利用した記事を公開したところ、他報道機関の記事の剽窃盗作と言えるようなものになっていた。発覚後すぐに記事は非公開に。複数のWebサイトや報道機関のサイトから話題になっているキーワード等について記事を生成するものであったらしいが、意図せず部分的なコピペになっていたようである。
Q58. 生成AIを制限しているプラットフォームはあるか
A. 以下のプラットフォームで制限されている
幾つかのプラットフォームで生成AIの使用が制限されている。その理由としては、大量の作品が出品されることで他の作品が埋もれること、審査に多くの時間がかかること、データ負荷による影響、生成物の権利の所在、企業側の法的リスクなどが挙げられる。(2023年9月における状況。以後、一部サイトでは生成AIの取り扱いが再開された)
・Pixiv:FANBOX,pixivリクエスト, BOOTHなどの商用サービスにおいて生成AI作品の販売を禁止制限した。
・ニコニコ静画:収益化時に、生成AIによる自動出力されたものは投稿禁止。
・SKIMA、ココナラ:生成AIを利用した画像などは禁止。
・FANTIA、ci-en:AI生成作品の取り扱い停止
・DLsite:漫画、イラスト、動画、素材などでAI生成作品を禁止
・とらのあな:電子書籍におけるAIツール使用作品を停止
・メロンブックス:AI生成作品を実本、電子ともに取り扱い停止
・Steam:権利が不明瞭な生成AIを用いた作品は禁止。権利が明瞭なら取り扱いできるとのことだが、現在主流の生成AIは不明瞭と判断している。
・Getty images:AI生成作品の取り扱いを禁止
・アマナイメージズ:AI生成物を取り扱い禁止。「現在、AIで生成された画像が、法的リスク・トラブルリスク・品質などの観点でアマナイメージズが設定している審査基準を満たしていない」と評している。
※コーエーテクモホールディングスの考え方
2023年8月に掲載された4Gamer.netのインタビュー記事で、コーエーテクモホールディングスの法務部長である西村氏は以下のように述べている。「社内資料とか社内での活用に関しては,おおむねOKにしたいと思っています。ただ生成AIで作ったものを製品に採用するとなると,著作権上の問題が今のところは完全にはクリアできておらず厳しいですね。特に当社の場合,日本の著作権法だけに注意すればいいわけではないので,アメリカとか欧州の著作権法においてどうなるのかというところも,非常に気にしています」
引用元:[インタビュー]コーエーテクモという会社のAIへの向き合い方は,堅実かつ歴史に裏打ちされたものだった。AIの使い方から会社のポリシーに至るまで,普段は表に出ない人にあれこれ聞いてみよう
https://www.4gamer.net/games/561/G056198/20230824052/
Q59. Adobefireflyはどのようなものか
A. Adobestockを元に学習された画像生成AI
2023年9月に商用可能なバージョンが発表された。パブリックドメインやAdobestockなどを利用して学習しており、ライセンスなどの問題はクリアされていると謳う。テキストからの画像作成や、テキストへの画像効果追加、生成塗りつぶし、生成再配色などが可能。Adobestock内のエディトリアルは学習除外していると言われているが、AI生成画像などもタグの無い画像が混ざりこんでいる可能性がある。
コンテンツ認証情報として、生成された素材に自動的に適用される情報があり、その中には、出力サムネイル、発行者、コンテンツ概要、使用されたAIツール、編集履歴などが含まれる。情報はファイルに添付されており、Adobefireflyギャラリーなどで表示可能。

Q60. mitsuadiffusionとはどのようなものか
A. 著作権的な権利がクリアされた国産の画像生成AI
株式会社アブストラクトエンジンによって開発された画像生成AI。パブリックドメインの画像やオプトインの画像のみでU-netの学習を行っている。学習元や生成された画像の権利的問題がクリアされているため、心理的にもハードルが低い生成AIである。しかしながら、OpenCLIPを利用していることを問題視する人も居る。また、ネットの画像を大量に学習したモデルではないため、出力に性能は未だ十分ではない。一方で、学習元に多いと思われる古風な作例や芸術的な絵画に関しては一定のクオリティを発揮する(以下、作例)



おわりに
現在の生成AIは多くの課題を抱えており、その課題は技術的、法的、倫理的、社会的と多岐にわたっています。今後、開発者やサービス提供者および利用者に関しても、安心に利活用できる生成AIの発展を望みます。
※過去のまとめ
・2023年5月19日:生成AIの課題点まとめ (総論)
インターネット落書きマンの立場から、最近の生成AIについて思うことをまとめてみました。少しだけ勉強した後の、あくまでも個人的な感想です。著作物の権利が守られ、AI技術が有用に使われることを望みます。(1/2)#AIアート #AIイラスト pic.twitter.com/0S5MOI1Rum
— 嘯(しゃお, 𝕏iao) (@xiao_signo028) May 18, 2023
・2023年6月13日:生成AIの「無断学習」について
生成AIの「無断学習」についてまとめてみました。AIの学習を取り巻く事実をできるだけ羅列しています。かなり複雑なので文字だらけになっています。添付資料としてデータセットや関係事例の表を付けています。今後のAIの未来を考えるにあたって、参考資料として頂ければ幸いです。(1/3) pic.twitter.com/6OTLWJ3rad
— 嘯(しゃお, 𝕏iao) (@xiao_signo028) June 12, 2023