
便利ライブラリ seaborn② Pairplot・Jointplotの作成

seabornの2回目の投稿はPairplotとJointplotについてです。データ全体もしくは個々のデータがどのような分布をしているのかイメージしやすいのでお気に入りの可視化方法です。
データの準備
今回はseabornで用意されているサンプルデータセットを使用します。
import seaborn as sns
mpg = sns.load_dataset("mpg")mpg.head()
mpgというデータセットは、以下の項目が含まれたDataFrameになっているようです。
'mpg'(燃費 miles per gallon)、 'cylinders'(シリンダー)、 'displacement'(排気量)、 'horsepower'(馬力)、 'weight'(重量)、 'acceleration'(加速)、 'model_year'(年式)、 'origin'(生産国)、 'name'(車種)
Altair①基本編で使用したデータセットと同じサンプルデータのようです。この投稿では、プロットに重み付けができるBubble Plotを例にAltairの使い方を紹介しています。
Pairplot
2つのデータをx軸、y軸に設定して相関関係を確認したくなることがよくあると思います。データがたくさんあればあるほど、そこから2項目選ぶ組み合わせは増えていきます。1つ1つ確認していくのは結構面倒ですよね。そんな場合に、Pairpltを使用すれば網羅的に全組合せの散布図を作成できます。
pairplot()に以下の引数を渡すだけで簡単に作成できます。
data: DataFrame
hue: プロットを色分けする場合、色分けしたい列名(省略可)
sns.pairplot(mpg, hue="model_year")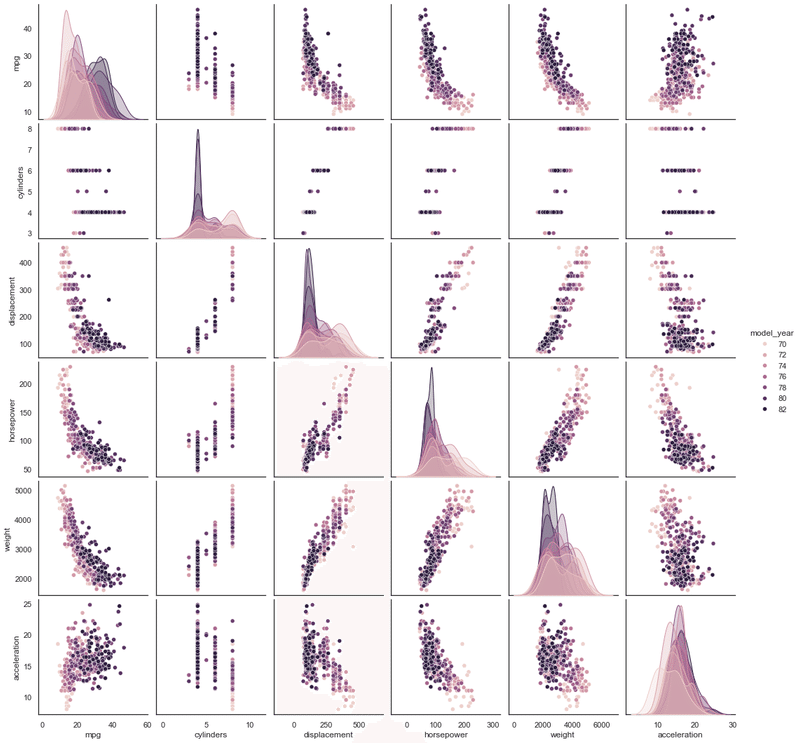
hueに年式を渡し、pairplotを作成しました。数字のデータが入っている7項目のうち、年式以外の6項目が総当たりで散布図になっています。散布図は年式別に色分けされています。また、対角(x軸、y軸が同じ項目)には、データの分布が示されています。どの項目が相関が強いのか確認したいときに便利です。
試しにhueを変えてみましょう。
sns.pairplot(mpg, hue="origin")
今度は、年式も含めた7項目の総当たりの散布図ができました。
Jointplot
Pairplotではデータ全体を眺めることができましたが、Jointplotは個々の組合せについて分布をみることができる方法です。jointplot()の引数には以下のパラメータを渡します。
data: DataFrame
x/y: x軸/y軸に設定する項目名
xlim/ylim: 軸範囲の設定 (最小値, 最大値)
color: 色
hue: プロットの色分けをする場合に設定する項目名
height: 図のサイズ(正方形になる)
kind: プロットの種類(“scatter” | “kde” | “hist” | “hex” | “reg” | “resid”)
sns.jointplot(x="horsepower", y="mpg", data=mpg,
kind="reg",
xlim=(0, 250), ylim=(0, 60),
color="m",
height=7
)
散布図と各軸のデータ分布を同時に示すグラフを描くことができました。
kindを"hist"や"hex"に変えると点の集合(密度)を色の濃さで表現できます。

また、kindを"kde"に変えると等高線で示すことができます。

Pairplotと同様にhueを設定することで色分けすることも出来ます。
sns.jointplot(x="horsepower", y="mpg", data=mpg,
xlim=(0, 250), ylim=(0, 60),
hue="origin",
height=7
)
散布図だけではなく、分布を示すグラフも色分けされるので分かりやすいですね。日本車はパワーは弱いけど燃費が良く、アメ車はパワーがあるけど燃費が悪い傾向があるのが一目瞭然です。
おまけ(アメ車と燃費)
mpg['model_year'].unique()> array([70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82], dtype=int64)
このDataFrameには1970年から1982年のデータが含まれているようです。アメ車は燃費悪いと書いてみたものの、きっと技術の進歩とともに燃費は良くなっているハズと仮説を立てた(ただ気になっただけ笑)ので確認してみましょう。
各年ごと色分けすると見にくくなるので、3つの年代に分けます。ilocで年式データを取り出し、if文で年代を判定し、年式のデータを年代で上書きしています。
mpg_usa = mpg.query('origin == "usa"')
for i in range(len(mpg_usa)):
if mpg_usa.iloc[i, 6] in [70, 71, 72, 73, 74]:
mpg_usa.iloc[i, 6] = '1970-1974'
elif mpg_usa.iloc[i, 6] in [75, 76, 77, 78, 79]:
mpg_usa.iloc[i, 6] = '1975-1979'
else:
mpg_usa.iloc[i, 6] = '1980-1982'
年式の列が年代に置き換わりました。あとは、これまでと同じようにJointplotを作成します。
sns.jointplot(x="horsepower", y="mpg", data=mpg_usa,
xlim=(40, 250), ylim=(5, 50),
hue="model_year",
height=7
)
経年的に燃費は改善していることが分かります。馬力も経年的に落ちているものの、1970年代後半(オレンジ)から1980年代前半(緑)にかけては馬力の低下は小さいながらも燃費向上が図られているように見えます。
まぁ、サンプルのデータセットなのでデータが正しいかとかサンプリングの偏りの有無などちゃんと確認しなければいけないことはありそうですけどね。
データの可視化はやっぱり大事ですね。特に車に興味があるわけではないですが、可視化してみると気になることが出てきますし、見えてきます!
この記事が気に入ったらサポートをしてみませんか?