
summary(), describe()で統計量を一度に求める

東京大学医学部老年病科の矢可部です。
基礎、臨床研究の統計解析でRを用いています。
学生や研修医の指導に使うという目的もあり、noteに記事を書いています。
今回は、基本的な統計量を一度に求められる、summary(), describe()を紹介します。
サンプルデータ
この記事で扱うデータが入った"Rdata1.xlsx"ファイルは、下からダウンロードできます。なおこれは前回の記事で用いたものと同じなので、すでにダウンロードした方は不要です。
summary関数
Rdata1.xlsxに入っている20名分のデータをRにコピペします。
詳しいやり方を知りたい方は以前の記事をご覧ください。
dat <- read.table(pipe("pbpaste"), sep="\t", header=T) # Macの場合
dat<-read.table("clipboard", sep="\t", header=T) # Windowsの場合
attach(dat)
以前解説したように、データの平均や四分位数はmean(), quantile()関数で求められます。
これらについては、summary()関数を実行すると一度に求めることができます。
# データの基本的な統計量を一度に求める。
summary(dat)
実行すると以下のように表示されます。
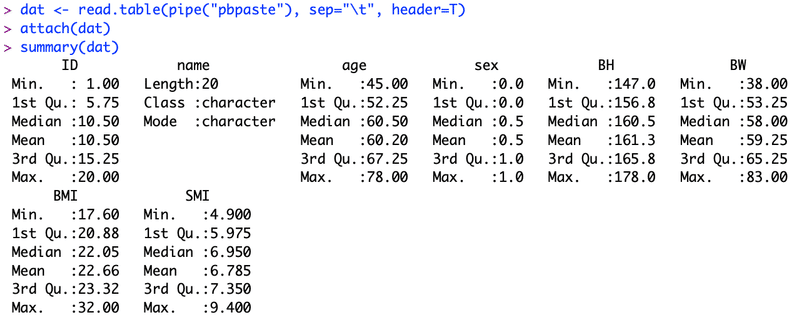
各項目について、最小値、第一四分位数、中央値(=第二四分位数)、平均、第三四分位数、最大値が一度に求められました。
なおIDやsexなど、連続変数でない変数やカテゴリー変数についても連続変数とみなして統計量が表示されますが、意味はありません。
またnameはcharacter(文字型)変数であり、上のように表示されます。
describe関数
psychというパッケージにあるdescribe()でもできます。得られる統計量はこちらの方が多いです。
install.packages("psych") # psychパッケージをインストール(初回のみ)
library(psych) # psych()関数を呼び出す。
その後、datに対してdescribe()を実行します。
# datに対してdescribe関数を実行
describe(dat)
以下のように表示されます。

表示されている略号は以下の通りです(既出のものを含みます)。
vars: その変数が何列目にあるか
n: サンプル数
mean: 平均
sd: 標準偏差
median: 中央値
trimmed: トリム平均
mad: 中央絶対偏差
min: 最小値
max: 最大値
range: レンジ
skew: 歪度
kurtosis: 尖度
se: 標準誤差
summary()では標準偏差は表示されませんでしたが、describe()では表示されます。
他にもいろいろな統計量が表示されますが、ここでは解説を省略します。
基本的な統計量を一度に求められるsummary(), describe()を、ぜひ使ってみてください。
この記事が気に入ったらサポートをしてみませんか?