YANS2019でアノテーションハッカソンを開催しました

こんにちは。xpaper.challenge運営の@ymym3412です。
8/26(月)~8/28(水)まで札幌で開催されていたYANSシンポジウムでアノテーションハッカソンを開催してきました。
今回初めての取り組みということもあり「アノテーションでハッカソンをする...?」という方も多いと思うので、こちらの記事でアノテーションハッカソンとはどういったものなのかということや実際に開催してみて得られた気づきなどをご紹介できればなと思います。
アノテーションハッカソンとは
Kaggleでは「モデル」を作ることで精度を競いますが、アノテーションハッカソンでは参加者が「データ」を作ることで精度を競います。
つらいアノテーション作業をコンペ形式で盛り上げて楽しくデータを作ろう!というのがアノテーションハッカソンの趣旨です。
ハッカソンの全体的な流れはこのようになっています。

1. 各チーム共通で配布される学習データに対して、チームに分かれてガイドラインに従ってアノテーションを行う
2. 運営が用意した全チーム共通の学習用スクリプトで学習を行い、チーム毎のモデルを作る
3. ガイドラインに沿ってアノテーションされたテストデータに対してモデルが予測を行い、その予測に対するスコアで競い合う
アノテーションハッカソンでは、ガイドラインに沿った高品質なアノテーションを大量に行うことで汎化性能の高いモデルを構築でき、それにより上位を目指すことが可能になるということです。
「高品質なアノテーションを多くのデータに対して行う」ことが「ハッカソンで上位を目指す」というインセンティブになっているため、アノテーションで課題になりがちな「アノテーターのモチベーション設計」というものが不要になります。
このアノテーションハッカソンのスキーマを利用すれば、専門家による少量高品質のアノテーションを施したテストデータを用意すれば、参加者はコンペ形式で楽しみながら、高品質なアノテーションデータを作ることが可能になります。
経緯
アノテーションハッカソンの構想自体はxpaper.challengeの運営チームで雑談をしているときに「NLPは公開されているデータセットが多くないし、コンペ形式でわいわいしながらデータ作って公開できればNLP界隈にも貢献できるのでは?」と話題になったことがきっかけでした。
そこからふわふわっとした構想がありながらもきっかけがなく先に進まない時間があったのですが、運営の数名がYANSに参加するということで毎年行われているハッカソンにこの企画を持ち込めないか?ということでYANS運営に話を持ち込むことになりました。
※YANS運営に企画を持ち込んだ際の企画書の一部


企画を持ち込んだのが8月の頭。
そこからデータセットの用意や環境の準備に関するディスカッションを重ね、無事に当日開催までこぎつけることができました。
時間がない中でご協力頂いたYANS運営メンバーやxpaper.challengeの他の運営メンバーには本当に感謝しています。
アノテーションハッカソン開催!
アノテーションハッカソンのことは1日目のハッカソン企画の説明のところで紹介してもらいました。
モデル作りではなく「データ作り」で競い合うハッカソン「アノテーションハッカソン」をやります!
— ymym@やむやむ (@ymym3412) August 26, 2019
これを機にアノテーションを経験してみたい方、アノテーションツールを使ってみたい方、退屈なアノテーションをもっと面白くしたい方、ぜひご参加を!#yans2019 pic.twitter.com/MTuGfEqmNG
今回のハッカソンで取り組んだタスクは固有表現抽出(NER)で参加者向けのアノテーション環境として、OSSのdoccanoをサーバーとセットで提供しました。
ハッカソン開始のタイミングで学習データとアノテーションのガイドラインを参加者に配布し、ハッカソンが開始となりました。
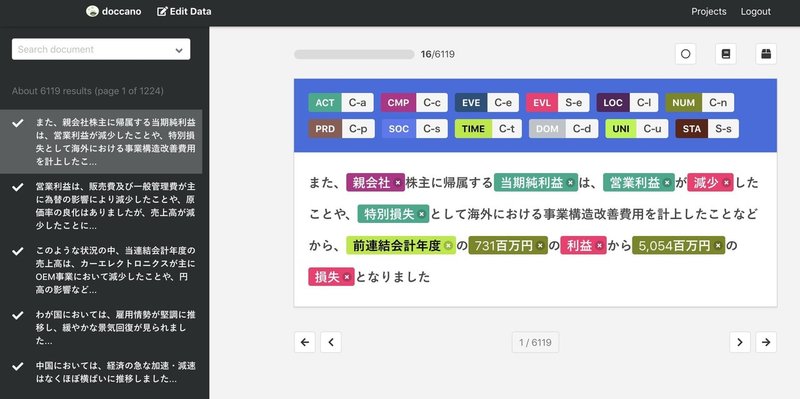
データの提出~学習スクリプトの実行~評価スコアの計算~リーダーズボードへの反映は全て自動化されており、参加者はdoccanoからデータをエクスポートして所定のslackチャンネルにアップロードするだけで結果が分かる仕組みです。
このアップロードされたデータを拾う~リーダーズボードへの反映までを行う基盤は@icoxfog417さんが一晩でやってくれました。
アノテーションハッカソンの開催中も学習スクリプトの速度改善ももくもくと行なっていました
(2回目なども予定しているので基盤改善にご興味ある方はぜひお声がけください)
アノテーションハッカソンは、限定1名(そんなにいないと思うので)でバックエンドのMLOpsを改善する方を募集します。学習速度を上げたいので、そこにチャレンジ。裏側はこんな感じです。
— piqcy (@icoxfog417) August 26, 2019
#yans2019 pic.twitter.com/UKK5idOwZt
(開発秘話は別の記事にもまとめてくれています)
アノテーション作業が本格化した2日目の夜からSlackチャンネルやリーダーズボードが賑わいはじめました。
一番楽しい時間でしたが、提出する度に変動する順位に囚われ寝るタイミングが分からない、という苦しい時間帯であったようにも思います。
結果発表!
熾烈な戦いの末に「チームクラウドソーシング」(こんな名前ですがクラウドソーシングはしていません)が4ポイントの差をつけて優勝しました。
最終日の各チームの成果発表で初めて各チームのアノテーションのやり方を知ったのですが、面白かったのはどのチームも事前に粗いアノテーションを自動付与するなど、ただ単にアノテーションを行うだけではなかったことです。
「JUMAN++ & KNPでラフアノテーション + 人手」だったり「GiNZA NER/辞書での擬似ラベル + 人手」のように外部のツールを活用して大量のデータを作っていて、これぞハッカソン!と感じました。
人手アノテーションの負担を減らす、というのがアノテーションハッカソンの趣旨なので、こういった手法を発見してくれるのは運営としてとても嬉しかったです。
振り返り
初めての試みでしたが、事前準備も甲斐もあり概ねうまく進行していたと思います。
アノテーションについては「最終的にどういったことをやりたいのか」「そのためにどういったデータを抽出したいのか」といったアノテーションの趣旨を明確に言語化し、定型的なパターンをいくつかまとめてこれらをガイドラインに記載したことで参加者をスムーズにアノテーションに導入できたと思います。
※ガイドラインから一部抜粋

また運営によるサンプルアノテーションを配布したことも導入をスムーズにしたと思います。
課題点としてはテストデータに対する最終スコアの低さが挙げられます。
優勝チームのNERにおけるF値は28.1となっており、これは決して高い水準とは言えません。
モデルのテストデータに対するスコアが低い = 学習データとテストデータでアノテーションの基準にブレがある、ということなのでアノテーションハッカソンを通してアノテーションデータセットを作るためにはもう少し工夫がいると考えています。
最後になりますが、1ヶ月前というギリギリのタイミングでの持ち込みだったにも関わらず実現に向けて議論して頂きハッカソンへ目録まで用意してくださったYANS運営委員のみなさま、初めての取り組みで不手際もある中でも企画に参加し盛り上げてくださったハッカソン参加者のみなさま、そして忙しい中で企画実現に向けて作業をしてくれたxpaper.challengeの運営のみなさまに感謝を申し上げます。
次回以降の開催も考えているので、その際はぜひみなさまもご参加頂ければと思います!