
【119日目】Django×Tweepy_リツイート以外を保存する

TwitterのデータをAPIで収集していて気が付いたのですが、特定のキーワードで検索した際、リツイートが結構多くてオリジナルツイートが埋もれちゃいがちです。
そのためリツイートを除外する方法を色々と探しました。
まず、今はsearch_30_daysを以下のように使っています。
tweets = tweepy.Cursor(api.search_30_day, label='test1', query='検索ワード' ,fromDate='202203080000').items(10)選択しているプランは無料のSandboxです。
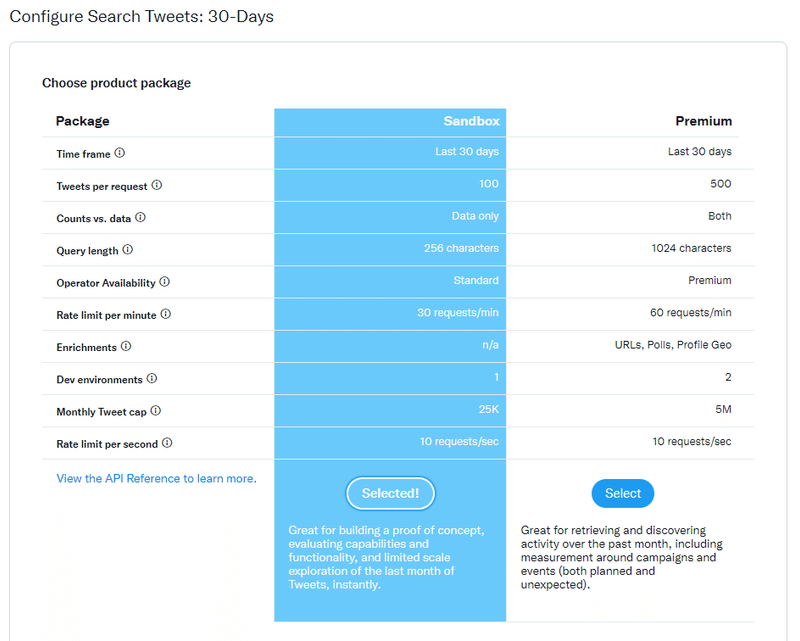
この状態だと、リツイート除外のためにできる手段がかなり限定的だということが分かりました(無料プランだから仕方ない・・・)。
SandboxではなくPremiumであれば、以下の「is:retweet」というオペレーターが使えます。これはリツイートを特定してくれるものです。ただ、Premiumというラベルはありますが、Sandboxというラベルがありません。

ちなみに以前の記事で触れた「point_radius」はSandboxでも使えるオペレーターでした。
point_radiusについてはこちら↓
話をリツイートの除外に戻します。
Premium以上のプランなら「-is:retweet」をqueryに渡せばOKです。
以下のように書きます(試せたわけではないですが)。
tweets = tweepy.Cursor(api.search_30_day, label='test1', query='検索ワード -is:retweet' ,fromDate='202203080000').items(10)このように実際の検索ワードと組み合わせて使う形です。「-」はリツイート「以外」を収集する、という意味です。逆に「-」がないとリツイートだけが集められてきます。
この記述方法は「is:」や「has:」で始まるオペレーター共通のもので、公式サイトには以下のように記載されていました。
NOTE: All is: and has: operators cannot be used as standalone operators when using the Search API, and must be combined with another clause.
For example, @TwitterDev has:links
つまりSearch APIを使う場合、is や hasで始まるオペレーターは単独では使用できず、他の句と組み合わせて使ってください、ということみたいです。
ちなみにsearch_30_dayの詳細説明には、queryについて以下のように説明されていました。
API.search_30_day(label, query, *, tag, fromDate, toDate, maxResults, next)
query –
The equivalent of one premium rule/filter, with up to 1,024 characters (256 with Sandbox dev environments).
This parameter should include ALL portions of the rule/filter, including all operators, and portions of the rule should not be separated into other parameters of the query.
オペレーターをセパレートせずにqueryの中に含めろ、という感じで記載されています。
このように有料版ではリツイートを除外できそうですが、無料版では無理そうでした。そのためAPIで取得してきた後に手動で除いたりフラグを付けたりしたいと思います。
以下のように記述しました。
tweets = tweepy.Cursor(api.search_30_day, label='test1', query=search,fromDate='202203080000').items(num)
tweets = list(tweets)
tweet_data = []
for tweet in tweets:
if not 'RT @' in tweet.text[:4]:
tweet_data.append([tweet.id, tweet.user.id, tweet.user.name, tweet.text, tweet.favorite_count, tweet.retweet_count, tweet.created_at])
リツイートはテキストの冒頭に「RT @」という文字が共通で入っているので、これを検知して除外する形です。
リツイートのデータを後で使いたい場合は、ここで除外するのではなくフラグを立てるような処理をすれば良いと思います。
余談ですが、ここでは丁寧にtweetsを一度リスト化していますが、Cursorメソッドで取得してきたデータの型を確認すると、そのままでもイテラブルです。
tweets = tweepy.Cursor(api.search_30_day, label='test1', query=search,).items(item_num)
type(tweets)[出力結果]
tweepy.cursor.ItemIteratorつまりわざわざリスト化しなくても直接for文に入れて繰り返し処理することも可能です。
ここまでお読みいただきありがとうございました!
参考
この記事が気に入ったらサポートをしてみませんか?