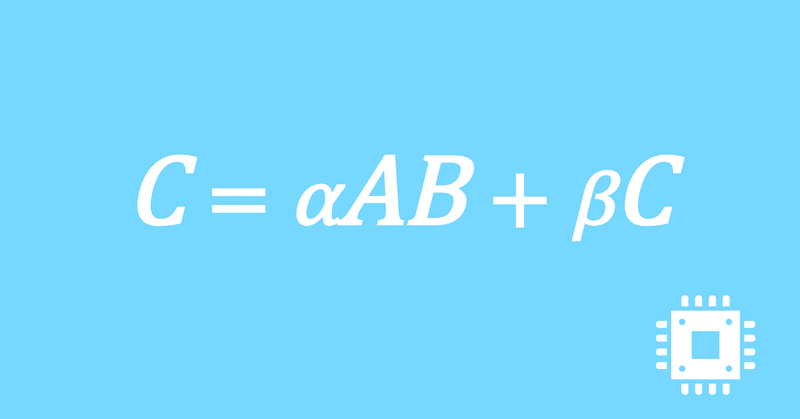
カーネル関数の性能推定と改良|行列積高速化#25

ここまで、行列積の高速化チューニングの手順を書きましたが、サンプルが思ったよりも性能が出ませんでした。そこで、もう少し粘ってチューニングをしていましたが、なんとか理論ピーク性能比率で90%を超えたので、何をやったのか書き残しておこうと思います。
追記
(2020/11/14)下記記事の分割&シリーズ化に伴い、タイトルを変更しました。
カーネル関数の作り直し
サンプルを作成したのち、いろいろ計算速度を測定した結果、結局カーネル関数の実装が遅いのだろうという結論になりました。そこで、アンロール段数を変更したカーネル関数を作り直すことにしました。
手順としては、上記の記事の「アンロール」の節からやり直せば良いだけですが、これはかなり面倒です。面倒なので、試行錯誤の末に辿り着いた考え方を先に示しておきます。
最終的に、カーネル関数の最深部のアンローリングは、次のようなループ構造を考えれば良いことがわかりました。
for( size_t k=0; k<KU; k++ ){
for( size_t j=0; j<NU; j++ ){
for( size_t i=0; i<MU; i++ ){
for( size_t l=0; l<LU; l++ ){
c[i+MU*j] += (*(A2+l+i*LU+k*LU*MU))*(*(B2+l+j*LU+k*LU*NU));
}
}
}
}
A2+=MU*KU*LU;
B2+=KU*LU*NU;ここで、MU、NU、KU、LUは、アンロール段数を定める正数パラメータです。
通常、行列積アルゴリズムは、i,j,kの三重ループで実装されますが、元のkループをkループとlループに分けています。この時、KU*LUがk軸方向のアンロール段数と一致しなければなりません。例えば、k軸方向のアンロール段数=8の場合は、(KU,LU) = (4,2)などとします。
なお、c[]はMU*NUサイズのバッファ配列、A2とB2は行列AとBをシリアライズ・コピーしたバッファ配列です。
制約条件つき最適化問題
このアルゴリズムに対して、パラメータMUxNUxKUxLUを適当に決めて試してみて、高性能が出るパターンを見つければいいのですが、何も指針がないと困ります。いくつか試した結果、次のような制約条件付き最適化問題を解けば良さそうだという仮説にたどり着きました。
Prob.
min f( MU, NU, LU ),
f(MU,NU,LU):=( MU + NU + p(MU,NU,LU) ) / ( MU * NU ),
p(MU,NU,LU):= min(MU,NU)*floor(2/LU,1),
subject to MU * NU * min( LU, 4 )/4 ≦ 12, (制約条件)
MU, NU, LU = 1, 2, 3, ....
目的関数
目的関数f(MU,NU,LU)の分子のMU+NUは、ロード命令の個数です。上記のアルゴリズムの中で、行列AのデータはMU*KU*LU個使用しますが、AVX命令によってYMMレジスタに4個ずつロードするので、行列A のロード命令数はMU*KU*LU/4個になります。同様に、行列Bのロード命令数はNU*KU*LU/4個になるため、全ロード命令数は ( MU + NU )*KU*LU/4個になります。
一方、目的関数f(MU,NU,LU)の分母MU*NUは、FMA(積和)命令の個数です。上記のアルゴリズムで積和計算数を数える(乗算と加算のセットで1と数える)と、FMA命令の個数を知ることができます。実際には、ループ構造から積和計算数はMU*NU*KU*LU個であることは自明です。AVX命令セットでは、4つの積和計算を1命令で実行するので、FMA命令数はMU*NU*KU*LU/4個になります。もし、FMA命令を使わずに乗算と加算を分けるとすると、演算命令数は2*MU*NU*KU*LU/4個になります。
また、関数p(MU,NU,LU)は、置換命令の個数を推定する式になります。置換命令は、ロードに使用したYMMレジスタ本数分(=ロード命令数分)が必要です。すなわち、行列AはMU*KU*LU/4個、行列BはNU*KU*LU/4個の置換が必要になります。ただし、行列A,Bのどちらか一方に適用すれば良いので、少ない方を選ぶとmin(MU,NU)*KU*LU/4個との置換命令が必要になります。また、置換命令の数は、LUの値によっても必要数が変わります。
LU≧4の場合:置換命令不要(そのままFMA計算に使えるため)
LU=2の場合:+VPERMF128命令(上位128bitと下位128bitを入れ換える命令)
LU=1の場合:+VSHUFPD命令(128bit内部の64bit要素を入れ換える命令)
この条件分岐をfloor(2/LU,1)で表現しています。
行列積計算では、アルゴリズムの中で演算(FMA)命令比率が高いほど、高性能化します。なぜなら、近年のCPUではアウトオブオーダー実行が実装されていて、演算命令とロード命令(とその他の命令)は同時実行ができるからです。これにより、演算命令の比率が多いほど、パラレルに実行されるロード命令(とその他の命令)のコストは見えなくなります。そのため、目的関数f(MU,NU,LU)は、下記のように、ロード命令数・転置命令数とFMA命令数の比率で定義しました。
f(MU,NU,LU) = (ロード命令数+転置命令数) ÷ FMA命令数
= {( MU + NU )*KU*LU/4 +p*KU*LU/4} ÷ MU*NU*KU*LU/4
= ( MU + NU + p(MU,NU,LU) ) / ( MU * NU )
p(MU,NU,LU) = min(MU,NU) * floor(2/LU,1)
FMA命令数が多いほど高性能になると予想されるので、目的関数f(MU,NU,LU)を最小化するMUとNUとLUを見つけなさい、という問題設定にすれば良いことになります。
制約条件
制約条件は、CPUの保有するレジスタ数に由来しています。上記の制約条件は「行列Cのデータを保管するレジスタ数は、12本以下であること」という意味になります。
もともとのサンプルプログラムでは、MU=4、NU=4としており、行列Cのデータを保管するレジスタ数は最小限の4本に設定していました。これは、MU*NU = 16個のデータは、4本のYMMレジスタ(4つのデータを保持できる)で保管できるためです。
しかし、レジスタ数を4本に制限すると、ループ最深部で行列Cのデータを集約するために詰め替え処理が必要になり、余計な置換命令を入れざるを得なくなってしまっていました。そこで、データ集約せずに、置換命令を最小限に抑えるため、YMMレジスタにデータを冗長に保管することにしました。
例えば、計算中にYMM1 = [c00(1),c00(2),c00(3),c00(4)]と、4つの部分和c00(1) ~ c00(4)が計算された場合、加算c00(1) + c00(2) + c00(3) + c00(4)はループ最深部では行わず、冗長ですが、そのままYMM1レジスタに保持しておきます。
上記のアルゴリズムで、行列Cの要素はMU*NU個計算されます。冗長性は、アセンブラのアルゴリズムを書いてみると、LU=4の時、1要素を4つの部分要素に分けて保管する必要が出てきます。すなわち、1要素につき1本のYMMレジスタが必要になります。LU=8の場合は、8つの部分要素が計算されますが、加算して1本のYMMレジスタにまとめることができます。そのため、LU>4の場合は4とカウントすればよく、冗長性はmin(LU,4)と表すことができます。したがって、
行列Cのデータ数 = MU * NU * min(LU,4)
保管用レジスタ数 = MU * NU * min(LU,4) / 4
となります。
ところで、x86_64アーキテクチャでは、16本のYMMレジスタを使用できます。しかし、全てのYMMレジスタを保管用にしてしまうと、ロード用や計算用のレジスタが無くなってしまいます。必要なデータを使用直前でロードするとしても、最低4本程度のYMMレジスタは保管以外の用途のために残しておきたいところです。そのため、保管用レジスタの本数上限を12(=16-4)に設定しました。
制約条件:保管用レジスタ数を12本以下に制限する
MU * NU * min(LU,4) / 4 ≦ 12
最適解の推定
手順を紹介した前記事で作成したサンプルは、MU x NU x KU x LU = 4x4x8x1で設計していました。ただ、実際に実装すると置換命令が全体の半分を占めるほど多かったので、行列Aの4要素のロード命令を2要素のブロードキャスト命令×2に変更して、置換命令を半分削減しました。そのため、行列Aのロード命令数は2倍に、置換命令数は1/2なっていました。これを考慮に入れて目的関数と制約条件を計算すると、
オリジナルサンプルコードの場合
目的関数:f(4,4) = ( 2*4 + 4 + 4*2/2 ) / ( 4*4 ) = 16/16 = 1.00
制約条件:MU*NU*min(LU,4)/4 = 4*4*1/4 = 4 ≦ 12
となります。制約条件の値は4で、12以下になっているので、条件を満たしています。目的関数の値は、f=1.00になりました。サンプルコードのカーネル関数自体の理論ピーク性能比率は60%ほどだったので、f=1.00だと60%くらいになるようです。さらに高速化するには、f<1.00になるMU,NU,KU,LUの組み合わせを見つける必要があります。
最適なパラメータの組み合わせをいちいち計算するのは面倒なので、Excelを使って一気に計算させてしまいましょう。ただ、3パラメータを2次元表には表現できないので、LU=1,2,4の場合に分けて計算します。
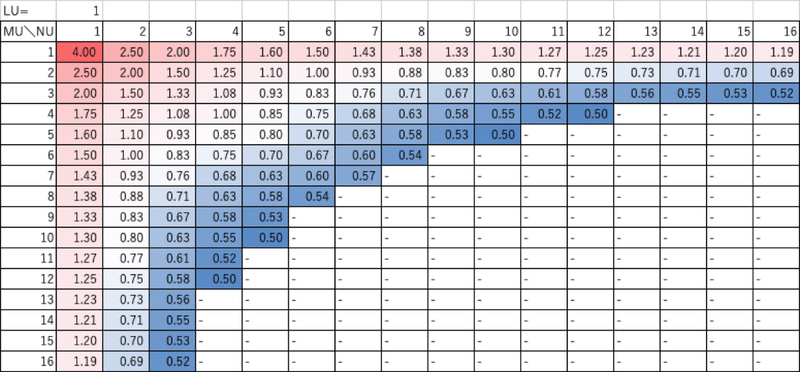
LU=4の場合は、次のようになりました。この場合、(MU,NU)=(4,3)or(3,4)とすると、目的関数f=0.58になり、最も高性能になる可能性があります。ただし、行列Cへの格納のとき、メモリ連続方向であるMUを4の倍数にしておく方が都合がいいです。そのため、MU=4, NU=3を選択した方が良いでしょう。
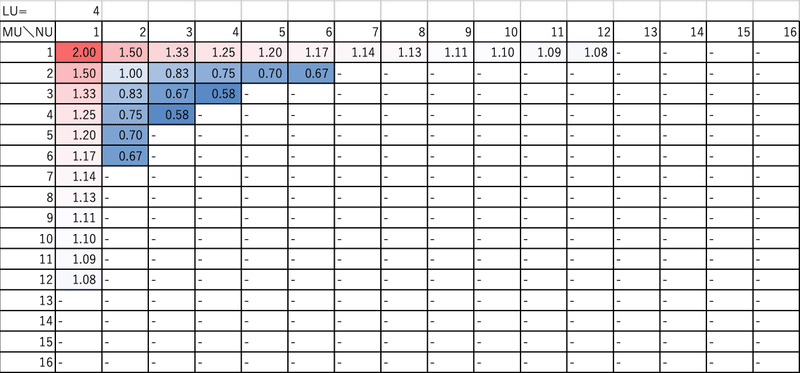
LU=2の場合は、以下のようになりました。この場合、(MU,NU) = (3,8), (4,6), (6,4) or (8,3) では、目的関数f=0.58となっていて、高性能が期待できます。ただし、LU=4の場合と同様の理由で、(MU,NU) = (4,6) or (8,3)を選ぶ方が好都合になります。
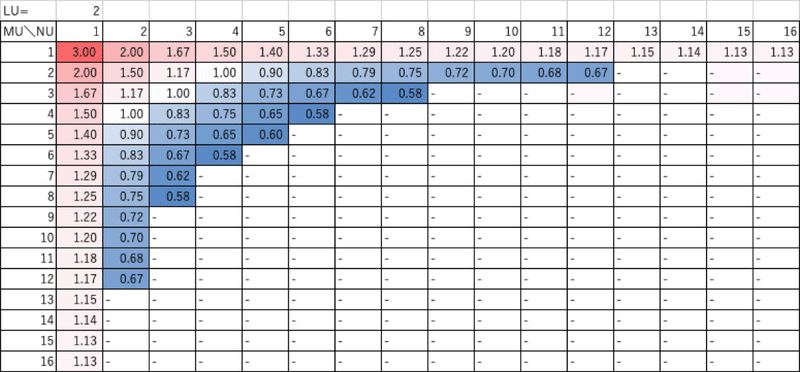
LU=1の場合は、以下のようになりました。この場合は、(MU,NU) = (12,4), (10,5), (5,10) or (4,12)とすると、目的関数f=0.50となって、上記も含めて最も高性能になる可能性があります。ただし、5の倍数は扱いにくいので、(MU,NU) = (12,4) or (4,12)の方が好都合だと考えられます。
ということで、最も高性能になる可能性が高いのは、MU x NU x KU x LU = 12 x 4 x KU x 1 の場合または4 x 12 x KU x 1 の場合と分かりました。LU=2の場合を中心に考えていたため、このパラメータ設定は試していませんでした。実際に、12 x 4 x KU x 1または4 x 12 x KU x 1の設定で実現可能かどうかは、具体的なコードを書いてみる必要があります。直感だと、計算用レジスタが不足する気がします。
追記
(2020/11/14)4 x 12 x 8 x 1の場合を実装し、測定結果を追加しました
実際のカーネル性能
今回の性能推定式を考案するまでに、3つのケースについて実際にコーディングとチューニングを行ったので、元のサンプルコードと合わせて比較してみましょう。
理論ピーク性能に対する比率では、次のようになりました。
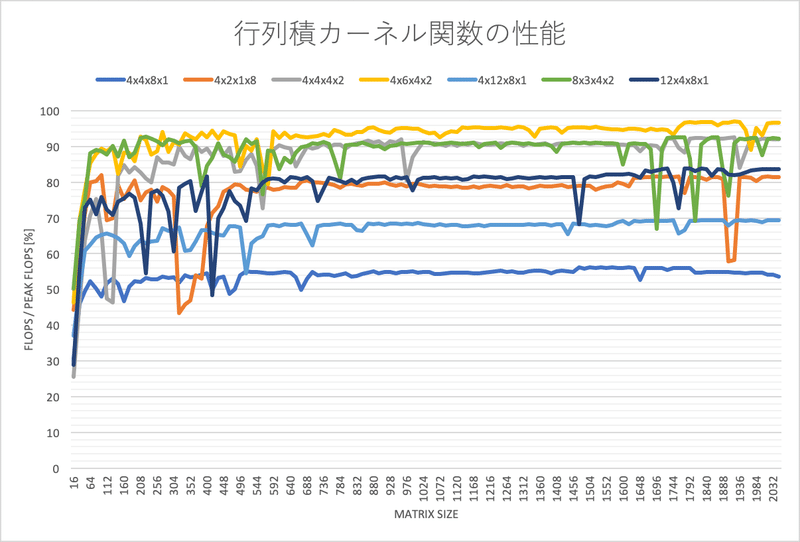
ここで、青線のMUxNUxKUxLU=4x4x8x1の場合が、オリジナルのサンプルコードの性能になります。性能推定式の結果f=1.00の場合に相当し、実測値では理論ピーク性能比率56%程度になっています。同様に、オレンジ線4x2x1x8の場合はf=0.75で性能比率82%、灰色線4x4x4x2の場合はf=0.75で92%、黄色線4x6x4x2の場合はf=0.58で96%になっています。
追記
(2020/11/14)4x12x8x1の場合は、理論ピーク性能比率68%でした。
(2020/11/23)8x3x4x2は93%、12x4x8x1は83%ほどでした。
結果として、推定値が小さいケースを選択すれば、確かに高性能なカーネル関数になることが分かります。ただし、推定値が同じ推定結果でも実測値は異なる場合があるので、完全には推定し切れていないようです。
同じ推定結果の4x2x1x8と4x4x4x2の場合では、前者がロード命令数6・置換命令0・FMA命令8なのに対し、後者はロード命令8・置換命令4・FMA命令16になっています。これは、前者のロード命令2つが後者では置換命令2つに置き換わったことを意味しています。したがって、ロード命令比率が少ない方がより高速になることを表しています。あるいは、推定式に置換命令コストが相対的に小さくなるように、重みづけが必要と考えることもできます。
まとめ
行列積カーネル関数の改良を行うために性能推定公式を考案し、性能推定問題を制約条件つき最適化問題として定式化しました。この問題を解き、4つのケースで実測を行い、推定値と実測性能との比較を行いました。その結果、推定式の改良が必要なものの、推定値にしたがって実装ケースを選択すれば、高い性能の行列積カーネル関数を作成できることが分かりました。結果として、理論ピーク性能比率96%の性能が出る行列積カーネル関数が実現できました。
今後の課題
・推定式の重み付け
・推定結果が最小になる12x4xKUx1の場合の実装と実測
追記
(2020/11/14)4x12x8x1の場合を実装しましたが、性能は低下しました。
(2020/11/23)8x3x4x2は2番目に良い性能でしたが、12x4x8x1は性能低下しました。
この他にも、キャッシュブロッキングサイズの変更やマルチコア化、行列転置コピーのシーケンシャルアクセス化などを行っているのですが、文章が長くなったので次回以降に回したいと思います。
次の記事
ソースコード
この記事が気に入ったらサポートをしてみませんか?