
Pythonの基本⑤ ライブラリ

ライブラリとは?
Pythonファイル(.py)は、他のPythonプログラムからimportして使用することが出来ます。このPythonファイルはモジュールと呼ばれ、モジュールを集めたものをパッケージ、さらにパッケージをまとめたものをライブラリと呼びます。
ライブラリには、Excelのようにデータをテーブル(表)として扱うことが出来るpandas、データを可視化(グラフ化)することができるmatplotlibやaltair、webスクレイピングで使用するBeautifulSoupなどがあります。
もちろん、自分で作成したpythonファイルをimportして利用することが出来ます。
他のファイルから機能を借りることが出来るので、pythonのコードはシンプルに記述することが出来ます。
ライブラリをimportしてみよう!
ライブラリには標準ライブラリと外部ライブラリがあります。Pythonに付随する標準ライブラリは、importすればすぐに使用できます。外部ライブラリは、importの前にインストールやダウンロードする必要があります。
Google Colabの環境では、外部ライブラリは「! pip install *****」というように記述しインストールします。
例えば、pandasの場合は以下のようなコードとなります。
! pip install pandasこれで、pandasが使用できるようになります。
import pandas as pd「as pd」と記述していますが、コードの中でpandasを"pd"として略すことを宣言しています。無くても良いですし、"pd"以外の任意の文字列にしても大丈夫です。
ライブラリを使用してみよう!
先ほどインストール・importしたpandasは、Excelのようにテーブル(表)を扱うことができるライブラリで、よく使用します。pandasではExcelでいう表形式のデータのことをデータフレーム(df)と呼びます。
Excelファイル(.xlsxや.csvなど)を読み込んで、加工することも出来ます。さらに、加工したデータを可視化ライブラリでグラフ化することが出来ます。毎回同じ加工をするのであれば、この過程は自動化することもできるのでExcelの元データを更新するだけで自動で可視化までできます。また、グラフ化もExcelでは難しい(できないことは無いですが…)高度なグラフを描画することが出来ます。
詳細は、次回以降の投稿で書いていきます。
今回は、練習としてサンプルデータをデータフレームとして読み込んでみましょう。
サンプルデータは、厚労省が出している新型コロナウイルス感染症情報のオープンデータを使用します。以下よりダウンロードしてください。
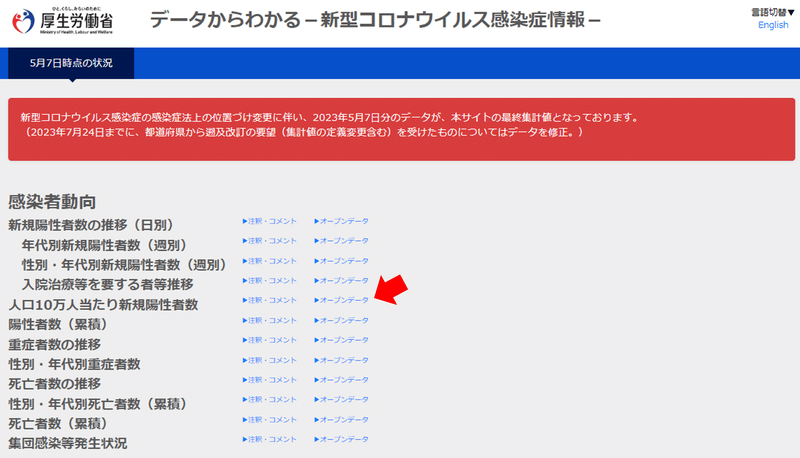
人口10万人当たりの新規陽性者数のオープンデータを使用します。ダウンロード出来たら、Google Colabの左端のフォルダアイコンをクリックします(①)。②のエリアにダウンロードしたcsvファイルをドラッグします。ファイル名の上で右クリックし(③)、「パスをコピー」をクリックします(④)。
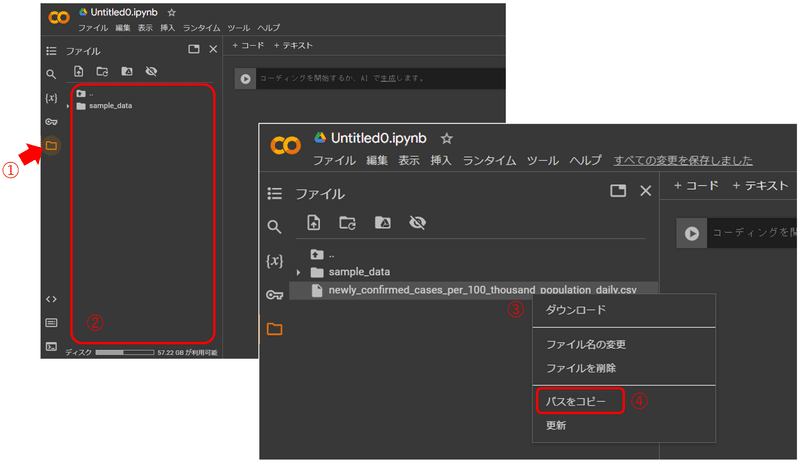
read_csvメソッドを使用すると、引数に指定したパス(=ファイルまでのアドレス)のファイルを読み込むことが出来ます。read_csv()はpandas(先ほどpdと省略すると宣言)のメソッドなので、pd.read_csv()と表記し、引数に④でコピーしたパスを貼り付けます。これをdfという変数に格納します。
df = pd.read_csv('/content/newly_confirmed_cases_per_100_thousand_population_daily.csv')dfの中にcsvファイルの中身が格納されているか確認してみましょう。
df.head() →データフレームの上から5行を表示
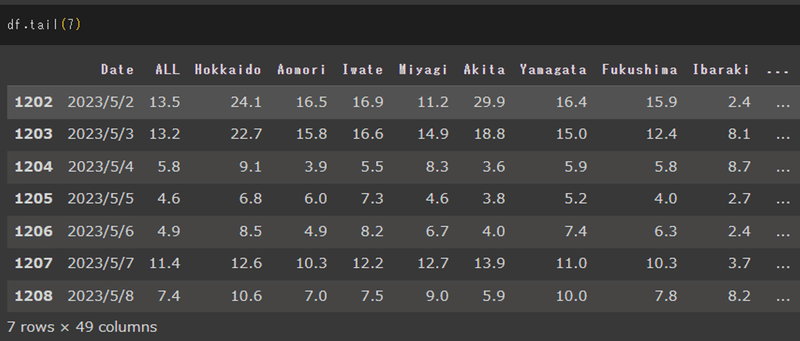
df.tail() →データフレームの下から5行を表示
※ともに引数に数字を指定すると、任意の行数を表示することが出来ます。
今回はライブラリのインスト―ル、importについて説明しました。ライブラリを使用することで出来ることが一気に拡がります。次回以降は、よく使うpandasなどのライブラリの具体的な使用方法をご紹介していきます。
この記事が気に入ったらサポートをしてみませんか?