
【手順解説】Google翻訳OCRによる図面PDF座標表のSIMA化

地積測量図や道路確定図などの座標表をSIMAファイルにするまでの過程です。
あくまで個人的な手法ですので、より適切、より効率的な方法があるかと思います。
手順は
① Acrobat Readerで図面PDFの座標表を画像として抽出
②ペイントに画像を貼り付けて保存
③画像データをGoogle翻訳でOCR、テキスト化
④メモ帳に貼り付けて保存
⑤テキストデータを読み上げソフトでチェック
⑥テキストデータをExcelに貼り付けてSIMAの形に
⑦Excelからメモ帳に貼り付けてSIMA化して保存
という流れになります。
工程が多く見えますが、ショートカットなどを活用して行えばかなり早いです。
メリットは
○大量の座標入力を素早く行える
○座標チェックの効率がいい
○図面ごとのSIMAを保存できる
などです。
① Acrobat Readerで図面PDFの座標表を画像として抽出
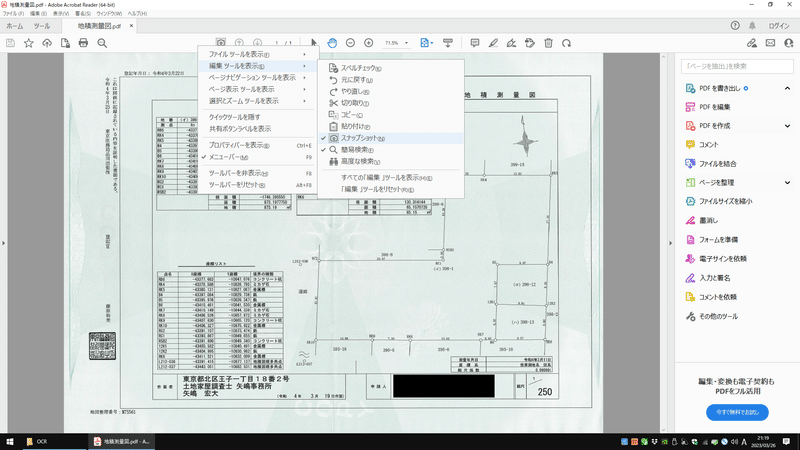
まず、座標を抽出したい図面PDFをAcrobat Readerで開きます。
ここで、「スナップショット」というツールを使います。
スナップショットは、選択した範囲を画像としてクリップボードにコピーするツールです。
初期設定ではツールバーに表示されていません。
ツールバーの何もないところで右クリック→編集ツールを表示→スナップショット
を選択するとツールバーに現れます。
まず点名を抽出します。
スナップショットを選択し、座標表の抽出したい部分を選択します。
この時、なるべく文字だけを選択し、罫線などが選択範囲にかからないようにします。
選択するだけでクリップボードに画像がコピーされます。
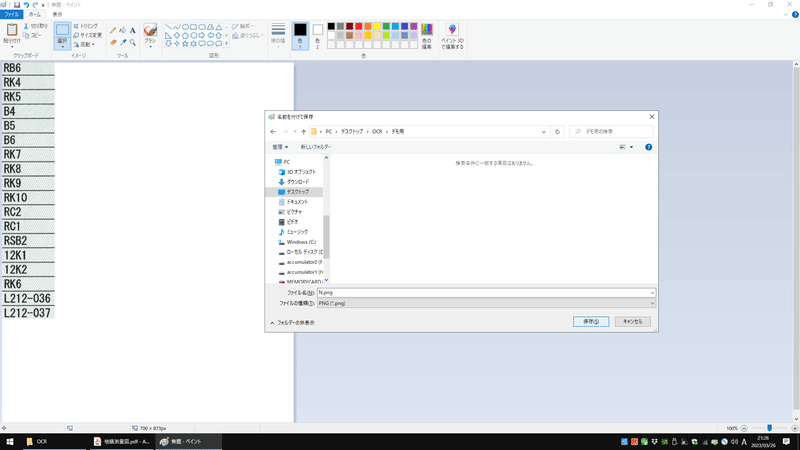
②ペイントに画像を貼り付けて保存
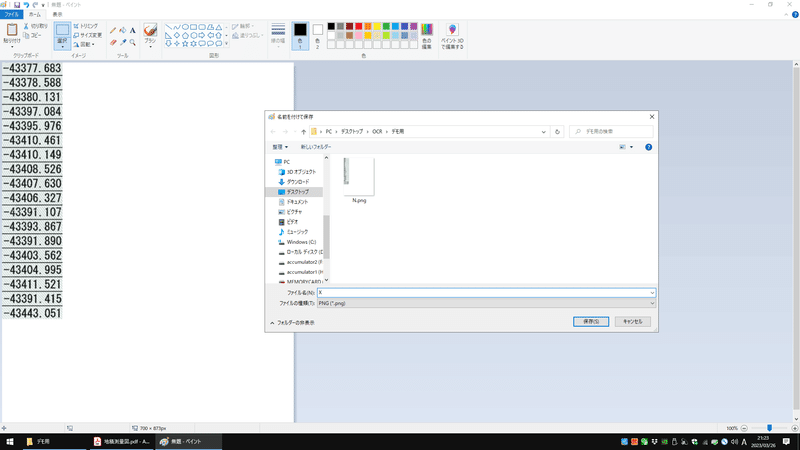
ペイントを開き、クリップボードの画像を張り付け、保存します。
ここでは「N」という名称で保存しています。
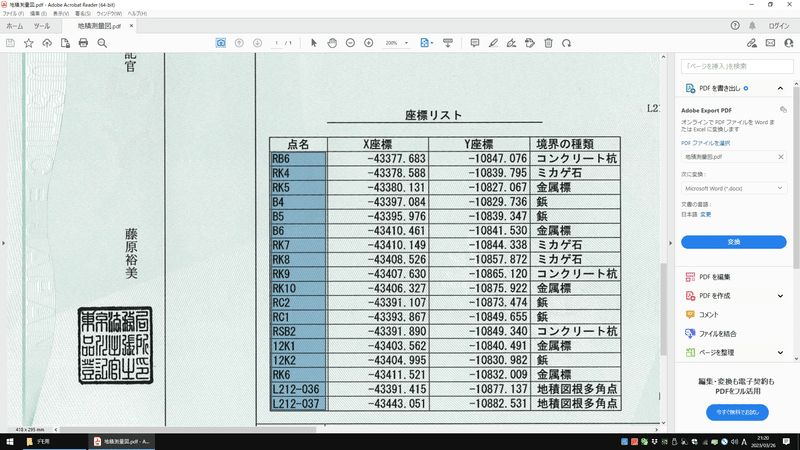
同様に、図面PDFのX座標、Y座標も画像として保存します。
③画像データをGoogle翻訳でOCR、テキスト化
次に、ブラウザでGoogle翻訳を開きます。
「画像の選択」の「パソコンを参照」から、先ほど作った画像データを選択します。
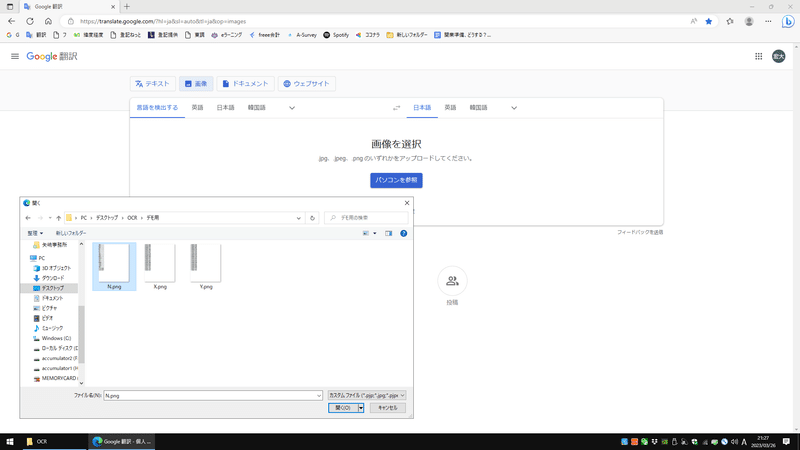
④メモ帳に貼り付けて保存
すると、OCRによって画像データからテキストが出力されます。
「テキストをコピー」を選択し、テキストをクリップボードにコピーしたら、メモ帳をひらいてテキストを貼り付けます。
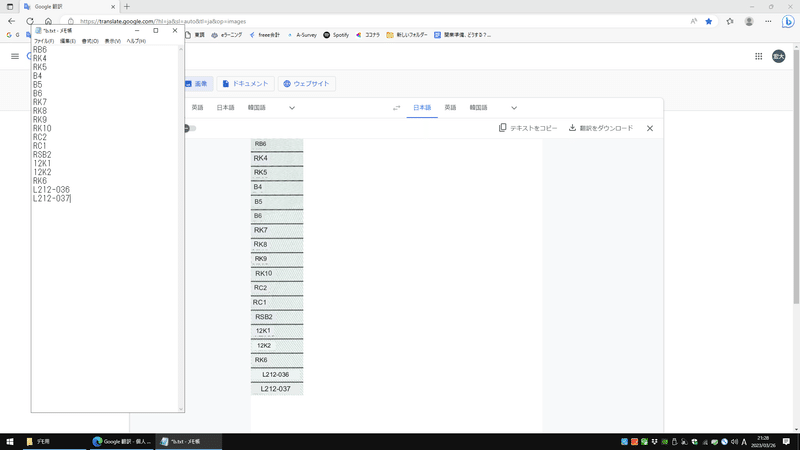
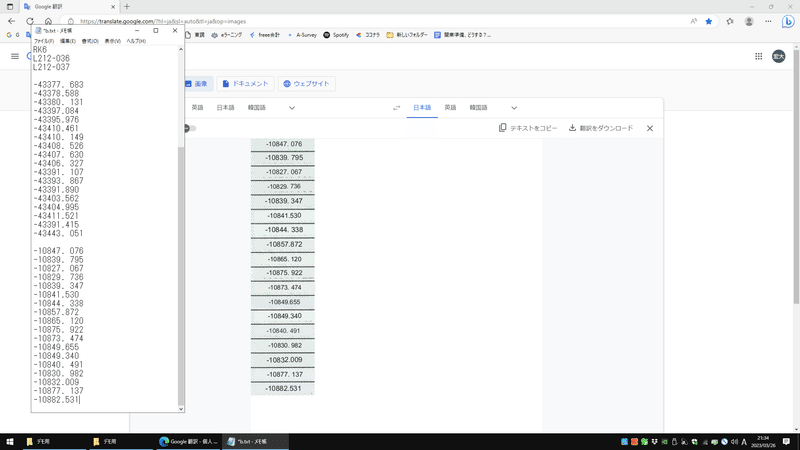
同様に、X座標、Y座標の画像をテキスト化し、同じテキストファイルに貼り付けます。
この時、空白が空いてしまった部分や、明らかにおかしい部分は手入力で修正します。
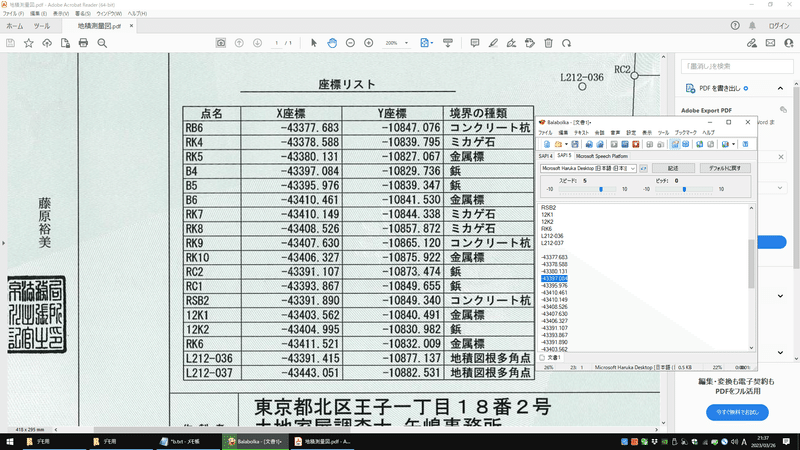
⑤テキストデータを読み上げソフトでチェック
先ほど作成したテキストを読み上げソフトに読み上げさせ、実際の図面PDFと照らし合わせてチェックします。
私は「Balabolka」というソフトを使っています。
間違いがあれば適宜修正します。
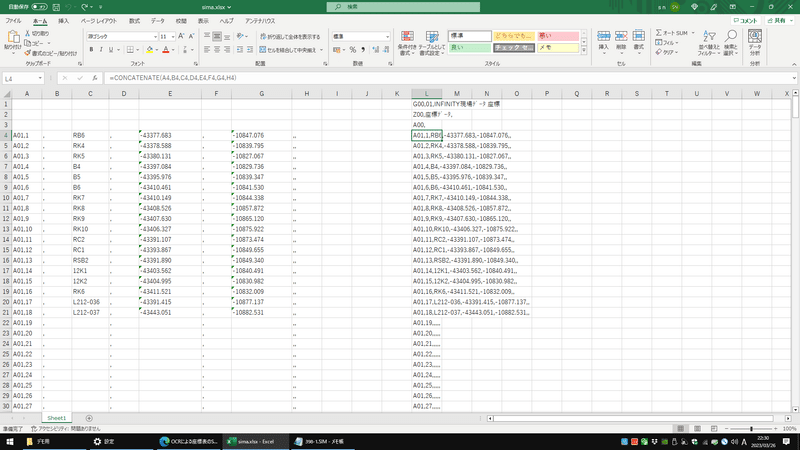
⑥テキストデータをExcelに貼り付けてSIMAの形に
チェックが終わったテキストをExcelに貼り付け、SIMAファイルの形にします。
Excel自体はCONCATENATE関数を用いた非常に単純なものです。
このExcelの解説は記事の最後に載せています。
点名、X座標、Y座標を対応する列に貼り付けます。
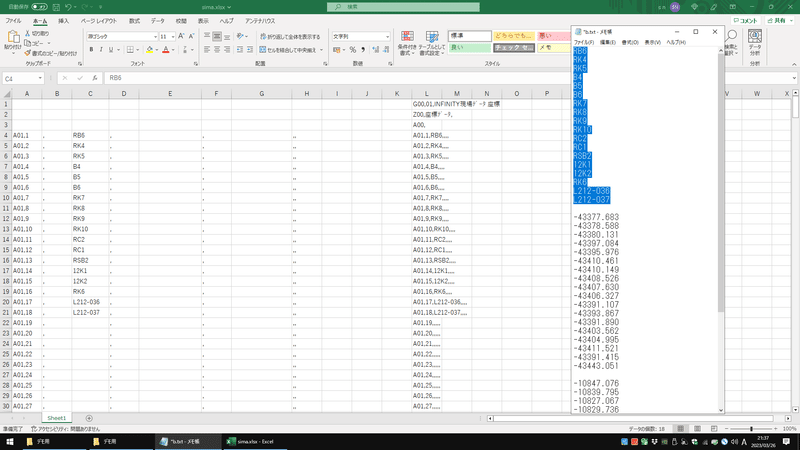
右側の列にSIMAの形になったテキストが作られるので、コピーします。
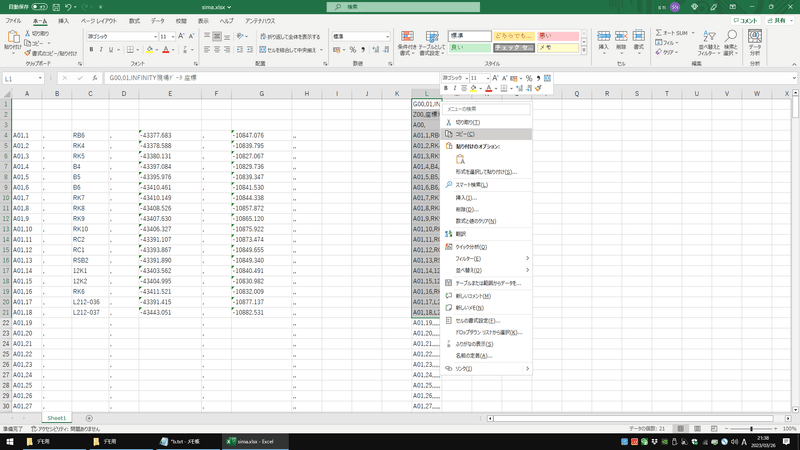
⑦Excelからメモ帳に貼り付けてSIMAとして保存
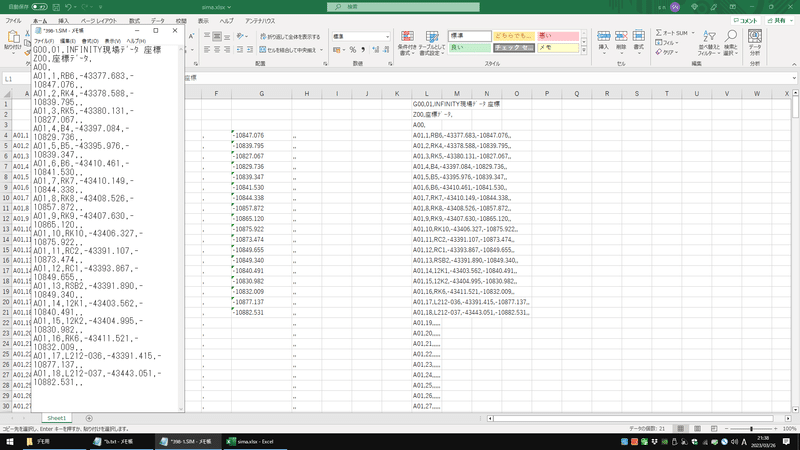
コピーしたものをそのままメモ帳に貼り付け、保存します。
保存した後、拡張子を.simにすればSIMAデータの完成です。
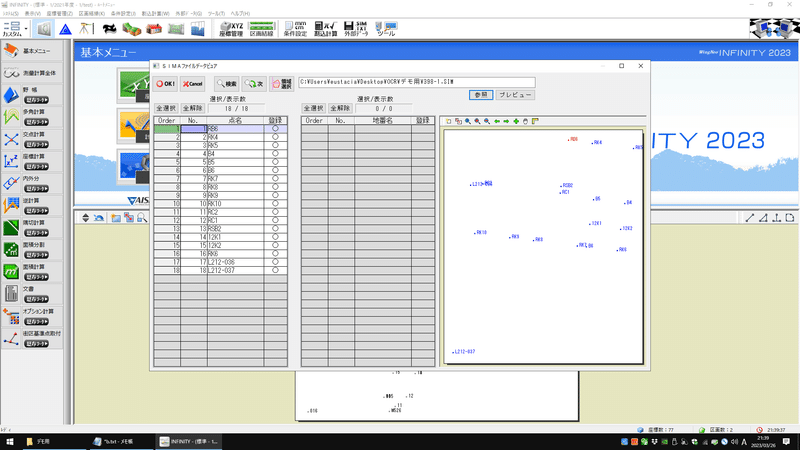
CADソフトで読み込んでチェック
CADソフトでSIMAデータを読み込みます。
区画を組んで、地積や辺長に間違いがないかチェックします。
Excelの解説
今回使ったExcelの解説です。
SIMAデータは、メモ帳で開くと
G00,01,INFINITY現場データ 座標
Z00,座標データ,
A00,
A01,1,RB6,-43377.683,-10847.076,,
A01,2,RK4,-43378.588,-10839.795,,
A01,3,RK5,-43380.131,-10827.067,,
…
と表示されます。
4行目の
「A01,1,RB6,-43377.683,-10847.076,,」
を例にとってみます。
ここで「A01,」の後の「1」が点No.
「,」をはさんで「RB6」が点名
「,」をはさんで「-43377.683」がX座標
「,」をはさんで「-10847.076」がY座標
最後にカンマが二つ「,,」
で一つの座標のデータになっています。
Excelでは、点名、X座標、Y座標を対応する列に入力すると、この座標データの形になるようになっています。
列Cが点名、列EがX座標、列GがY座標です。
カンマなどの文字をあらかじめセルに入力しておいて、CONCATENATE関数でA~Hセルのテキストを結合し、右側に出力しています。
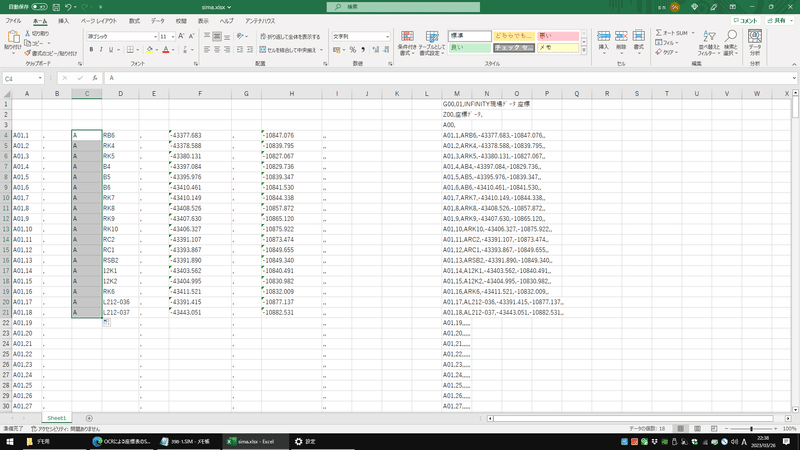
点名の列の右側に新たな列を挿入し、そこに記号などを入力すれば、点名に頭文字をつけるなどの工夫も可能です。
OCRのコツ
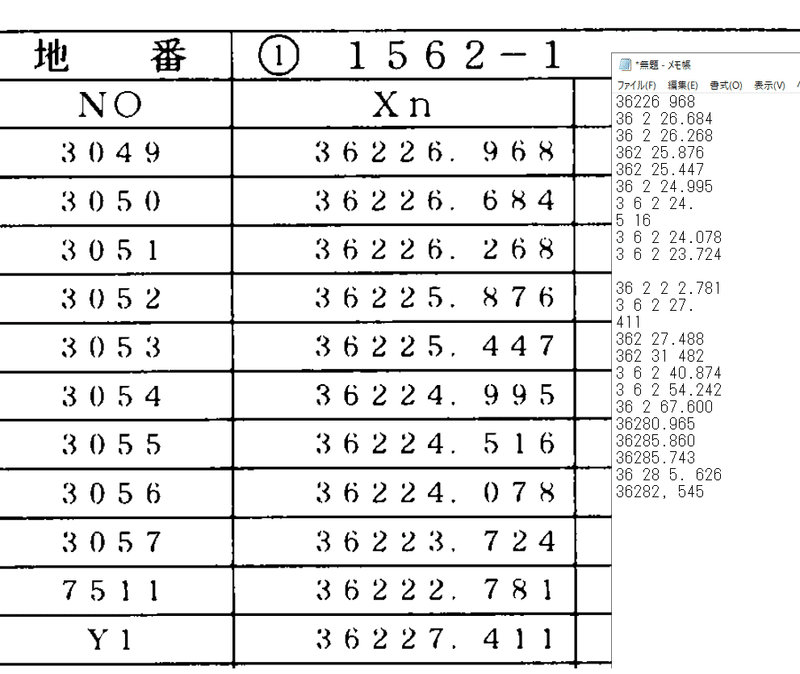
元データの画像が荒いとうまくOCRされないことも多いです。
その場合は、PDFのスナップショットを行う際に、なるべく数字部分のみギリギリを選択するとよくなると思います。
また、一度に選択する範囲を小さめにしてもいいかもしれません。
以下の画像は文字のかすれている座標表のX座標をOCRしたものです。
数字に空白ができたり、小数点が抜けたり「。」になったりはしますが、それを修正する時間を考慮しても手入力よりは早いと思われます。
この記事が気に入ったらサポートをしてみませんか?